
https://blog.csdn.net/black_sneak/article/details/131374492
YOLOv5-Lite
YOLOv5 网络模型算是 YOLO 系列迭代后特别经典的一代网络模型,作者为:Glenn Jocher。部分学者可能认为YOlOv5的创新性不足,其是否称得上 YOLOv5 而议论纷纷。作者认为 YOLOv5 可以算是对 YOLO 系列之前的一次集大成者的总结和突破,其属于非常优秀经典的网络模型框架,各种网络结构和 trick 是非常值得借鉴的!
Yolov5 官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。
Yolov5s 网络是 Yolov5 系列中深度最小,特征图的宽度最小的网络。后面的3种都是在此基础上不断加深,不断加宽。Yolov5 的网络结构图如下(源于江大白大佬的结构图):
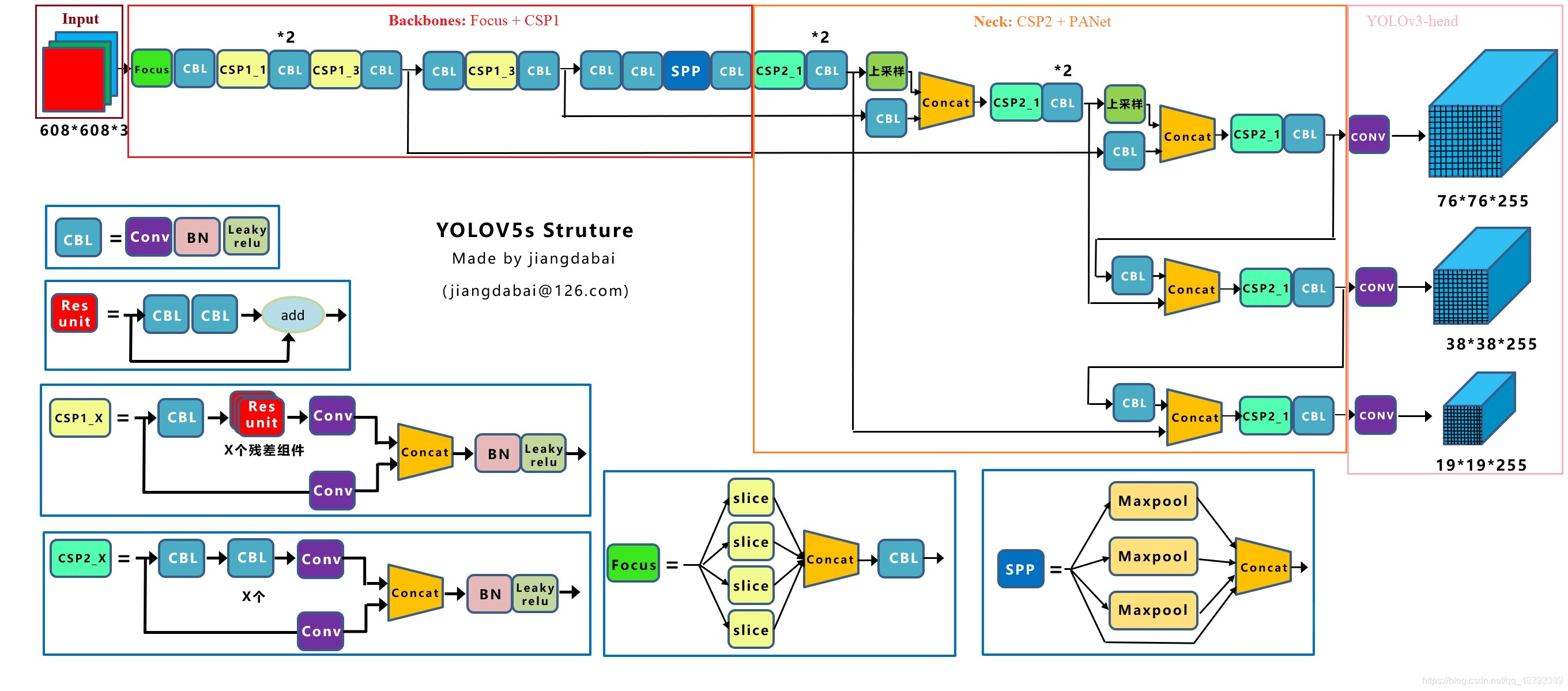
上图即 Yolov5 的网络结构图,可以看出,还是分为输入端、Backbone、Neck、Prediction四个部分。
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放 (2)Backbone:Focus结构,CSP结构 (3)Neck:FPN+PAN结构 (4)Prediction:GIOU_Loss
Yolov5-Lite 网络模型作为轻量化部署网络的代表作之一,深受算法部署工程师的偏爱(作者为中国ppogg大佬)!
Yolov5-Lite地址:GitHub - ppogg/YOLOv5-Lite: 🍅🍅🍅YOLOv5-Lite: lighter, faster and easier to deploy. Evolved from yolov5 and the size of model is only 930+kb (int8) and 1.7M (fp16). It can reach 10+ FPS on the Raspberry Pi 4B when the input size is 320×320~
Yolov5-Lite 算法的模型结构如图下。该算法去除了 Focus 结构层,减小了模型体量,使模型变得更为轻便;同时,去除了 4 次 slice 操作,减少了对计算机芯片缓存的占用,降低了计算机的处理负担。与 Yolov5 算法相比,Yolov5-Lite 算法能避免反复使用 C3 Layer 模块。C3 Layer 模块会占用计算机很多运行空间,从而降低计算机的处理速度。这种方式能使 Yolov5-Lite 算法模型的精度控制在可靠范围内,从而使其更易部署。
… …
YOLOv5-Lite 数据集制作
- 数据集制作
★常规的神经网络模型训练是需要收集到大量语义丰富的数据集进行训练的。但是考虑实际工程下可能仅需要对已知场地且固定实物进行目标检测追踪等任务,这个时候我们可以采取偷懒的下方作者使用的方法!
1 作者使用树莓派4B的 Camera 直接在捕获需要识别目标物的图片信息(捕获期间转动待识别的目标物体);
树莓派4B的 Camera 定时捕获照片的python代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
import cv2
from threading import Thread
import uuid
import os
import time
count = 0
def image_collect(cap):
global count
while True:
success, img = cap.read()
if success:
file_name = str(uuid.uuid4())+'.jpg'
cv2.imwrite(os.path.join('images',file_name),img)
count = count+1
print("save %d %s"%(count,file_name))
time.sleep(0.4)
if __name__ == "__main__":
os.makedirs("images",exist_ok=True)
# 打开摄像头
cap = cv2.VideoCapture(0)
m_thread = Thread(target=image_collect, args=([cap]),daemon=True)
while True:
# 读取一帧图像
success, img = cap.read()
if not success:
continue
cv2.imshow("video",img)
key = cv2.waitKey(1) & 0xFF
# 按键 "q" 退出
if key == ord('c'):
m_thread.start()
continue
elif key == ord('q'):
break
cap.release()
```
按动 “c” 开始采集待识别目标图像,按动 “q” 退出摄像头 Camera 的图片采集;
2 将捕获到的待识别目标物照片传输到PC端,利用 Labelme 软件进行标注(Labelme不会使用的建议相关博客);

作者的标注了 3 类目标:drug,prime,glue;读者朋友可以根据自己实际情况标注自己需要的数据集!由于我们标注的数据的标签 label 默认是 JSON 格式的不能被 YOLO 系列的神经网络模型直接进行利用训练。
3 使用 JSON 转 txt 的 YOLO 格式 label 的python代码进行转换(可以直接使用作者提供的代码):
dic_lab.py:
```c
dic_labels= {'drug':0,
'glue':1,
'prime':2,
'path_json':'labels',
'ratio':0.9}
lablemetoyolo.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
import os
import json
import random
import base64
import shutil
import argparse
from pathlib import Path
from glob import glob
from dic_lab import dic_labels
def generate_labels(dic_labs):
path_input_json = dic_labels['path_json']
ratio = dic_labs['ratio']
for index, labelme_annotation_path in enumerate(glob(f'{path_input_json}/*.json')):
# 读取文件名
image_id = os.path.basename(labelme_annotation_path).rstrip('.json')
# 计算是train 还是 valid
train_or_valid = 'train' if random.random() < ratio else 'valid'
# 读取labelme格式的json文件
labelme_annotation_file = open(labelme_annotation_path, 'r')
labelme_annotation = json.load(labelme_annotation_file)
# yolo 格式的 lables
yolo_annotation_path = os.path.join(train_or_valid, 'labels',image_id + '.txt')
yolo_annotation_file = open(yolo_annotation_path, 'w')
# yolo 格式的图像保存
yolo_image = base64.decodebytes(labelme_annotation['imageData'].encode())
yolo_image_path = os.path.join(train_or_valid, 'images', image_id + '.jpg')
yolo_image_file = open(yolo_image_path, 'wb')
yolo_image_file.write(yolo_image)
yolo_image_file.close()
# 获取位置信息
for shape in labelme_annotation['shapes']:
if shape['shape_type'] != 'rectangle':
print(
f'Invalid type `{shape["shape_type"]}` in annotation `annotation_path`')
continue
points = shape['points']
scale_width = 1.0 / labelme_annotation['imageWidth']
scale_height = 1.0 / labelme_annotation['imageHeight']
width = (points[1][0] - points[0][0]) * scale_width
height = (points[1][1] - points[0][1]) * scale_height
x = ((points[1][0] + points[0][0]) / 2) * scale_width
y = ((points[1][1] + points[0][1]) / 2) * scale_height
object_class = dic_labels[shape['label']]
yolo_annotation_file.write(f'{object_class} {x} {y} {width} {height}\n')
yolo_annotation_file.close()
print("creat lab %d : %s"%(index,image_id))
if __name__ == "__main__":
os.makedirs(os.path.join("train",'images'),exist_ok=True)
os.makedirs(os.path.join("train",'labels'),exist_ok=True)
os.makedirs(os.path.join("valid",'images'),exist_ok=True)
os.makedirs(os.path.join("valid",'labels'),exist_ok=True)
generate_labels(dic_labels)
我们需要根据自己的需要自定义字典 dic_lab,字典中的 ratio = 0.9 的作用是将数据集拆分成训练集和验证集 9:1。读者朋友可以根据自己的实际情况去修改字典的标签内容,成功执行 lablemetoyolo.py 代码后效果如下:
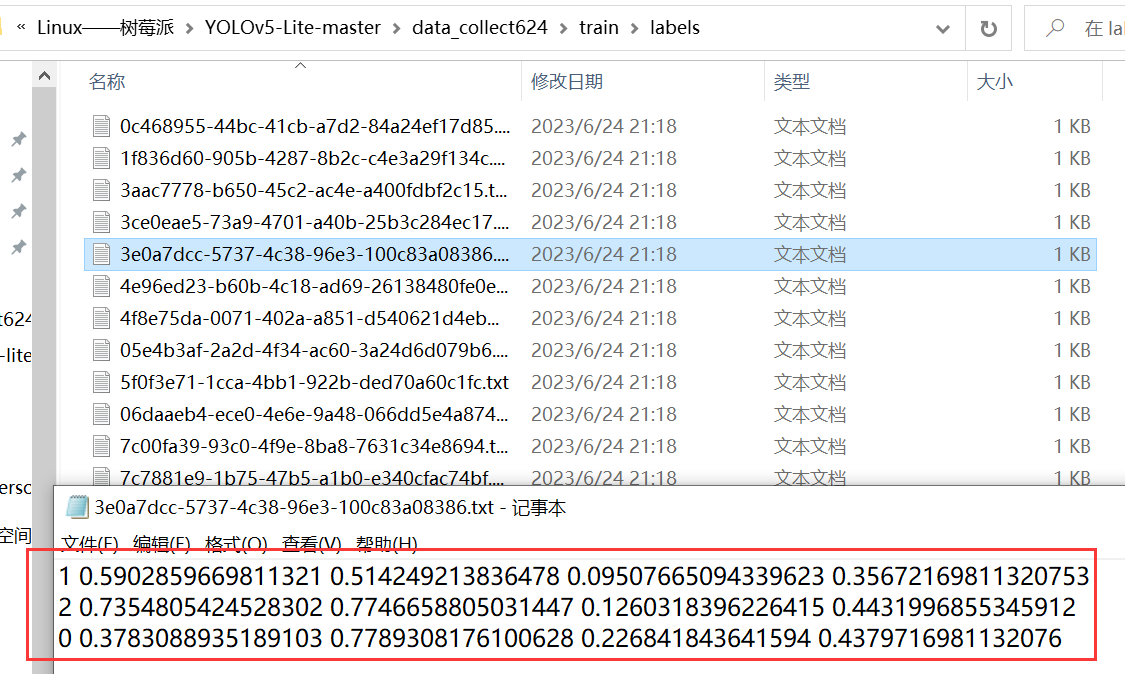
labels文件夹下的标签成功转换了 YOLO 系列可以使用的 label 标签,到此时就已经成功准备好我们需要的训练集了!
特别说明:该方法仅适用于上述作者所说的场景下,实际情况下,建议大家还是使用合格的数据集进行训练(即目标与背景语义丰富的数据集),使得训练出来的神经网络具有良好的泛化性与鲁棒性,否则训练出来的网络很容易过拟合!
实验过程
前置步骤 开了张新卡,烧录镜像、配置vnc、配置源、
打开vnc:sudo raspi-config
选择resolution分辨率,sudo raspi-config…略(搜索使用VNC连接树莓派4b如何全屏1080p分辨率,一次更改永久有效!)
