
前言
承接上一步的语音合成的最后那步的操作。也就是搭建了虚拟环境,成功使用speaking.py合成语音后。
现在目标是再次实现语音唤醒,语音识别,接入chat等等的功能,然后拍下视频。
语音唤醒
- 先找到麦克风和设备号。
arecord -l
1
2
3
4
5
pi@raspberrypi:~ $ arecord -l
**** List of CAPTURE Hardware Devices ****
card 2: Device [USB PnP Sound Device], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0
- 虽然本教程不需要,但也应该检索音频输出的设备和卡号。
aplay -l
1
2
3
4
5
6
7
8
9
10
11
12
13
14
pi@raspberrypi:~ $ aplay -l
**** List of PLAYBACK Hardware Devices ****
card 0: b1 [bcm2835 HDMI 1], device 0: bcm2835 HDMI 1 [bcm2835 HDMI 1]
Subdevices: 4/4
Subdevice #0: subdevice #0
Subdevice #1: subdevice #1
Subdevice #2: subdevice #2
Subdevice #3: subdevice #3
card 1: Headphones [bcm2835 Headphones], device 0: bcm2835 Headphones [bcm2835 Headphones]
Subdevices: 4/4
Subdevice #0: subdevice #0
Subdevice #1: subdevice #1
Subdevice #2: subdevice #2
Subdevice #3: subdevice #3
- 手上有了所有的值之后,就可以去修改ALSA配置文件了。在这个文件中,需要输入以下几行。这些行将设置音频驱动程序,并帮助它知道应该与哪些设备进行交互。
nano /home/pi/.asoundrc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
pcm.!default {
type asym
capture.pcm "mic"
playback.pcm "speaker"
}
pcm.mic {
type plug
slave {
pcm "hw:2,0"
}
}
pcm.speaker {
type plug
slave {
pcm "hw:1,0"
}
}
- 现在,通过录音来测试麦克风,在你的Raspberry Pi上运行以下命令。
arecord –format=S16_LE –duration=5 –rate=16000 –file-type=raw out.raw
- 录制完成后,现在可以运行下面的命令来读取原始输出文件,并将其回放给扬声器。
aplay –format=S16_LE –rate=16000 out.raw
- 如果你发现播放音量或录音音量过高或过低,那么你可以运行以下命令启动混音器。
alsamixer
按住 fn键+F6键,切换声卡,选择你使用的扬声器,我这里是插耳机,也就是Headphones这个,选择以后,滚动滑轮即可调整声音大小。
配置相应的库
sudo apt install python3 python3-pip python3-all-dev python3-pyaudio portaudio19-dev libsndfile1(成功)
sudo pip3 install pvporcupine(很慢,要注意安装到了哪里,这个并不是安装在虚拟环境里面的!)
pip3 install PyAudio(第三次成功,因该是源的问题)
语音识别
- 安装环境
pip3 install pvcobra(成功)
百度的语音识别,安装了他的SDK。
安装api所需的库
https://ai.baidu.com/sdk#asr
下载包到树莓派中,然后进入解压好的文件夹,输入
pip3 install .
pip3 install chardet
1
2
3
4
5
6
7
8
9
10
11
12
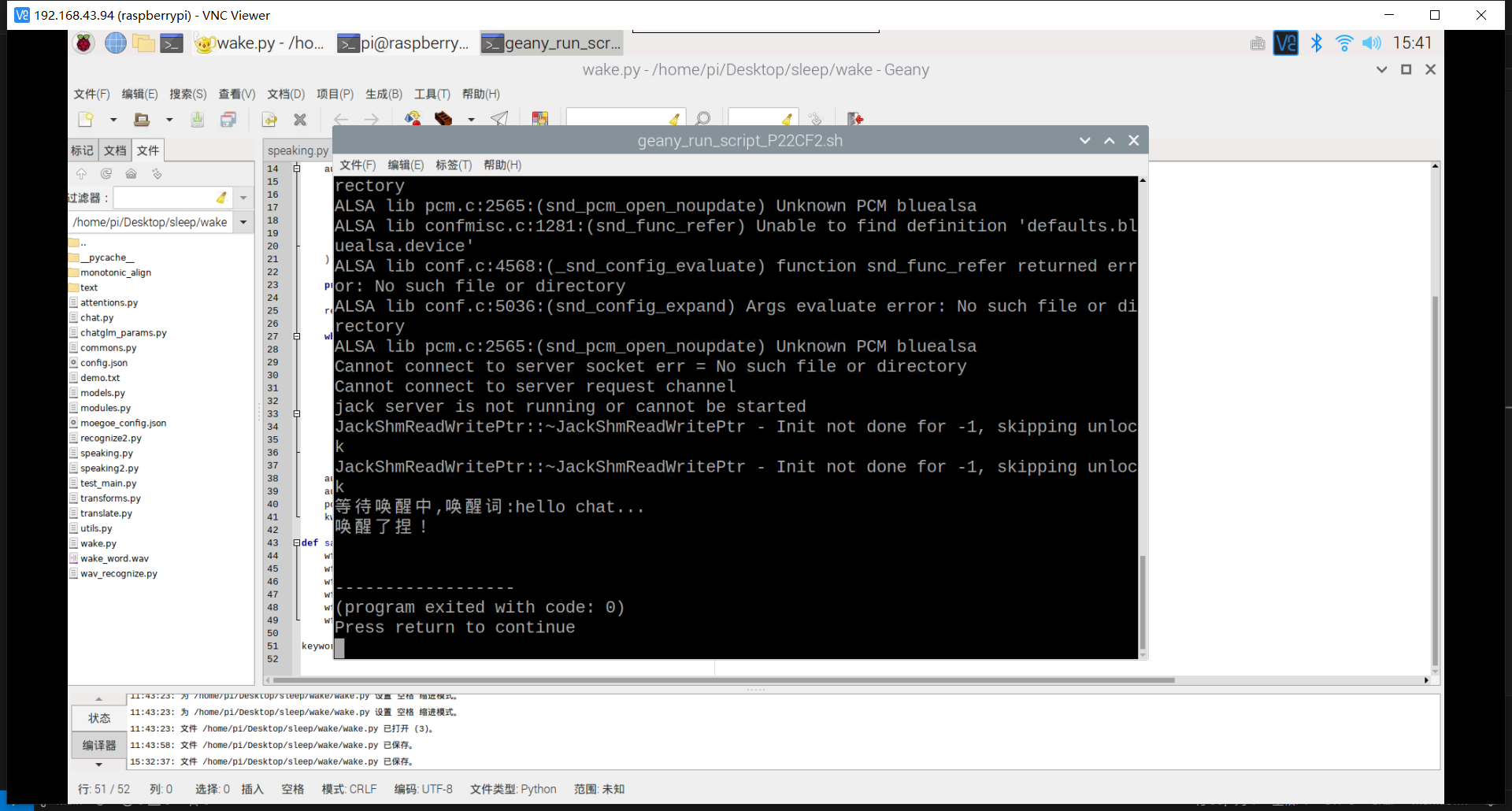
开始录音...
0.018264278769493103 0
Traceback (most recent call last):
File "wav_recognize.py", line 123, in <module>
listen()
File "wav_recognize.py", line 108, in listen
filepath = sound_record()
File "wav_recognize.py", line 46, in sound_record
