
树莓派连接
….略
树莓派安装python3.10.7
安装编译Python需要用到的环境
sudo apt install -y build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libsqlite3-dev libreadline-dev libffi-dev curl libbz2-dev
下载 wget https://www.python.org/ftp/python/3.10.7/Python-3.10.7.tgz
解压并编译源代码
1
2
3
4
tar -xf Python-3.10.0.tar.xz
cd Python-3.10.0
./configure --enable-optimizations
make -j4
make的时间是很久的,估计超过15分钟了
安装Python
sudo make altinstall
使用altinstall而不是install命令是为了避免覆盖默认的Python版本。这样,我们可以同时保留旧版本和新版本的Python。
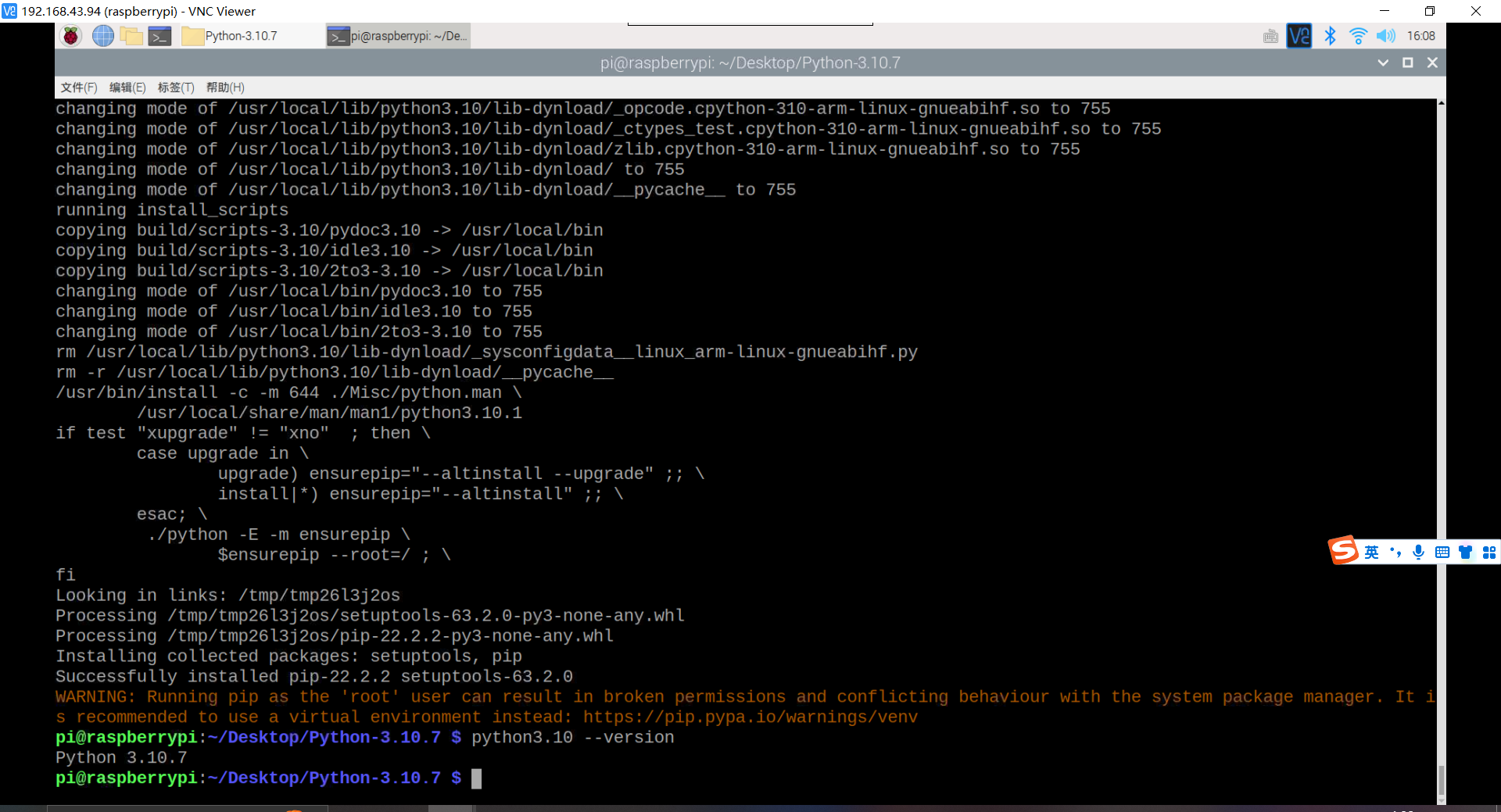
验证安装
python3.10 –version
做软链接:
sudo ln -s /usr/local/lib/python3.10 /usr/lib/python3
sudo ln -s /usr/local/lib/python3.10/site-packages /usr/lib/python3/dist-packages
sudo ln -s /usr/local/bin/python3.10 /usr/bin/python3
配置Geany编译器的python版本
在ubuntu下配置Geany,使其使用Python3
1
2
3
4
5
6
7
8
9
10
参考文献:Python编程:从入门到实践/(美)Eric Matths 著
geany是一款文本编辑器,安装较简单。笔者使用geany作为python的其中一款编辑器使用。
笔者安装的是miniconda,其中包含python2和python3两个版本,为了使geany编译时使用python3,需要对geany进行配置。
环境:
ubuntu
miniconda2
python 3.6.10
geany
正文: geany上部工具栏中点击:生成->设置生成命令(s) 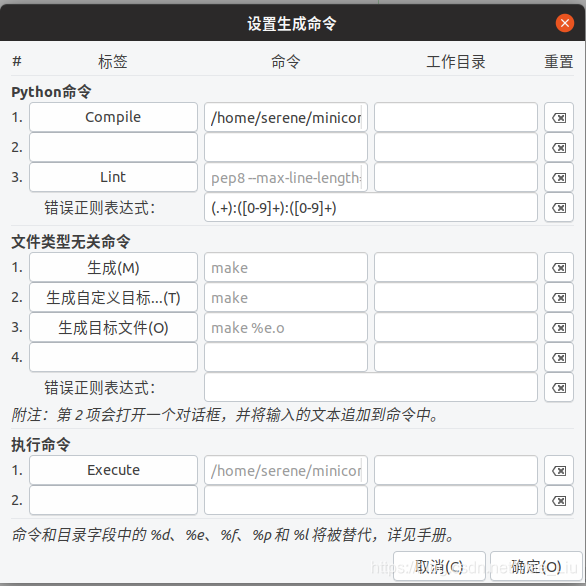
接下来需要修改”Python命令”下的Compile和执行命令下的Execute。 Compile->
python3的路径/python3 -m py_compile “%f”
Execute
python3的路径/python3 “%f”
查询python安装路径的方法参考:https://blog.csdn.net/Mae_Liu/article/details/105888637