配置源 sudo nano /etc/apt/sources.list
deb http://mirrors.tuna.tsinghua.edu.cn/raspbian/raspbian/ buster main non-free contrib rpi
deb-src http://mirrors.tuna.tsinghua.edu.cn/raspbian/raspbian/ buster main non-free contrib rpi
sudo nano /etc/apt/sources.list.d/raspi.list 同样的方法,把 /etc/apt/sources.list.d/raspi.list 文件也替换成下面的内容:
deb http://mirrors.tuna.tsinghua.edu.cn/raspberrypi/ buster main ui
sudo apt-get update
问题:1.为了让这个仓库能够应用,这必须在更新之前显式接受。更多细节请参阅 apt-secure(8) 手册。
解决方案:sudo apt update,然后按Y
配置pip源
sudo nano /etc/pip.conf
[global] timeout=100 index-url=https://pypi.tuna.tsinghua.edu.cn/simple/ extra-index-url= http://mirrors.aliyun.com/pypi/simple/ [install] trusted-host= pypi.tuna.tsinghua.edu.cn mirrors.aliyun.com
python -m pip install –upgrade pip python3 -m pip install –upgrade pip
配置geany
1
2
3
4
5
6
7
8
9
10
11
geany上部工具栏中点击:生成->设置生成命令(s)
接下来需要修改"Python命令"下的Compile和执行命令下的Execute。
Compile->
python3的路径/python3 -m py_compile “%f”
Execute
python3的路径/python3 “%f”
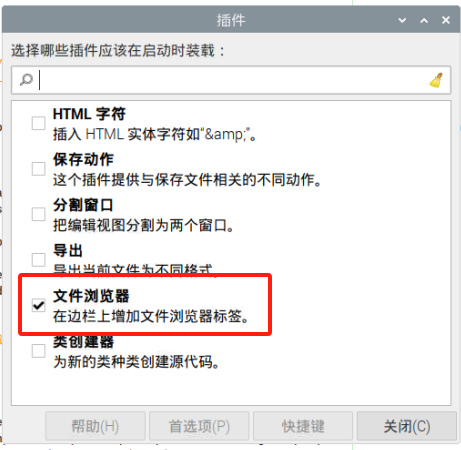
树莓派里面用Geany打开文件夹可以在工具里的插入管理器哪里选择文件插件,就可以打开文件夹了
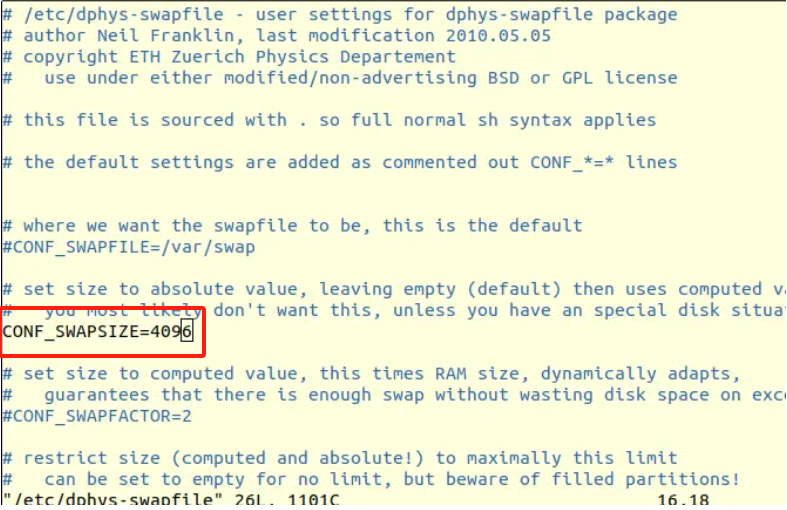
安装库很慢,卡主的原因可能是因为swap空间不住
1
2
3
4
5
6
7
8
9
free -m 查看swap空间大小(96左右)
sudo apt-get install dphys-swapfile
sudo nano /etc/dphys-swapfile
CONF_SWAPSIZE=4096 (找到这个地方,修改)
sudo /etc/init.d/dphys-swapfile restart
1
2
3
重启
free -m 查看,变为了4095
- 安装库
sudo apt update sudo apt install python3-opencv
使用代码拍摄了100张左右的图片,传到电脑上,使用下载的labelme.exe标记。
标记的时候要注意标记的是矩形,而非其他形状,否则就会白费功夫,我就标了快一个多小时,然后运行代码报错的时候才发现。后面才发现似乎有一个autolabeling的东西。靠。所以一定要看看官方文档!!
工作是做不完的、唯有提升效率才是真的。做到一半、面对问题卡住了,怎么办。就像是现在,按着教程做,但是遇到了问题,将报错丢给gpt,说。
1
2
3
4
5
6
7
8
9
10
11
这个错误表明在处理数据集时出了问题,具体地说是在加载标签时出现了错误。根据错误信息,似乎是在尝试从缓存中读取标签时出现了问题。可能的原因包括:
标签文件缺失或格式不正确: 确保数据集中的标签文件存在且格式正确。标签文件应该包含与图像相关联的对象的位置和类别信息。
数据集路径错误: 确保指定的数据集路径正确,能够找到图像和相应的标签文件。
缓存文件损坏: 缓存文件可能损坏了,可以尝试删除缓存文件并重新运行以重新生成缓存。
数据集中的图像文件损坏: 可能有一些图像文件损坏或格式不正确,导致无法读取图像和相应的标签。
数据集标签不匹配: 确保标签文件中的每个图像都有对应的标签,且标签格式与代码期望的格式匹配。
分析:1.数据集有问题(标签、路径、图片)2.缓存有问题
自己的数据集一直不行,试着先拿范例的数据集先训练一次模型先
在github下载YOLOv5-Lite-master,获取https://gitee.com/yuhong-ldu/python-raspberry-pi/tree/master/EXP-yolov5-lite里的资料,按照https://www.bilibili.com/video/BV14r4y1578r/?spm_id_from=333.788&vd_source=1b3a69827a34547eb2ee0ed4099455e7说的做。
过程中遇到很多bug:
- 个是要将np.int改为int,因为包更新了,之前的弃用了
- loss.py文件运算错误RuntimeError: result type Float can’t be cast to the desired output type long int · Issue#35 · WongKinYiu/yolov7 · GitHub,参考https://blog.csdn.net/weixin_41012399/article/details/127765978
- not enough values to unpack (expected 3, got 2) 解决:将test.py的110行改为out, train_out = model(img, augment=augment) # inference and training outputs
接着就可以顺利训练了, 
两百来张数据集,没有gpu的话大概5、6个小时,差不多一个晚上的时间,用gpu的话这个工作量大概十来分钟,电脑有gpu,搞过一次,没成功,现在尝试着弄一下
总结:问题不难,找到渠道就简单了,我花了很多的时间纠结在数据集上面,但某个教学视频的评论区里面就有着老师的数据集,这才解决了数据集的麻烦,我才确认了数据集的格式,后面有报错,绝大多数的bug都可以在评论区里找到,或者是网上搜到,找gpt解决,这得出一个结论,找的方法渠道,要找最宽广的那一条,那样可以参考借鉴的就多,就像是这次查找的资料,找了一个热门的,结果很多别遇到过的bug都在评论区里。找对方法很重要。
gpu加速
查阅电脑显卡版本 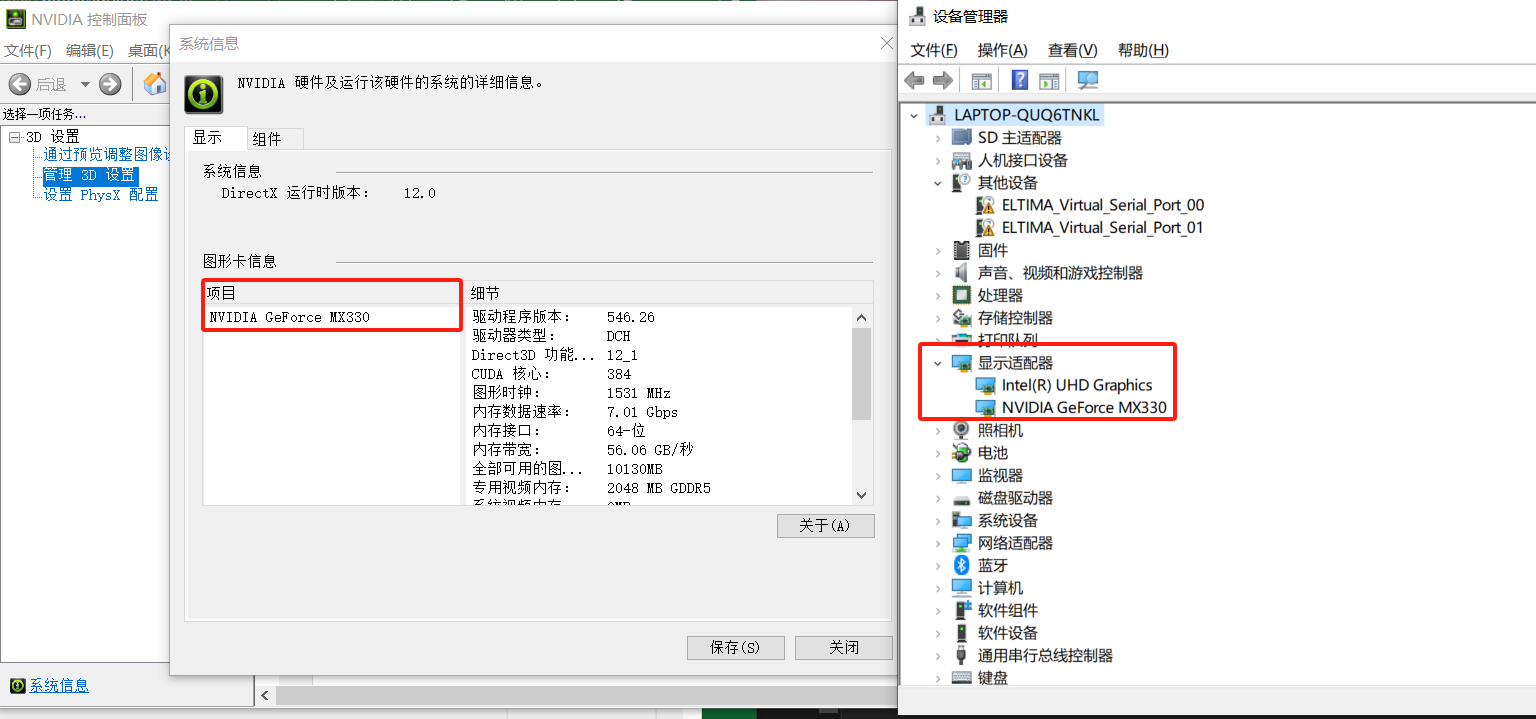
电脑显卡版本:NVIDIA GeForce MX330
卸载NVDIA的相关程序 
学习计划 在一小时内基本学习 GPU 和 CUDA,我建议你可以按照以下步骤来进行:
步骤一:了解 GPU 和 CUDA 的基础知识(20 分钟)
首先了解什么是 GPU,以及它如何用于加速并行计算。 然后了解什么是 CUDA,以及它如何在 NVIDIA 的 GPU 上进行编程。 你可以阅读 NVIDIA 官方网站或者相关教材中的简介部分,或者观看一些在线教程或视频。
步骤二:设置 CUDA 环境(10 分钟)
确认你的机器是否有 NVIDIA 的 GPU,并且是否支持 CUDA。 安装 NVIDIA 的驱动程序和 CUDA 工具包。
步骤三:编写并运行你的第一个 CUDA 程序(20 分钟)
学习 CUDA 编程的基本概念,包括线程、块、网格和内存模型。 编写一个简单的 CUDA 程序,例如使用 GPU 进行向量加法。 你可以找一些 CUDA 的教程或样例代码,然后自己动手实践。
步骤四:理解并优化 CUDA 程序(10 分钟)
学习如何使用 CUDA 的内存管理功能,包括全局内存、共享内存和常量内存。 学习如何优化 CUDA 程序,包括线程并行度、内存访问模式和指令级并行。 以上就是一小时内学习 GPU 和 CUDA 的一个可能的学习计划。这只是一个初级的介绍,要熟练掌握 GPU 和 CUDA 编程,还需要更深入的学习和实践。如果在学习过程中遇到任何问题,你可以查阅 CUDA 的官方文档,或者在网上寻找相关的教程和问答。
步骤三和步骤四主要涉及到 CUDA C/C++ 编程,这不需要任何额外的库或技术,只需要 NVIDIA 提供的 CUDA Toolkit。
了解 GPU 和 CUDA 的基础知识
什么是 GPU,以及它如何用于加速并行计算
什么是 GPU?
GPU (Graphics Processing Unit,图形处理单元)最初是为了加速计算机图形渲染而设计的。与中央处理单元(CPU)不同,CPU 是为了处理一系列的任务而设计的,而 GPU 是为了并行处理大量的数据而设计的。这种并行性使 GPU 特别适合处理那些可以分解为多个小任务并且可以同时执行的问题,例如图形渲染。
GPU 的特点:
1
2
3
4
大量的核心 :传统的 CPU 可能有 4、8、16 或更多的核心,而 GPU 可能有上千个核心。这些核心可以同时处理大量的任务。
高吞吐量 :尽管每个单独的 GPU 核心的速度可能比 CPU 核心慢,但由于其数量众多,GPU 可以处理的总任务数量远远超过 CPU。
专为并行处理设计 :GPU 的设计原则是大量并行处理。每个核心都是为了处理独立的、相对简单的任务而设计的。
内存体系结构 :GPU 通常有自己的专用内存,这使得数据的读取和写入非常快。但这也意味着数据需要在主机(CPU)和设备(GPU)之间进行传输。
GPU 如何用于加速并行计算?