pcm = audio_stream.read(porcupine.frame_length)
File "/home/pi/Desktop/sleep/lib/python3.7/site-packages/pyaudio/__init__.py", line 571, in read
exception_on_overflow)
OSError: [Errno -9981] Input overflowed
很眼熟的报错,但我之前没有记录这个错误
解决(使用1和3就成功了):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
1. Error: [Errno -9981] Input overflowed,表明输入音频流溢出,即尝试读取的音频数据量超过了当前可用的数据。这可能是因为你的代码以比音频捕获速率更快的速度读取音频数据。
调整每缓冲帧数:修改audio_stream.open调用中的frames_per_buffer参数。较小的值可能有助于防止溢出。尝试不同的值,找到响应性和避免溢出之间的平衡。
audio_stream = kws_audio.open(
rate=porcupine.sample_rate,
channels=1,
format=pyaudio.paInt16,
input=True,
frames_per_buffer=1024, # 调整此值
input_device_index=None,
)
2.使用非阻塞模式:尝试在读取音频数据时使用非阻塞模式:
while True:
try:
pcm = audio_stream.read(porcupine.frame_length, exception_on_overflow=False)
if pcm:
_pcm = struct.unpack_from("h" * porcupine.frame_length, pcm)
is_voiced = cobra.process(_pcm)
print(is_voiced, silence_count)
silence_count = 0 if is_voiced > 0.5 else silence_count + 1
if silence_count <= 100:
if silence_count < 70:
recording.extend(_pcm)
else:
break
except IOError as e:
# 处理 IOError,例如打印异常
print(f"Error reading audio: {e}")
3.调整休眠时长:检查你的循环中的休眠时长,确保它适当。太长的休眠可能会导致数据积压。
time.sleep(0.1) # 调整休眠时长
chat
import zhipuai
语音合成,在树莓派语音合成那一片,(836行那里)在树莓派中配置虚拟环境virtualenv
参照https://blog.csdn.net/qq_36622589/article/details/121941036(成功) 安装torch torchvision
树莓派上合成的语音,用pygame播放不了,说是格式不对,但传到电脑用pygame播放却可以,电脑上合成的语音,可以播放但用树莓派上的pygame却不能够播放。
挺烦的,当初都能做出来,现在却卡住了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import pygame
import wave
import pyaudio
#推荐用,好
def play_audio(audio_file_name):
# 初始化pygame
pygame.init()
# 设置音频文件
pygame.mixer.music.load(audio_file_name)
# 播放音频
pygame.mixer.music.play()
# 等待音频播放完毕
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
# 退出pygame
pygame.quit()
#不推荐,差
def play_audio2():
chunk = 1024
wf = wave.open(r"/home/pi/Desktop/sleep/file/music/music1.wav", 'rb')
p = pyaudio.PyAudio()
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()), channels=wf.getnchannels(),
rate=wf.getframerate(), output=True)
data = wf.readframes(chunk) # 读取数据
print(data)
while data != b'': # 播放
stream.write(data)
data = wf.readframes(chunk)
print('while循环中!')