———————————————— 版权声明:本文为CSDN博主「Mae_Liu」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/Mae_Liu/article/details/105888721
树莓派语音识别,详细步骤安装和配置Porcupine检测唤醒词
为Porcupine准备Raspberry Pi的音频配置
- 先找到麦克风和设备号。
arecord -l
从这个命令中,你会得到一个响应,就像下面所说的那样。记下你的麦克风的卡号和设备号。
1
2
3
4
5
pi@raspberrypi:~ $ arecord -l
**** List of CAPTURE Hardware Devices ****
card 2: Device [USB PnP Sound Device], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0
- 虽然本教程不需要,但也应该检索音频输出的设备和卡号。
要检索音频输出的这些数字,请输入以下命令。
aplay -l
以下是该命令的输出示例。记下你的卡号和设备号,以获得你想要的输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
pi@raspberrypi:~ $ aplay -l
**** List of PLAYBACK Hardware Devices ****
card 0: b1 [bcm2835 HDMI 1], device 0: bcm2835 HDMI 1 [bcm2835 HDMI 1]
Subdevices: 4/4
Subdevice #0: subdevice #0
Subdevice #1: subdevice #1
Subdevice #2: subdevice #2
Subdevice #3: subdevice #3
card 1: Headphones [bcm2835 Headphones], device 0: bcm2835 Headphones [bcm2835 Headphones]
Subdevices: 4/4
Subdevice #0: subdevice #0
Subdevice #1: subdevice #1
Subdevice #2: subdevice #2
Subdevice #3: subdevice #3
请注意,树莓派的3.5mm接口会被标为模拟、bcm2835 ALSA或bcm385耳机。HDMI输出应识别为bcm2835 IEC958/HDMI。
- 手上有了所有的值之后,就可以去修改ALSA配置文件了。
运行以下命令开始在Pi用户的主目录下创建.asoundrc文件。
nano /home/pi/.asoundrc
在这个文件中,需要输入以下几行。这些行将设置音频驱动程序,并帮助它知道应该与哪些设备进行交互。