随着 GPU 的发展,人们逐渐意识到除了图形渲染之外,它们还可以用于其他类型的并行计算任务。以下是 GPU 用于并行计算的一些方式:
1
2
3
4
5
通用 GPU 计算 :人们开发了一系列工具和技术,如 NVIDIA 的 CUDA 和 OpenCL,允许开发人员直接为 GPU 编写代码,以执行非图形相关的计算任务。
大数据处理 :由于其并行性,GPU 非常适合处理大数据集。例如,在数据科学、金融建模和物理模拟中,可以使用 GPU 加速数据处理和分析。
深度学习和人工智能 :近年来,GPU 已经成为深度学习和 AI 研究的关键工具。神经网络的训练涉及大量的矩阵运算,这些运算可以在 GPU 上并行执行,从而大大减少训练时间。
分子建模和仿真 :GPU 可以用于并行处理与药物设计、气候模型和其他科学应用相关的复杂计算。
图形和视频处理 :除了传统的3D图形渲染,GPU 也被用于视频编解码、图像分析和其他多媒体任务。
总结:
GPU 由于其高度并行的结构和设计,已经从一个专门用于图形渲染的设备发展成为一个通用的、高性能的计算工具。从科学研究到商业分析,从游戏到艺术创作,GPU 在许多领域都发挥着关键作用,加速了各种各样的并行计算任务。
了解什么是 CUDA,以及它如何在 NVIDIA 的 GPU 上进行编程
CUDA(Compute Unified Device Architecture)是NVIDIA公司开发的一个并行计算平台和编程模型。它允许开发者直接使用NVIDIA的GPU来执行通用计算任务,从而获得比传统CPU计算更高的性能。CUDA基本上是将GPU从一个纯粹的图形渲染设备转变为一个通用并行处理器。
CUDA的主要特点:
1
2
3
并行处理 :NVIDIA的GPU由数千个处理核心组成,可以并行处理大量的任务。
适用于高度并行的计算任务 :如图形渲染、科学计算、深度学习等。
与C/C++语言集成 :CUDA提供了一个C语言的扩展,使得开发者可以在C/C++代码中直接编写运行在GPU上的函数(称为kernels)。
CUDA编程的基本概念:
1
2
3
4
Kernel :在GPU上运行的函数,可以并行处理多个数据元素。
Thread:执行kernel的基本单位。每个线程都会处理数据的一个或多个元素。
Block :线程的集合。一个block内的所有线程都可以共享一定的内存资源。
Grid :block的集合。整个grid是在GPU上并行执行kernel的所有线程的集合。
CUDA编程的基本步骤:
1
2
3
4
5
数据分配 :在主机(CPU)和设备(GPU)之间分配和初始化内存。
数据传输 :将数据从主机传输到设备。
Kernel启动 :指定grid和block的大小,并在GPU上启动kernel。
数据检索 :将结果从设备传输回主机。
清理 :释放设备和主机上的内存资源。
设置 CUDA 环境
确认机器是否有NVIDIA的GPU的方法
- 使用NVIDIA系统管理工具 (nvidia-smi)
如果您的系统上已经安装了NVIDIA的驱动程序,那么您可能已经有了 nvidia-smi这个工具。这是一个命令行工具,可以显示有关NVIDIA GPU的详细信息。
在命令行或终端中运行以下命令:
nvidia-smi 运行结果 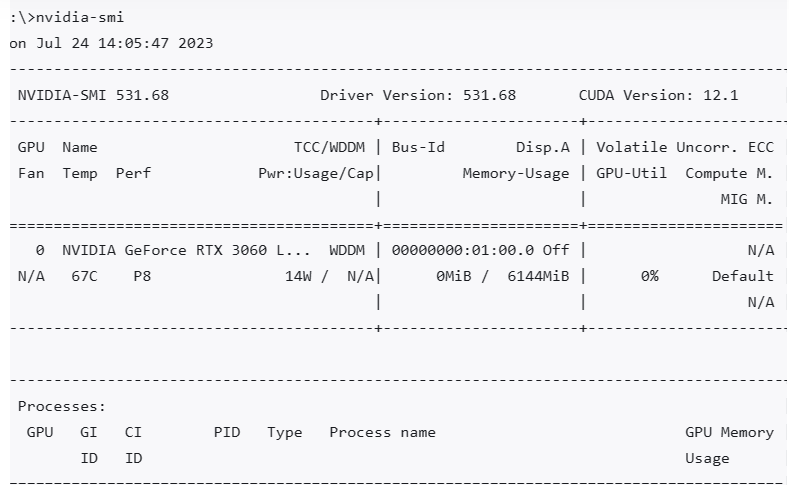
在nvidia-smi的输出中,以下部分给出了关于NVIDIA软件和驱动的版本信息:
1
2
3
NVIDIA-SMI 531.68:这表示你正在使用的NVIDIA System Management Interface (SMI)工具的版本号。SMI工具用于查询和控制NVIDIA GPU的状态和配置。
Driver Version: 531.68:这表示你的系统上安装的NVIDIA GPU驱动程序的版本号。这个数字通常与NVIDIA-SMI的版本匹配,因为它们都是驱动程序套件的一部分。
CUDA Version: 12.1:这表示与你的驱动程序兼容的CUDA版本。CUDA是NVIDIA的并行计算平台和应用程序接口,允许开发者使用NVIDIA GPU进行通用计算。需要注意的是,这表示驱动程序支持的CUDA版本,但不一定是你系统上实际安装的CUDA工具包版本。
总的来说,这些版本信息对于确保软件和硬件的兼容性、进行故障排除、以及确定是否需要软件或驱动程序更新都很重要。
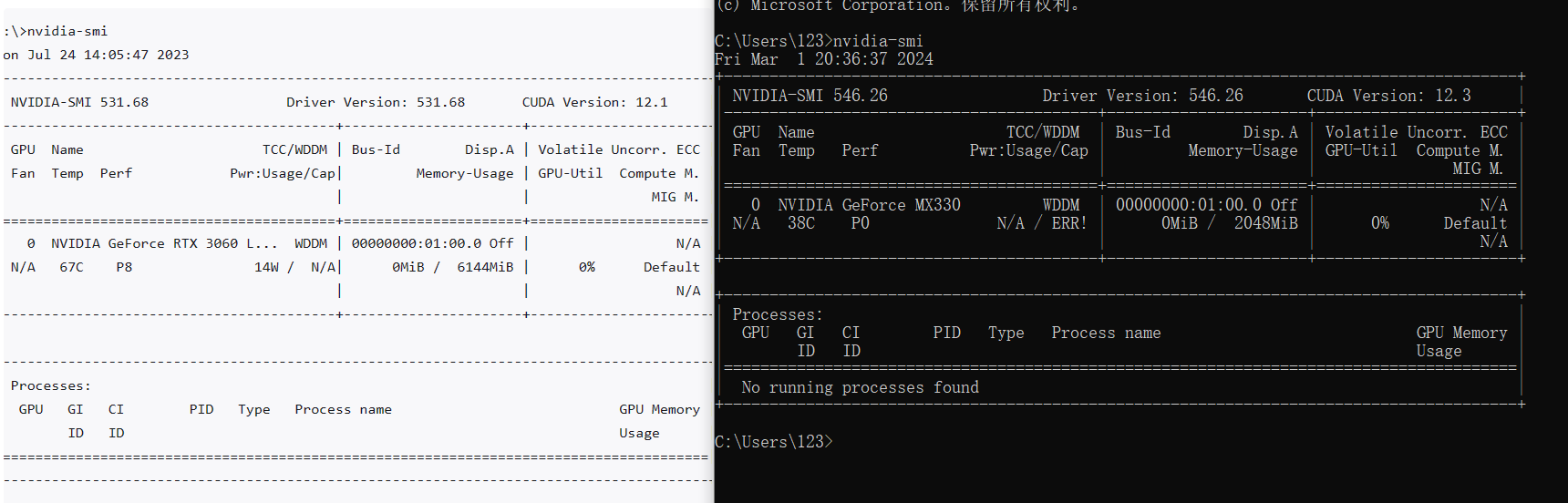
- 查看设备管理器 (仅限Windows)
打开”设备管理器”(可以在开始菜单中搜索”设备管理器”)。 在”设备管理器”窗口中,展开”显示适配器”部分。 在那里,您应该能够看到所有的显卡,包括NVIDIA GPU(如果有的话)。
判断NVIDIA的GPU是否支持CUDA
使用 nvidia-smi
如果你已经安装了NVIDIA驱动,你可以使用 nvidia-smi命令来查看GPU的详细信息。在命令行或终端中运行:
nvidia-smi 这将显示一个关于你的NVIDIA GPU的详细报告。如果你的GPU支持CUDA,它会在输出中列出,并显示CUDA版本。
从您给出的 nvidia-smi输出中,我们可以得到以下关于CUDA的信息:
是否支持CUDA :由于您的输出中显示了”CUDA Version: 12.1”,这意味着您的NVIDIA GPU确实支持CUDA。
CUDA的版本 :
1
2
驱动支持的CUDA最大版本 :在输出中的"CUDA Version: 12.1"表示您的NVIDIA驱动程序支持的CUDA最大版本是12.1。这不是您实际安装的CUDA工具包版本,而是驱动程序兼容的最高版本。