print(data)
stream.stop_stream() # 停止数据流
stream.close()
p.terminate() # 关闭 PyAudio
接连尝试了多个播放方法后,发现效果都不佳,最终尝试改变wav的格式,最后成功播放合成的语音。
1
2
3
4
5
6
Traceback (most recent call last):
File "musicplay.py", line 77, in <module>
play_audio('/home/pi/Desktop/sleep/file/music/music3.wav')
File "musicplay.py", line 9, in play_audio
pygame.mixer.music.load(audio_file_name)
pygame.error: Unknown WAVE data format
报错的原因:使用pygame播放,结果wave格式未知
我以为整个文件都已经偏离了wave的范围
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
pygame 2.0.0 (SDL 2.0.9, python 3.7.3)
Hello from the pygame community. https://www.pygame.org/contribute.html
Traceback (most recent call last):
File "musicplay.py", line 41, in <module>
play_audio2()
File "musicplay.py", line 24, in play_audio2
wf = wave.open(r"/home/pi/Desktop/sleep/file/music/music3.wav", 'rb')
File "/usr/lib/python3.7/wave.py", line 510, in open
return Wave_read(f)
File "/usr/lib/python3.7/wave.py", line 164, in __init__
self.initfp(f)
File "/usr/lib/python3.7/wave.py", line 144, in initfp
self._read_fmt_chunk(chunk)
File "/usr/lib/python3.7/wave.py", line 269, in _read_fmt_chunk
raise Error('unknown format: %r' % (wFormatTag,))
wave.Error: unknown format: 3
然后使用pyaudio播放,错误提示表明 wave 模块在处理音频文件时遇到了未知的格式码 3。通常来说,WAV 文件的格式码为 1,表示 PCM 格式,而其他格式码则较为少见。
1
2
3
4
5
6
7
8
9
10
11
12
13
gpt建议:
检查文件格式:
确保 /home/pi/Desktop/sleep/file/music/music3.wav 文件是一个有效的 WAV 文件。你可以使用其他工具或库来检查文件格式,确保它是一个正确格式的 WAV 文件。
尝试其他 WAV 文件:
使用另一个 WAV 文件测试脚本,最好是一个你知道是 PCM 格式(格式码 1)的文件。这可以帮助确定问题是特定于文件还是更普遍的问题。
检查 WAV 文件属性:
使用工具或库检查有问题的 WAV 文件的属性,例如采样宽度、通道数和采样率。确保这些属性与 PyAudio 的期望相符。
转换文件格式:
如果文件格式有问题,考虑将其转换为标准的 PCM WAV 格式。你可以使用像 Audacity 这样的工具或 Pydub 这样的库来进行转换。
我意识到可以通过转换文件格式来解决问题
于是乎查看wav文件的格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
def check_audio(file_path):
with wave.open(file_path, 'rb') as wf:
print("采样宽度:", wf.getsampwidth())
print("通道数:", wf.getnchannels())
print("帧速率:", wf.getframerate())
check_audio("/home/pi/Desktop/sleep/file/music/music1.wav")#能正常播放
check_audio("/home/pi/Desktop/sleep/file/music/music3.wav")#不能正常播放
结果:
采样宽度: 2
通道数: 2
帧速率: 22050
Traceback (most recent call last):
File "musicplay.py", line 60, in <module>
check_audio("/home/pi/Desktop/sleep/file/music/music3.wav")
File "musicplay.py", line 54, in check_audio
with wave.open(file_path, 'rb') as wf:
File "/usr/lib/python3.7/wave.py", line 510, in open
return Wave_read(f)
File "/usr/lib/python3.7/wave.py", line 164, in __init__
self.initfp(f)
File "/usr/lib/python3.7/wave.py", line 144, in initfp
self._read_fmt_chunk(chunk)
File "/usr/lib/python3.7/wave.py", line 269, in _read_fmt_chunk
raise Error('unknown format: %r' % (wFormatTag,))
wave.Error: unknown format: 3
转换格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from pydub import AudioSegment#安装:pip3 install pydub
def convert_audio_format(input_file, output_file, sample_width, channels):
audio = AudioSegment.from_file(input_file)
audio = audio.set_sample_width(sample_width)
audio = audio.set_channels(channels)
audio.export(output_file, format="wav")
# 替换文件路径和参数
input_file_path = "/home/pi/Desktop/sleep/file/music/music3.wav"
output_file_path = "/home/pi/Desktop/sleep/file/music/music3_converted.wav"
sample_width = 2 # 与 music1.wav 相同的采样宽度
channels = 2 # 与 music1.wav 相同的通道数
convert_audio_format(input_file_path, output_file_path, sample_width, channels)
check_audio(output_file_path)
查看结果
1
2
3
4
5
6
采样宽度: 2
通道数: 2
帧速率: 22050
采样宽度: 2
通道数: 2
帧速率: 22050
结果也可以播放。语音合成也就到此结束了,也就是多加了一个格式转化