pcm.!default { type asym capture.pcm “mic” playback.pcm “speaker” } pcm.mic { type plug slave { pcm “hw:2,0” } } pcm.speaker { type plug slave { pcm “hw:1,0” } }
这段配置代码是一个ALSA (Advanced Linux Sound Architecture) 配置文件,用于定义音频输入和输出设备。它描述了音频设备的配置,以便指定默认的音频输入(mic - 麦克风)和音频输出(speaker - 扬声器)设备。
让我解释这个配置文件中的每个部分:
pcm.!default: 这是一个ALSA配置的默认部分。它指定了默认的音频输入和输出设备。在这个配置中,capture.pcm 被设置为 “mic”,而 playback.pcm 被设置为 “speaker”。这意味着系统将使用名为 “mic” 的PCM配置作为默认音频输入设备,使用名为 “speaker” 的PCM配置作为默认音频输出设备。
pcm.mic: 这是定义音频输入(麦克风)设备的部分。它使用 type plug 插件来引用另一个PCM配置,该PCM配置由 slave 区块中的 pcm 参数指定。
pcm.speaker: 这是定义音频输出(扬声器)设备的部分,与 pcm.mic 部分类似。它也使用 type plug 插件,并引用另一个PCM配置,由 slave 区块中的 pcm 参数指定。同样,您需要将
这种配置允许您为不同的应用程序或音频场景指定不同的音频输入和输出设备。您可以根据需要自定义 mic 和 speaker 部分,以便将其配置为您系统上的实际音频设备。如果您不需要更改默认的音频设备,您可以使用默认配置。
- 现在,通过录音来测试麦克风,在你的Raspberry Pi上运行以下命令。
该命令将进行5秒的简短录音。
arecord –format=S16_LE –duration=5 –rate=16000 –file-type=raw out.raw 如果你在运行此命令时收到一个错误,请确保你的麦克风已经插入。只有成功监听到你的麦克风,这个命令才会成功。
- 录制完成后,现在可以运行下面的命令来读取原始输出文件,并将其回放给扬声器。
这样做可以测试播放音量,也可以听录音音量。这样做是一项至关重要的任务,因为你不希望你的树莓派接收到小噪音,但也不希望当你说 “Ok Google “时,它能够勉强听到你的声音。
aplay –format=S16_LE –rate=16000 out.raw
- 如果你发现播放音量或录音音量过高或过低,那么你可以运行以下命令启动混音器。
该命令可以调整各种输出设备的输出音量。从我的测试来看,我建议你使用至少70的电平,利用本节步骤1中的命令来检查音量水平。
alsamixer 一旦确认麦克风和扬声器工作正常,就可以着手设置你自己的Raspberry Pi谷歌助手!