正在使用的CUDA版本 :要查找实际安装的CUDA工具包版本,您需要检查CUDA安装目录(比如:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7)或使用特定的CUDA API/functions。在您的 nvidia-smi输出中,"Driver Version: 531.68"只是告诉我们您的NVIDIA驱动程序版本,而不是您正在使用的CUDA版本。
GPU型号 :您的GPU是NVIDIA GeForce RTX 3060 Laptop GPU。这是一款支持CUDA的现代GPU。
总之,从您的 nvidia-smi输出中,我们可以确认您的GPU支持CUDA,并且您的驱动程序支持的最大CUDA版本是12.1。但要确定您实际安装并正在使用的CUDA版本,您需要查看CUDA的安装目录或使用其他方法。
- 查看NVIDIA的官方支持列表
NVIDIA在其官方网站上有一个CUDA GPUs的支持列表。你可以访问这个列表来查看你的GPU型号是否被列出。如果它在列表上,那么它肯定支持CUDA。
以下是一个直接链接到NVIDIA CUDA GPUs的支持列表的链接(请注意,随着时间的推移,链接可能会发生变化,因为NVIDIA可能会更新其网站结构):
https://link.zhihu.com/?target=https%3A//developer.nvidia.com/cuda-gpus
点击链接将带您到一个页面,列出了各种NVIDIA GPU和它们支持的CUDA计算能力。您可以在此列表中查找您的GPU型号,以确定它是否支持CUDA。
安装NVDIA驱动,我的显卡是MX330,找不到对应的驱动程序,在:https://driverpack.io/zh-cn/devices/video/nvidia/nvidia-geforce-mx330?os=windows-10-x64 这里自动安装了对应的。真不知道之前是怎么安装的。
按正常方法,我的这个显卡在官方那边显示,是不具备安装cuda的。但我还是像试一试
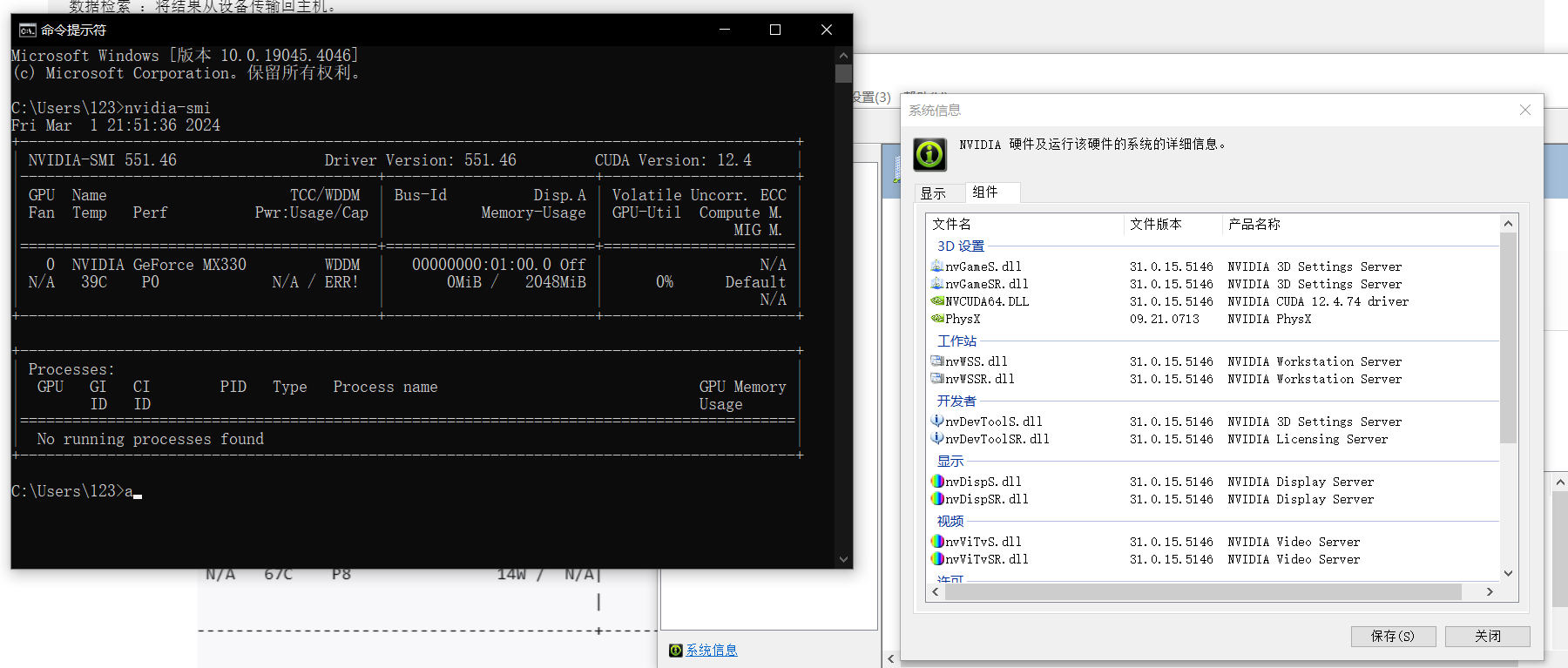
安装的cuda版本最高支持为12.4.74
网上直接下载最新版cuda12.3以及cudnn9.0.0,然后安装(似乎不需要陪环境变量,是自动的),注意如图的那个不要安装, 。 两个都安装完后,测试,
。 两个都安装完后,测试,
nvcc -V 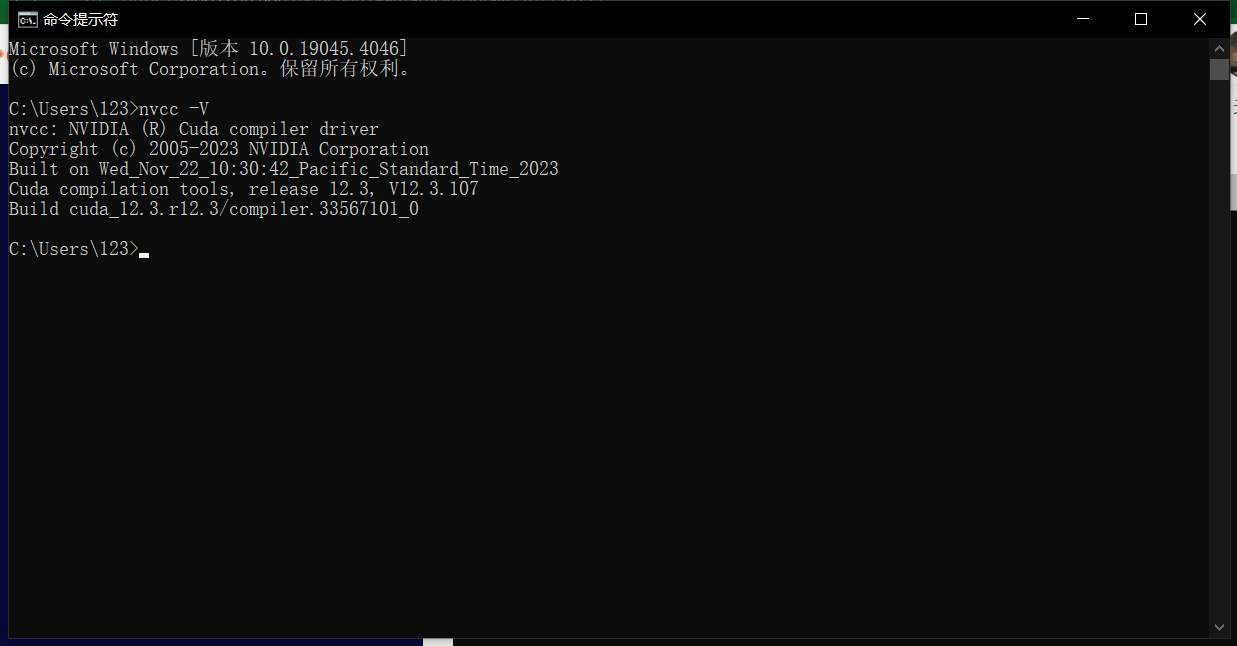
切换到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v1.3\extras\demo_suite目录下,命令行执行bandwidthTest.exe,查看结果是否如下图,显示Pass则安装成功。 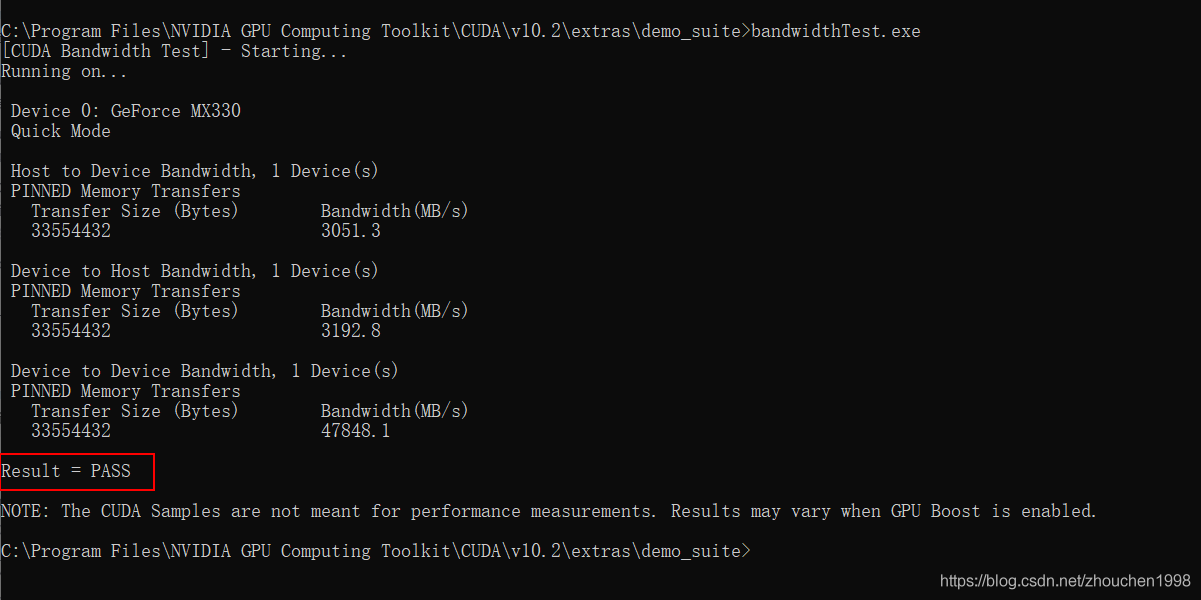
cuda和cudnna安装成功,接下来就是在python安装对于的环境了,但今晚先用着cpu跑着先,明天早上看看怎么样。明天弄一下pycharm的gpu环境,看看能不能跑gpu。
实验过程2
前言:模型训练出来了,gpu加速暂时不想搞了。重新明确了一下目标,当搞到训练大一点的模型的时候,在试着学习一下搞gpu加速,以及学习一下白嫖谷歌的额度。
1
2
3
4
5
6
7
8
9
10
11
12
目标:训练模型,使其能够分辨三个状态,睡眠、玩手机、看书学习。
实现需要的能力:
1.学会训练和部署最简单的模型
2.学会训练一个合适的模型
实现过程:
1.训练范例的模型(完成)
2.部署范例的模型
3.训练自己的模型
4.部署自己的模型
5.训练大一点的模型
6.部署大一点的模型
将模型导出生成onnx模型
python export.py –weights best.pt
报错:AttributeError: ‘Namespace’ object has no attribute ‘ncnn’
1
2
3
4
5
6
7
8
解决方案:
1.(成功)如果你确实需要使用ncnn参数,你应该在argparse.ArgumentParser()的定义中添加这个参数,如下所示:
parser.add_argument('--ncnn', action='store_true', help='ncnn or not')
这样就可以在命令行中使用--ncnn开关,并且opt.ncnn会根据命令行是否使用了这个开关而相应地设置为True或False。
2.如果ncnn参数并不需要,你可以从条件语句中移除对opt.ncnn的引用,即删除或注释掉涉及opt.ncnn的那部分代码。如果这个参数不是脚本所必需的,这样做可以避免出现上述错误。
3.确保所有涉及的参数都已经定义。如果脚本中的其他部分需要ncnn参数,确保它已经在脚本开始处通过argparse正确添加。
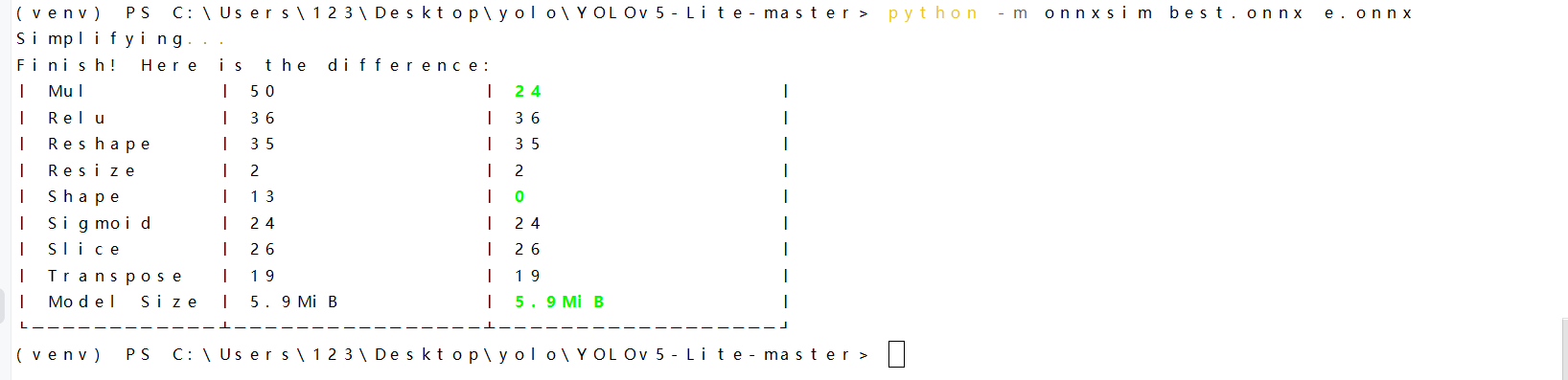
成功将best.pt转换为best.onnx后,使用 onnx-simplifier 对转换后的 onnx 进行简化:
pip install -U onnx-simplifier –user python -m onnxsim best.onnx e.onnx
树莓派部署lite模型
配置环境:(略)
1
2
3
4
5
6
mkdir my_project
cd my_project
python3 -m venv venv
source venv/bin/activate
pip install ....
deactivate
1.安装onnxruntime wget -O onnxruntime-1.9.1-cp37-none-linux_armv7l.whl https://github.com/PINTO0309/onnxruntime4raspberrypi/releases/download/v1.9.1/onnxruntime-1.9.1-cp37-none-linux_armv7l.whl_np1195
pip3 install onnxruntime-1.9.1-cp37-none-linux_armv7l.whl 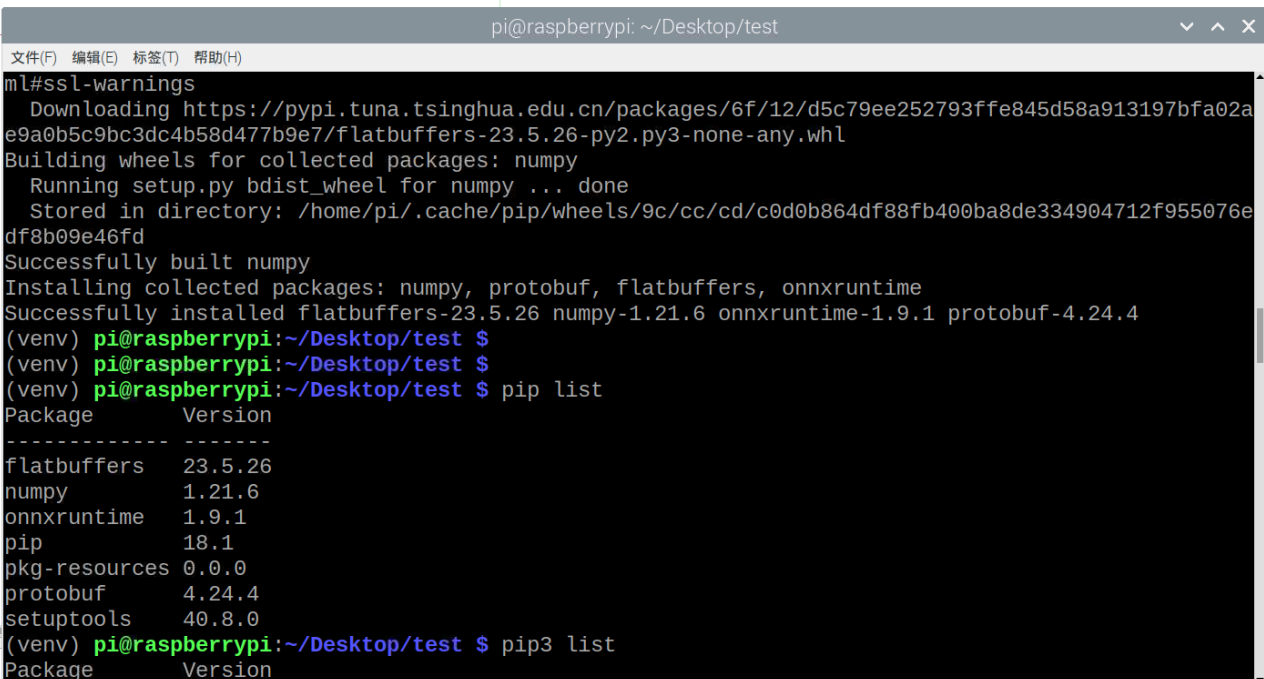
2.安装cv2 pip3 install –upgrade opencv-python(报错) 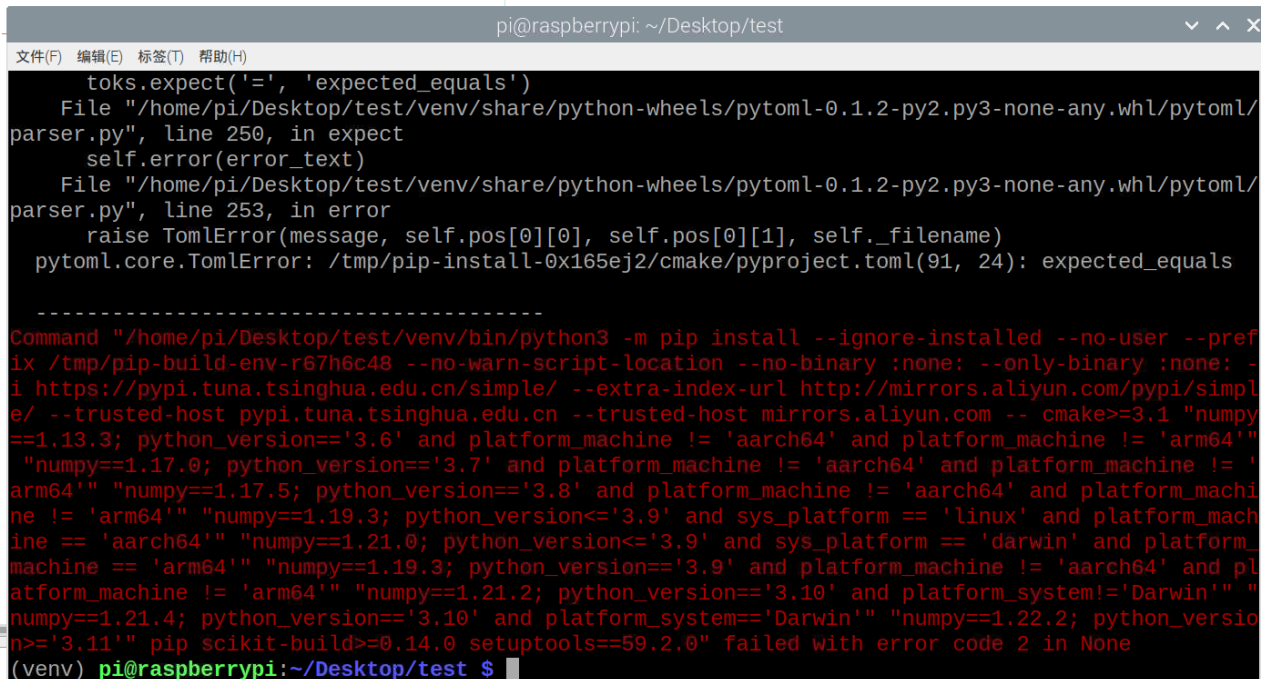
看来没那么容易了
1
2
3
4
5
6
7
8
9
10
11
尝试(失败、还是报那个错误):https://www.bilibili.com/video/BV1G3411e7Gx/?spm_id_from=333.788&vd_source=1b3a69827a34547eb2ee0ed4099455e7
安装依赖包
sudo apt-get install -y libopencv-dev python3-opencv
sudo apt-get install libatlas-base-dev
sudo apt-get install libjasper-dev
sudo apt-get install libqtgui4
sudo apt-get install python3-pyqt5
sudo apt install libqt4-test
安装Python 包(ps:opencv4.5.5需要numpy1.18以上)
pip3 install opencv-python
gpt分析说因为某种原因而停止,但报错没有具体说明是什么原因。
在geany中设置环境
跑代码运行时报错,发现onnxruntime能用,但cv2不能用,原因是cv2安装在系统级环境里了,而onnxruntime安装在虚拟环境里,此刻我正在用的编译是虚拟环境的。
再次尝试(https://zhuanlan.zhihu.com/p/634653426)
安装依赖(已安装,掠过)
1
2
3
确定架构
(venv) pi@raspberrypi:~/Desktop/test $ uname -a
Linux raspberrypi 5.10.63-v7l+ #1457 SMP Tue Sep 28 11:26:14 BST 2021 armv7l GNU/Linux
系统用的是 armv7l 架构
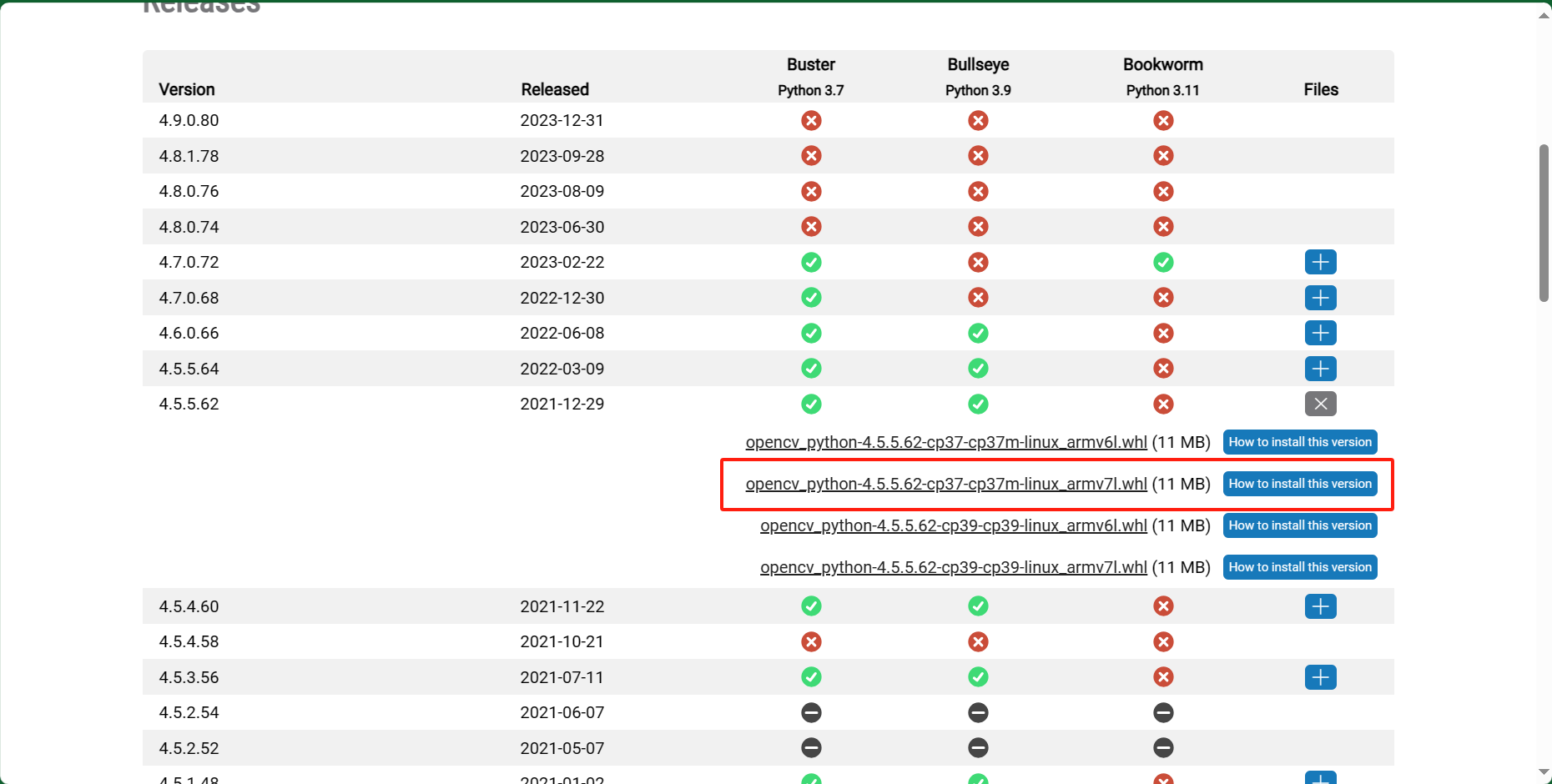 安装这个opencv_python-4.5.5.62-cp37-cp37m-linux_armv7l.whl (成功)
安装这个opencv_python-4.5.5.62-cp37-cp37m-linux_armv7l.whl (成功)

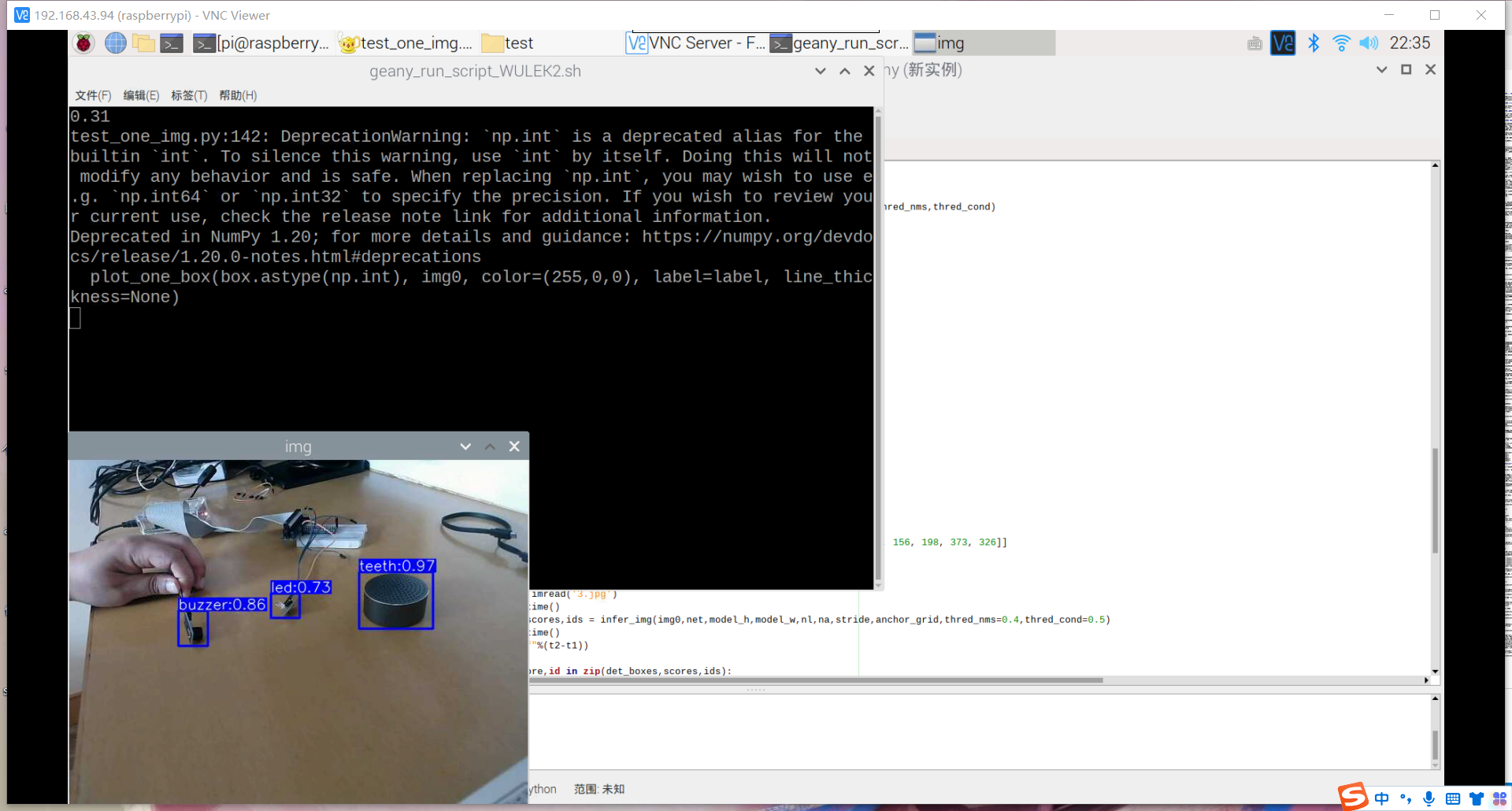
部署成功
跑代码的时候,使用老师的模型可以,但使用自己训练的不行。报错:ValueError: operands could not be broadcast together with shapes (3,2,40,8) (4800,2)
经研读评论区,发现很多人都遇到过这个问题,说是onnx转化的时候出现的问题,可能是代码的问题,于是根据建议去github使用其他人的export.py进行onnx模型转化,最终成功
总结: 1.查阅的资料要注意辨别,过去常常犯了一个错误,就是没有分辨资料是否过时,使用尝试的资料常常各个时间段不一,最好使用google搜索,特别是搜寻最近一年的那种比较新的资料。

2.答案近在咫尺,就是手动将轮子下载,然后安装即可,但我偏偏相信了pip3 install opencv-python,我以为这两个方法是等同的,pip install opencv-python失败,我以为那么手动安装轮子自然也就会失败,我想应该是pip install opencv-python安装的应该是linux通用系统的版本,安装的话可能要手动指定,类似于pip install opencv_python-4.5.5.62-cp37-cp37m-linux_armv7l…这类的吧,符合python版本,符合系统架构、与numpy对应。 我记得pip是一个帮助包自动安装的辅助工具,过去我太信任他了,忽略了它可能安装错误版本的可能,以为它会自动的帮我根据系统分辨出要安装的版本,结果到最后还是要自己手动的选择。pip能帮忙偷一部分的懒。
3.寻找讲课老师的仓库还是很有用的,有时他会将一些包整理的他的gitee上。遇到错误,去github上寻找现成的也比较好,特别是现成的代码,正确的代码。若是能够注意一下,能省去很多是时间。
现在尝试训练用自己的数据,训练自己的模型、部署自己的模型
我再评论区里注意到了一个评论,说的是用labelme标记自己的数据集,然后转化为yolo格式,却出现了负数。后面他又回答了,换个软件就可以了。我看自己的数据集,确实也出现了负数,而且在训练的时候,发现数据集不正确。
或许我应该要学习一下标记数据集了,可能是软件的问题,也可能是转化的时候出现了问题。
过程检查: 1.labelme标记是否规范,得出的json文件能不能用 2.将json文件转化为yolo格式的过程是否规范,得出的文件能不能用