按住 fn键+F6键,切换声卡,选择你使用的扬声器,我这里是插耳机,也就是Headphones这个,选择以后,滚动滑轮即可调整声音大小。
配置相应的库
sudo apt install python3 python3-pip python3-all-dev python3-pyaudio portaudio19-dev libsndfile1(成功)
sudo pip3 install pvporcupine(很慢,要注意安装到了哪里,这个并不是安装在虚拟环境里面的!)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
pip3 install PyAudio(失败,第三次成功,因该是源的问题)
pip3 install PyAudio -i https://pypi.tuna.tsinghua.edu.cn/simple(失败)
下载pyaudio轮子,在下面这个网址中检索(Ctrl+f)pyaudio,点击
https://www.lfd.uci.edu/~gohlke/pythonlibs/
注意找到相应的版本
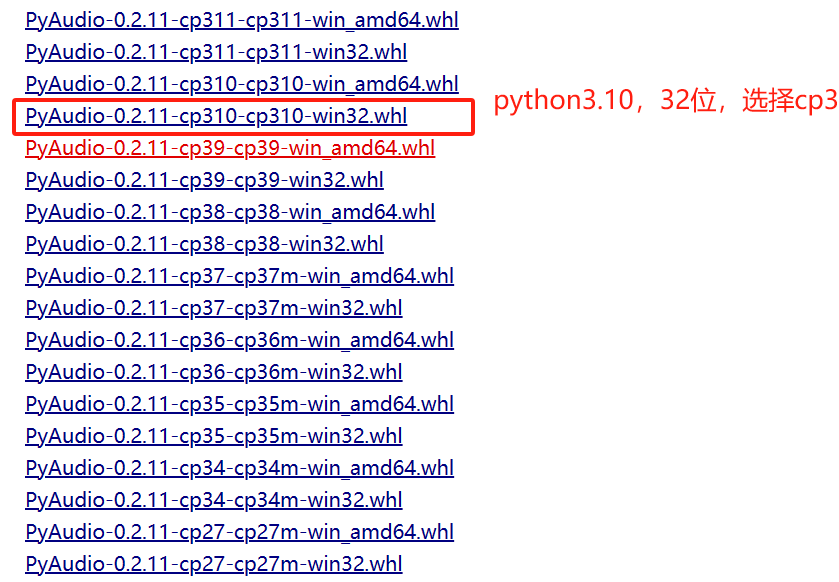
查看版本:
[root@localhost local]# getconf LONG_BIT
32
sudo apt-get install portaudio19-dev python-all-dev
pyaudio安装失败好多次,整了几个小时,草,终于发现原来安装到了python2上面了,然后python3用pip又安装不了,说是网络问题。
然后想下载这个的whl,pyaudio-cp310-cp310-linux_armv7l.whl,却又找不到,但好歹也了解到了whl的版本选择
uname -a查看linux的详细信息,像是架构,位,什么的。。。。
最后通过gpt问出来了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
如果你不想使用pip,又想将 PyAudio 安装到 Python 3.10.7 上,你可以尝试从源代码构建并安装 PyAudio。以下是步骤:
首先,确保你的系统上已经安装了必要的构建工具和依赖项。你可以运行以下命令来安装这些依赖项:
bash
Copy code
sudo apt-get install portaudio19-dev
这将安装 PortAudio 开发库,它是 PyAudio 的依赖项。
下载 PyAudio 源代码。你可以从 PyAudio 的 GitHub 仓库下载最新的源代码压缩包:https://github.com/jleb/pyaudio
解压源代码压缩包并进入解压后的目录:
bash
Copy code
tar -zxvf pyaudio-master.tar.gz
cd pyaudio-master
在终端中执行以下命令来构建和安装 PyAudio:
bash
Copy code
python3.10 setup.py build
sudo python3.10 setup.py install
这将使用 Python 3.10.7 来构建和安装 PyAudio。
安装完成后,你可以在 Python 3.10.7 中导入 PyAudio 模块:
python
Copy code
import pyaudio
通过这种方法,你可以手动构建并安装 PyAudio,以确保它与你所需的 Python 版本兼容,而不依赖于pip。请注意,这可能需要一些时间和努力,但它是一种备选方法。
总结:学习得控制时间和效率,不然卡了的时候容易上头,然后又效率极低,还很浪费时间。工作时间最好控制在一小时左右,最长不能超过两个小时。然后就必须得放松,转移一下注意力。学会提问,未来是属于gpt的,马斯克说的没错,未来不缺写代码的,因为会被机械说取代,我们需要抓住思路,使用决策的思路。
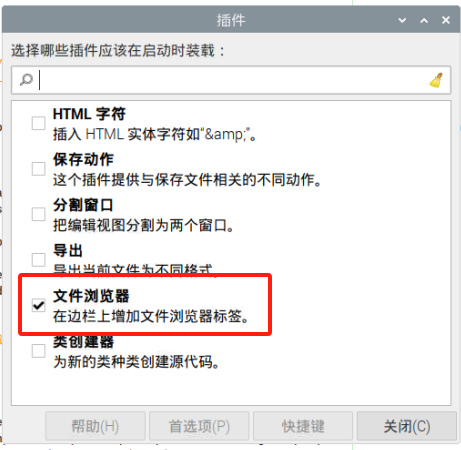
补充:树莓派里面用Geany打开文件夹可以在工具里的插入管理器哪里选择文件插件,就可以打开文件夹了
放个代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
#!/usr/bin/env python3.10
import pvporcupine
import pyaudio
import struct
import wave
porcupine_key = "xxxx"