标注数据的正确性:可以用labelme打开json文件检查(可以打开,似乎没有问题) 验证 JSON 文件的格式:JSON 文件应该遵循正确的 JSON 格式。你可以使用在线 JSON 验证工具,例如 JSONLint,来验证文件是否有效。(验证为有效)
或许是2出现了问题。 换成了老师的代码转化,还是如此,应该不是2的问题。
可能是label软件的问题,当初怕麻烦,没有弄那种需要python环境的,下了个双击就运行的那种,结果如此,不知道是不是因怕麻烦而遇到更多的麻烦,现在弄回当初需要python环境的那个,看看是不是如此。 https://blog.csdn.net/weixin_46502301/article/details/115829811
安装成功,过程中遇到了一些问题,如
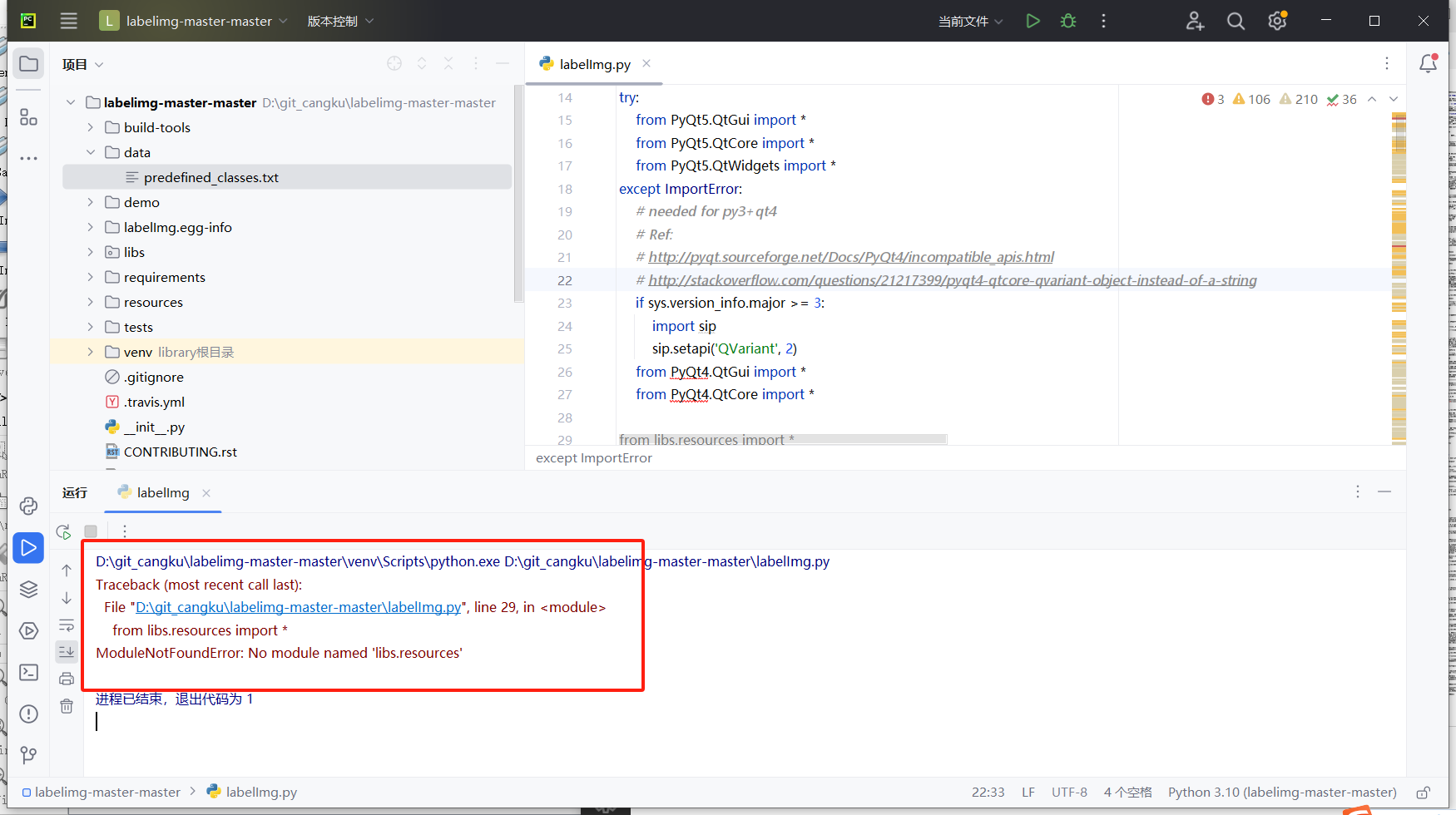
这问题没有解决,我是从github给的资料弄好的,通过虚拟环境那一个,make qt5py3不行,好像没有make这个东西,于是打开了makefile文件手动执行,pyrcc4 -o line/resources.py resources.qrc,然后按步骤来,成功,后面发现这和下面那个方法很像。
运行老是崩溃,重新规范搞一次,还是崩溃,应该要改代码
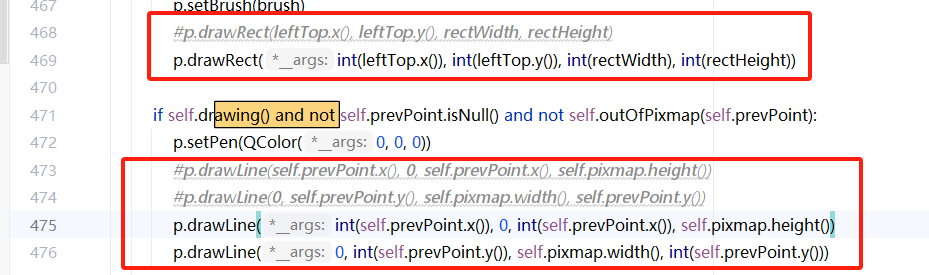
成功
可以开始标记了,但拍摄的图片不太好,重新拍过
标注的时候要吧其他无关的标签删去,否则还是会训练失败。
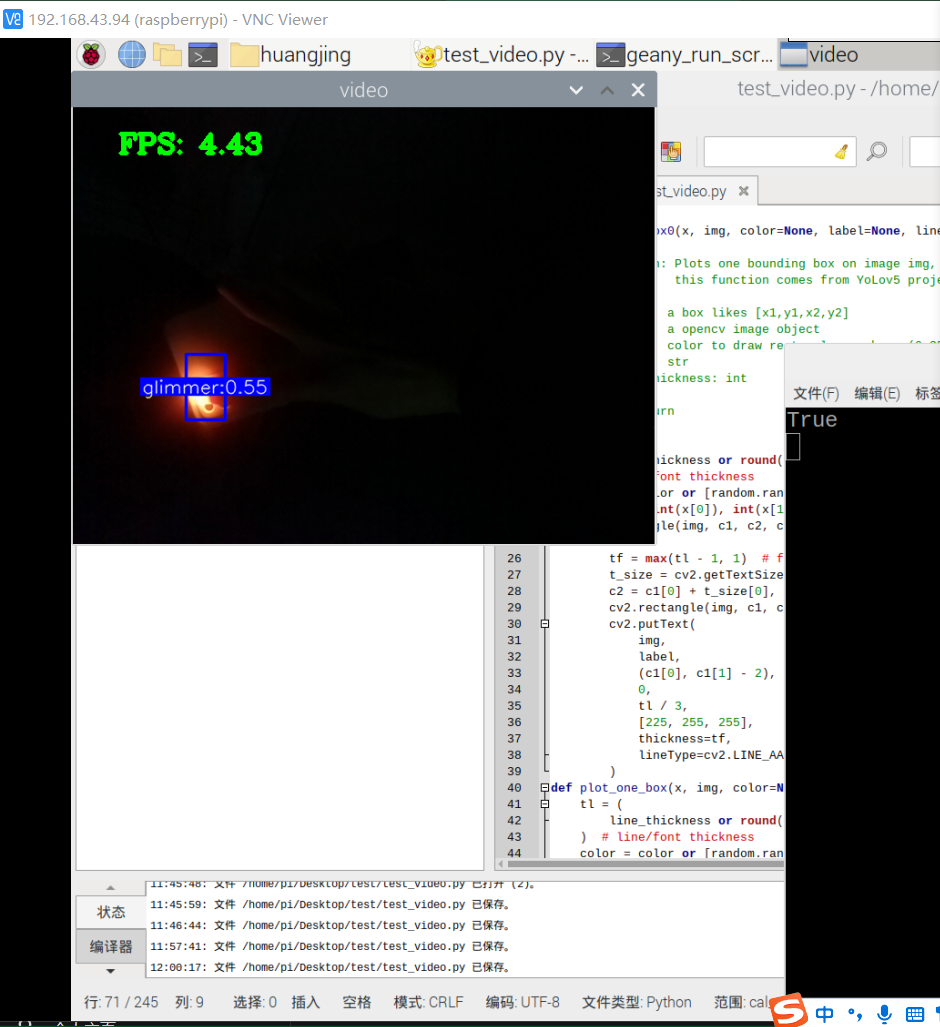
训练成功,部署成功,拍了6张图片识别,成功了一大半,其中有一个识别错了,把手机识别成了书本,有两张没有识别出来书本,或许是因为手有遮挡的缘故,也就是数据集不够好。
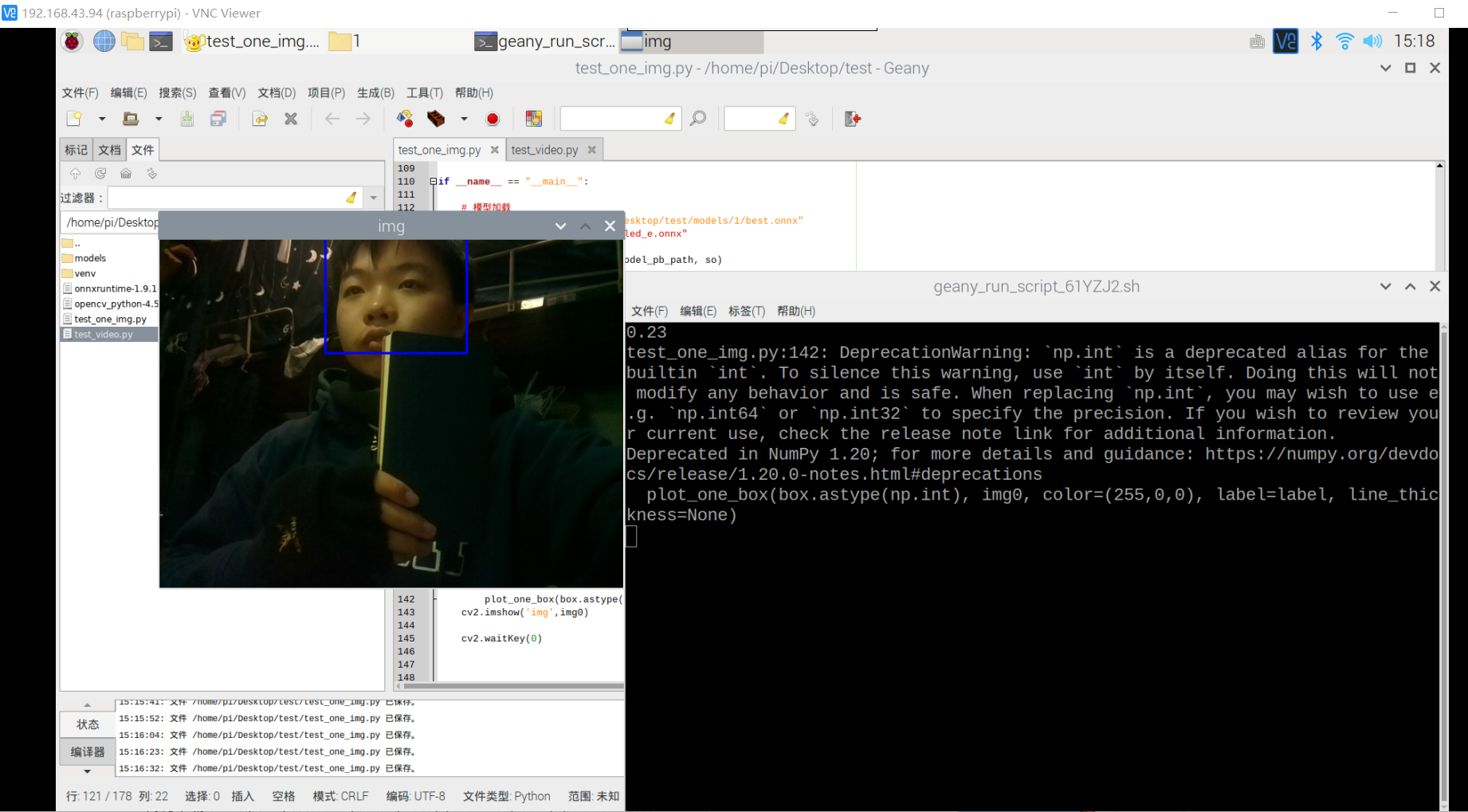
视频也可以识别,但书和手机似乎很混淆,不太行的样子。
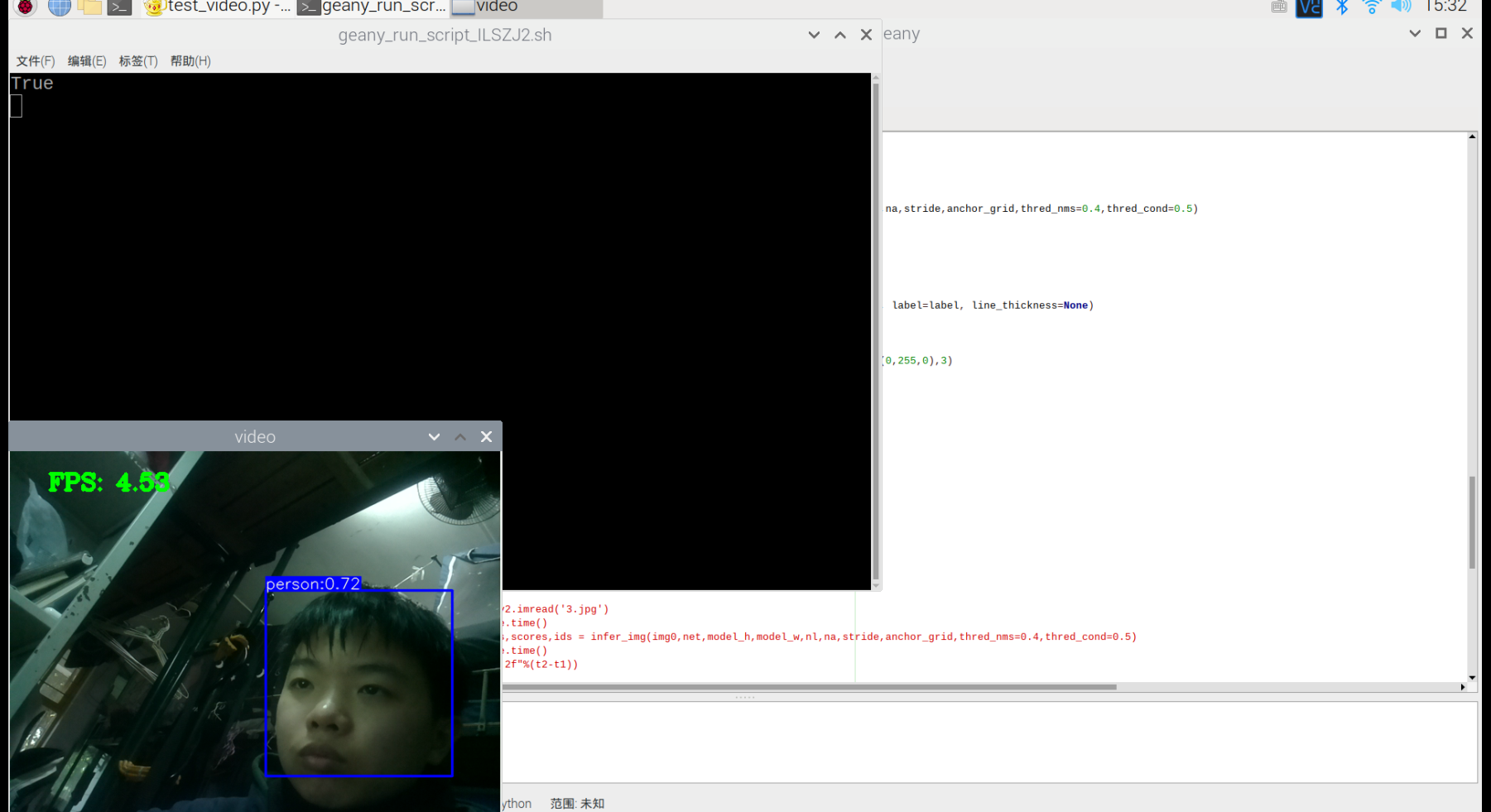
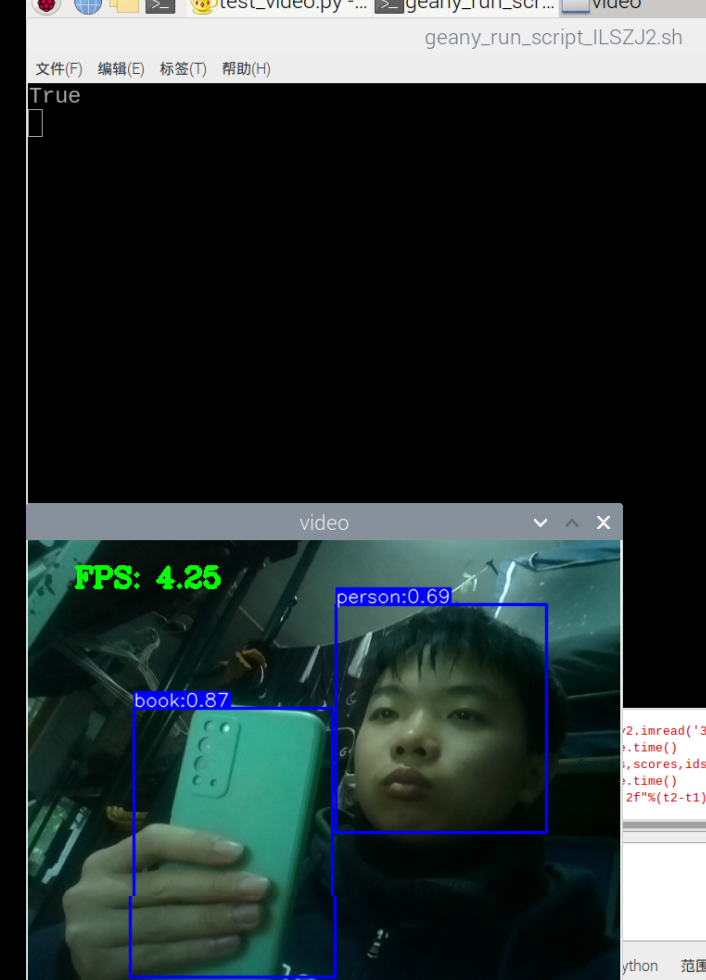
gpu加速2
接下来准备训练大一点的,更好更精确的模型,然后把它部署。首先要面对几个问题: 1.能不能gpu加速 2.能不能弄到合适的数据集
若可以gpu加速的话,那就看你不需要白嫖谷歌的额度了,用自己的电脑训练,若是不能,就只能用一下谷歌的那个了。其次是数据集的问题。要学习找到合适的数据集,然后找到,或者是用混合的数据集,那都是后话了。先尝试gpu加速先。
接着上次的,要开始在python里搭建使用gpu的环境
查阅cuda安装情况,版本为12.3
nvcc -V
https://blog.csdn.net/weixin_64605288/article/details/125705684?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-125705684-blog-89462160.pc_relevant_multi_platform_whitelistv3&spm=1001.2101.3001.4242.1&utm_relevant_index=2
安装torch-2.1.0+cu121-cp310-cp310-win_amd64.whl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import torch
print(torch.cuda.device_count())
print(torch.cuda.is_available())
print(torch.backends.cudnn.is_available())
print(torch.cuda_version)
print(torch.backends.cudnn.version())
结果:
D:\git_cangku\gpu_test\venv\Scripts\python.exe D:\git_cangku\gpu_test\gpu_test.py
D:\git_cangku\gpu_test\venv\lib\site-packages\torch\nn\modules\transformer.py:20: UserWarning: Failed to initialize NumPy: No module named 'numpy' (Triggered internally at ..\torch\csrc\utils\tensor_numpy.cpp:84.)
device: torch.device = torch.device(torch._C._get_default_device()), # torch.device('cpu'),
1
True
True
12.1
8801
torch.cuda.device_count() 输出为 1,意味着您的系统有一个CUDA兼容的GPU设备。这对于运行需要大量并行计算的深度学习模型来说是好消息。
torch.cuda.is_available() 返回 True,表明 PyTorch 能够识别并使用CUDA,这意味着您可以利用GPU加速您的计算任务。
torch.backends.cudnn.is_available() 同样返回 True,表示您的系统安装并配置了cuDNN(CUDA Deep Neural Network library)。cuDNN是由NVIDIA提供的一个库,用于加速深度学习框架的计算,特别是那些涉及到深度神经网络的计算。