porcupine_model = '/file/model/hello-chat_en_raspberry-pi_v3_0_0.ppn'
def keyword_wake_up():
porcupine = pvporcupine.create(access_key=porcupine_key, keyword_paths=[porcupine_model])
kws_audio = pyaudio.PyAudio()
audio_stream = kws_audio.open(
rate=porcupine.sample_rate,
channels=1,
format=pyaudio.paInt16,
input=True,
frames_per_buffer=porcupine.frame_length,
input_device_index=None,
)
print("等待唤醒中,唤醒词:hello chat...")
recording = []
while True:
pcm = audio_stream.read(porcupine.frame_length)
_pcm = struct.unpack_from("h" * porcupine.frame_length, pcm)
keyword_index = porcupine.process(_pcm)
recording.extend(_pcm)
if keyword_index >= 0:
print("唤醒了捏!")
save_audio(recording)
return
audio_stream.stop_stream()
audio_stream.close()
porcupine.delete()
kws_audio.terminate()
def save_audio(data, filename="wake_word.wav"):
wf = wave.open(filename, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(16000) # Adjust the sample rate as needed
wf.writeframes(b''.join(struct.pack('h', sample) for sample in data))
wf.close()
keyword_wake_up()
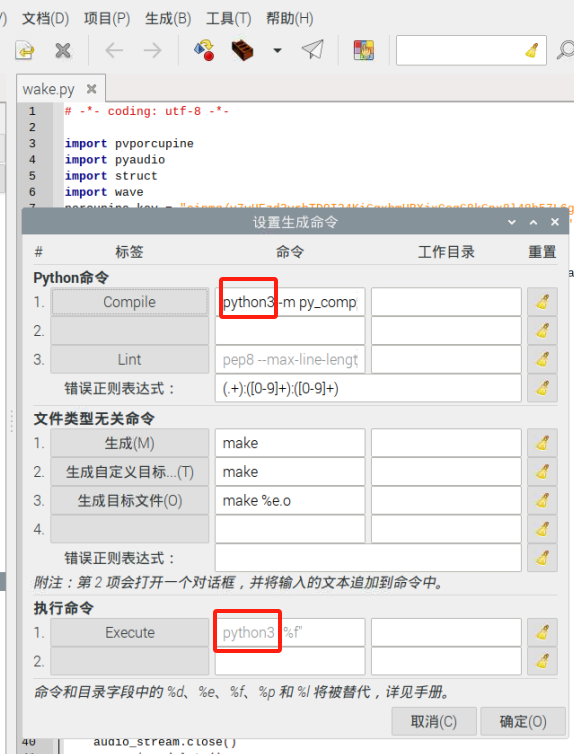
补充: geany配置python;这个默认运行的是python,也就是python2,而我们需要用到的是python3,所以需要在设置生成命令哪里修改python编译器的选择,如图,
第二次使用的代码,几乎没什么改进
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
# -*- coding: utf-8 -*-
from aip import AipSpeech
import pvporcupine
import pyaudio
import struct
import wave
import json
import base64
import io
import pvcobra
import time
porcupine_key = "cinmq/v7vHEzd3vrbTD9I24KiGgxbmUBXjxCcgG8kGnx8l48h57L6g=="
porcupine_model = '../file/model/hello-chat_en_raspberry-pi_v3_0_0.ppn'
def get_file_content(filePath): # filePath 待读取文件名
with open(filePath, 'rb') as fp:
return fp.read()
def sound_record():
porcupine = pvporcupine.create(access_key=porcupine_key, keyword_paths=[porcupine_model])
cobra = pvcobra.create(access_key=porcupine_key)
kws_audio = pyaudio.PyAudio()
audio_stream = kws_audio.open(
rate=porcupine.sample_rate,
channels=1,
format=pyaudio.paInt16,
input=True,
frames_per_buffer=porcupine.frame_length,