torch.cuda_version 和 torch.backends.cudnn.version() 分别显示CUDA和cuDNN的版本号,这里是12.1和8801。这些信息对于确保您的开发环境与您所使用的深度学习库和模型兼容非常重要。
在尝试导入和使用PyTorch时,出现一条警告信息:UserWarning: Failed to initialize NumPy: No module named 'numpy' (Triggered internally at ..\torch\csrc\utils\tensor_numpy.cpp:84.)
这表明Python环境中没有安装NumPy库,或者当前的Python环境无法找到NumPy。
在训练模型环境里安装torch-2.1.0+cu121-cp310-cp310-win_amd64.whl

开始训练,报错
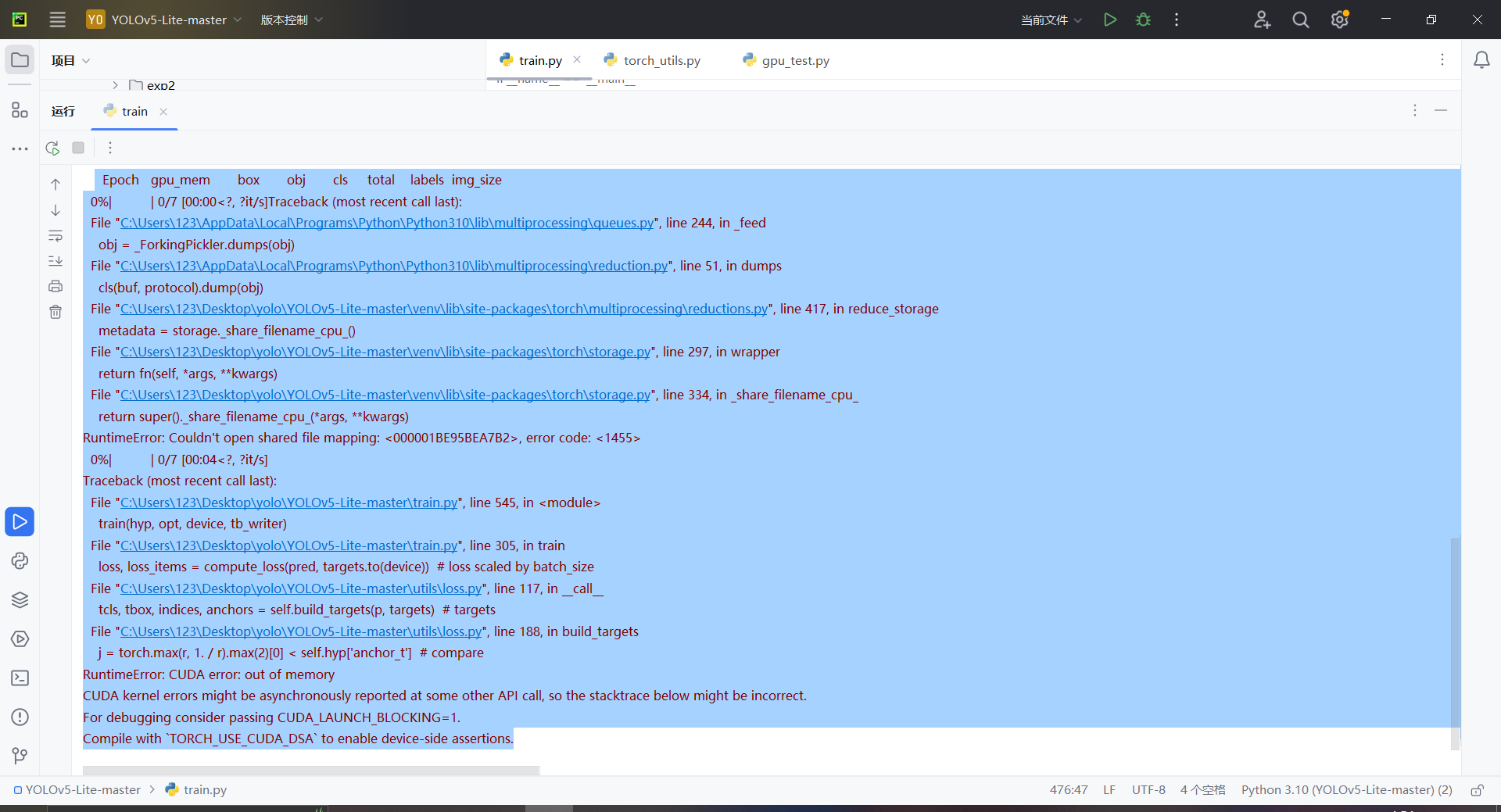
共享内存文件映射错误(Shared Memory File Mapping Error): 这个错误通常与multiprocessing模块和共享内存有关。在Python中,当使用多进程进行数据加载时,通常会使用共享内存来传递数据。然而,出现了一个问题,导致共享内存文件映射失败。这可能是由于环境变量或操作系统限制引起的。
CUDA内存不足(CUDA Out of Memory Error): 在进行训练时,CUDA内存耗尽。这通常发生在模型和/或数据太大,超出了GPU可用内存的情况下。这可能是因为模型太大,批次大小过大,图像尺寸过大等原因导致的。

第二天起来,再次尝试训练一次,居然错误不一样了。
Logging results to runs\train\exp5 Starting training for 300 epochs…
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
Epoch gpu_mem box obj cls total labels img_size
0/299 0.0986G 0.1211 0.02475 0.04159 0.1874 32 320: 100%|██████████| 7/7 [00:15<00:00, 2.15s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 0%| | 0/1 [00:01<?, ?it/s]
Traceback (most recent call last):
File "C:\Users\123\Desktop\yolo\YOLOv5-Lite-master\train.py", line 545, in <module>
train(hyp, opt, device, tb_writer)
File "C:\Users\123\Desktop\yolo\YOLOv5-Lite-master\train.py", line 355, in train
results, maps, times = test.test(data_dict,
File "C:\Users\123\Desktop\yolo\YOLOv5-Lite-master\test.py", line 121, in test
out = non_max_suppression(out, conf_thres=conf_thres, iou_thres=iou_thres, labels=lb, multi_label=True)
File "C:\Users\123\Desktop\yolo\YOLOv5-Lite-master\utils\general.py", line 497, in non_max_suppression
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
File "C:\Users\123\Desktop\yolo\YOLOv5-Lite-master\venv\lib\site-packages\torchvision\ops\boxes.py", line 41, in nms
return torch.ops.torchvision.nms(boxes, scores, iou_threshold)
File "C:\Users\123\Desktop\yolo\YOLOv5-Lite-master\venv\lib\site-packages\torch\_ops.py", line 692, in __call__
return self._op(*args, **kwargs or {})
NotImplementedError: Could not run 'torchvision::nms' with arguments from the 'CUDA' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'torchvision::nms' is only available for these backends: [CPU, QuantizedCPU, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, AutogradMPS, AutogradXPU, AutogradHPU, AutogradLazy, AutogradMeta, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PreDispatch, PythonDispatcher].