input_device_index=None,
)
is_voiced = 1
print("开始录音...")
recording = []
silence_count = 0
while is_voiced:
pcm = audio_stream.read(porcupine.frame_length)
_pcm = struct.unpack_from("h" * porcupine.frame_length, pcm)
is_voiced = cobra.process(_pcm)
print(is_voiced,silence_count)
silence_count = 0 if is_voiced > 0.5 else silence_count + 1
if silence_count <= 100:
if silence_count < 70:
recording.extend(_pcm)
else:
break
filename = save_audio(recording)
audio_stream.stop_stream()
audio_stream.close()
porcupine.delete()
kws_audio.terminate()
# 保存录音结果为WAV文件
print(f"录音已保存:recorded_audio.wav")
return filename
def save_audio(data, filename="../file/tmp/recorded_audio.wav"):
wf = wave.open(filename, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(16000) # Adjust the sample rate as needed
wf.writeframes(b''.join(struct.pack('h', sample) for sample in data))
wf.close()
return filename
''' 你的APPID AK SK 参数在申请的百度云语音服务的控制台查看'''
APP_ID = '41921615'
API_KEY = '066z1Dktz7pNjWFWrZ3CSV6z'
SECRET_KEY = 'YloZH3xxv08TCVXGs13BoLP1gfPK0IRM'
textPath = '../file/tmp/text.txt'
# 新建一个AipSpeech
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def baidu_stt(filename):
result = client.asr(get_file_content(filename), 'wav', 16000, {'dev_pid': 1536})
if result['err_msg'] == 'success.':
print("stt successful")
word = result['result'][0].encode('utf-8') # utf-8编码
wordStr = word.decode('utf-8') # Decode the bytes to a string
if wordStr != '':
if wordStr[-3:] == ',':
print(wordStr[:-3])
with open(textPath, 'w', encoding='utf-8') as f:
f.write(wordStr[:-3])
else:
print(wordStr)
with open(textPath, 'w', encoding='utf-8') as f:
f.write(wordStr)
else:
print("音频文件不存在或格式错误")
else:
print("错误")
return wordStr
def listen(model: str = "baidu"):
filepath = sound_record()
if model == "baidu":
user_words = baidu_stt(filepath)
else:
user_words = "Unsupported speech recognition model"
if user_words == "":
print("你什么都没说")
else:
print("你说了: ", user_words)
return user_words
listen()