CPU: registered at C:\actions-runner\_work\vision\vision\pytorch\vision\torchvision\csrc\ops\cpu\nms_kernel.cpp:112 [kernel]
QuantizedCPU: registered at C:\actions-runner\_work\vision\vision\pytorch\vision\torchvision\csrc\ops\quantized\cpu\qnms_kernel.cpp:124 [kernel]
BackendSelect: fallthrough registered at ..\aten\src\ATen\core\BackendSelectFallbackKernel.cpp:3 [backend fallback]
Python: registered at ..\aten\src\ATen\core\PythonFallbackKernel.cpp:153 [backend fallback]
FuncTorchDynamicLayerBackMode: registered at ..\aten\src\ATen\functorch\DynamicLayer.cpp:498 [backend fallback]
Functionalize: registered at ..\aten\src\ATen\FunctionalizeFallbackKernel.cpp:290 [backend fallback]
Named: registered at ..\aten\src\ATen\core\NamedRegistrations.cpp:7 [backend fallback]
Conjugate: registered at ..\aten\src\ATen\ConjugateFallback.cpp:17 [backend fallback]
Negative: registered at ..\aten\src\ATen\native\NegateFallback.cpp:19 [backend fallback]
ZeroTensor: registered at ..\aten\src\ATen\ZeroTensorFallback.cpp:86 [backend fallback]
ADInplaceOrView: fallthrough registered at ..\aten\src\ATen\core\VariableFallbackKernel.cpp:86 [backend fallback]
AutogradOther: registered at ..\aten\src\ATen\core\VariableFallbackKernel.cpp:53 [backend fallback]
AutogradCPU: registered at ..\aten\src\ATen\core\VariableFallbackKernel.cpp:57 [backend fallback]
AutogradCUDA: registered at ..\aten\src\ATen\core\VariableFallbackKernel.cpp:65 [backend fallback]
AutogradXLA: registered at ..\aten\src\ATen\core\VariableFallbackKernel.cpp:69 [backend fallback]
AutogradMPS: registered at ..\aten\src\ATen\core\VariableFallbackKernel.cpp:77 [backend fallback]
AutogradXPU: registered at ..\aten\src\ATen\core\VariableFallbackKernel.cpp:61 [backend fallback]
AutogradHPU: registered at ..\aten\src\ATen\core\VariableFallbackKernel.cpp:90 [backend fallback]
AutogradLazy: registered at ..\aten\src\ATen\core\VariableFallbackKernel.cpp:73 [backend fallback]
AutogradMeta: registered at ..\aten\src\ATen\core\VariableFallbackKernel.cpp:81 [backend fallback]
Tracer: registered at ..\torch\csrc\autograd\TraceTypeManual.cpp:296 [backend fallback]
AutocastCPU: fallthrough registered at ..\aten\src\ATen\autocast_mode.cpp:382 [backend fallback]
AutocastCUDA: fallthrough registered at ..\aten\src\ATen\autocast_mode.cpp:249 [backend fallback]
FuncTorchBatched: registered at ..\aten\src\ATen\functorch\LegacyBatchingRegistrations.cpp:710 [backend fallback]
FuncTorchVmapMode: fallthrough registered at ..\aten\src\ATen\functorch\VmapModeRegistrations.cpp:28 [backend fallback]
Batched: registered at ..\aten\src\ATen\LegacyBatchingRegistrations.cpp:1075 [backend fallback]
VmapMode: fallthrough registered at ..\aten\src\ATen\VmapModeRegistrations.cpp:33 [backend fallback]
FuncTorchGradWrapper: registered at ..\aten\src\ATen\functorch\TensorWrapper.cpp:203 [backend fallback]
PythonTLSSnapshot: registered at ..\aten\src\ATen\core\PythonFallbackKernel.cpp:161 [backend fallback]
FuncTorchDynamicLayerFrontMode: registered at ..\aten\src\ATen\functorch\DynamicLayer.cpp:494 [backend fallback]
PreDispatch: registered at ..\aten\src\ATen\core\PythonFallbackKernel.cpp:165 [backend fallback]
PythonDispatcher: registered at ..\aten\src\ATen\core\PythonFallbackKernel.cpp:157 [backend fallback]
NotImplementedError: Could not run ‘torchvision::nms’ with arguments from the ‘CUDA’ backend. This could be because the operator doesn’t exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. ‘torchvision::nms’ is only available for these backends: [CPU, QuantizedCPU, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, AutogradMPS, AutogradXPU, AutogradHPU, AutogradLazy, AutogradMeta, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PreDispatch, PythonDispatcher].
NotImplementedError:无法使用来自“CUDA”后端的参数运行“torchvision::nms”。这可能是因为此后端不存在运算符,或者在选择性/自定义生成过程中被省略(如果使用自定义生成)。如果您是在移动设备上使用 PyTorch 的 Facebook 员工,请访问 https://fburl.com/ptmfixes 了解可能的解决方案。’torchvision::nms’ 仅适用于以下后端: [CPU、QuantizedCPU、BackendSelect、Python、FuncTorchDynamicLayerBackMode、Functionalize、Named、Conjugate、Negative、ZeroTensor、ADInplaceOrView、AutogradOther、AutogradCPU、AutogradCUDA、AutogradXLA、AutogradMPS、AutogradXPU、AutogradHPU、AutogradLazy、AutogradMeta、Tracer、AutocastCPU、AutocastCUDA、FuncTorchBatched、FuncTorchVmapMode、Batched、VmapMode、FuncTorchGradWrapper、PythonTLSSnapshot、FuncTorchDynamicLayerFrontMode、PreDispatch, PythonDispatcher].
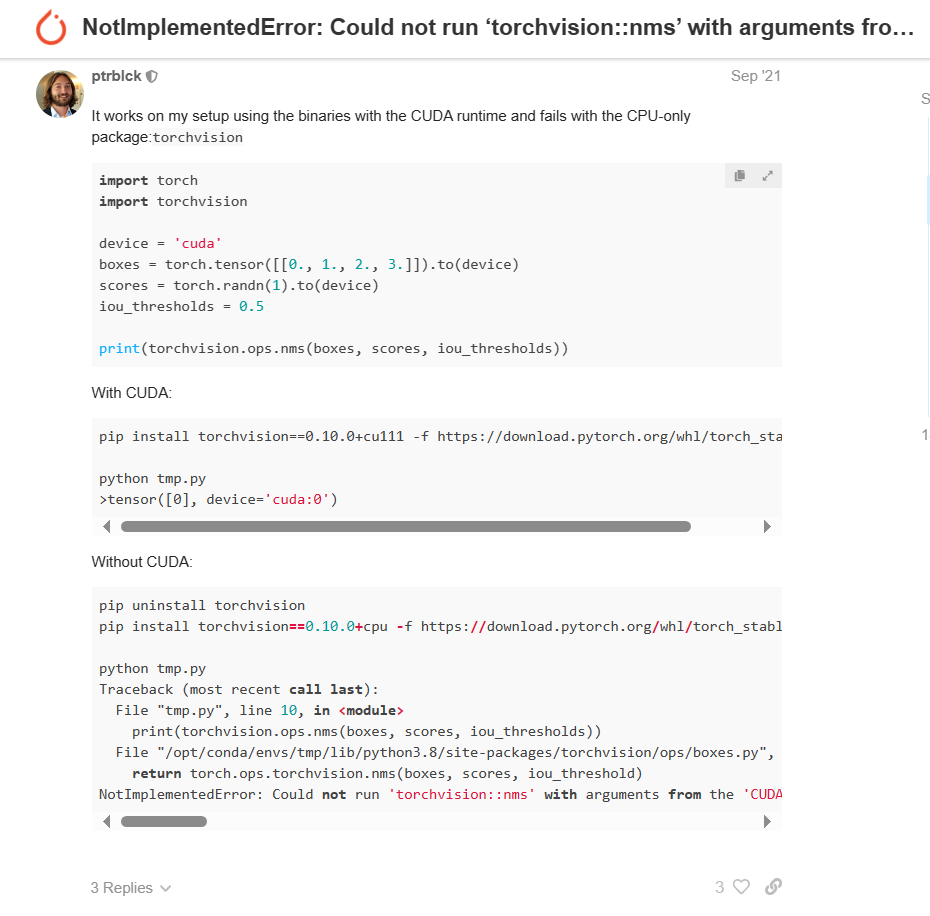
看不上很懂,对给gpt解释一下:
1
2
3
4
5
6
这个问题说明在你的设置中,当使用支持CUDA的torchvision版本时,torchvision.ops.nms能够在GPU上正确执行。然而,当你卸载带CUDA支持的torchvision并安装了仅支持CPU的版本后,尽管你的代码尝试在CUDA设备上执行相同的操作,你遇到了NotImplementedError错误。
这里的关键在于torchvision包和CUDA支持的关系。torchvision有不同的构建版本,一些版本包括了对CUDA的支持,而另一些则仅支持CPU。当你尝试在一个仅支持CPU的torchvision版本上执行一个需要CUDA支持的操作时(比如在GPU上执行nms),你会遇到错误,因为该操作尝试在一个不支持的后端(在这种情况下是CUDA)上执行。
解释错误消息
错误消息是说torchvision::nms操作无法在'CUDA'后端上运行,因为这个操作对于'CUDA'后端来说不存在或在自定义/选择性构建过程中被省略了。消息还提到了'torchvision::nms'只对这些后端可用:[CPU, QuantizedCPU, BackendSelect, Named, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, UNKNOWN_TENSOR_TYPE_ID, AutogradMLC, Tracer, Autocast, Batched, VmapMode]。这个列表显示了哪些后端支持nms操作,但如果你安装的是CPU-only版本的torchvision,尽管列表中提到了AutogradCUDA,实际上在尝试执行GPU相关操作时,你仍然会遇到问题。
解决方案
如果你需要在GPU上执行操作(如nms),确保安装了支持CUDA的torchvision版本。你可以根据你的CUDA版本来安装合适的torchvision和torch包。从你提供的命令来看,你已经知道如何为特定的CUDA版本安装正确的torchvision:
我安装了GPU版本的torch,但没有安装gpu版本的torchvision
https://github.com/ultralytics/ultralytics/issues/5059 这里也说了应该是torchvision的问题,社区氛围真的友善,且规范,问个问题都要有最小可复现的模型,瞻仰大佬
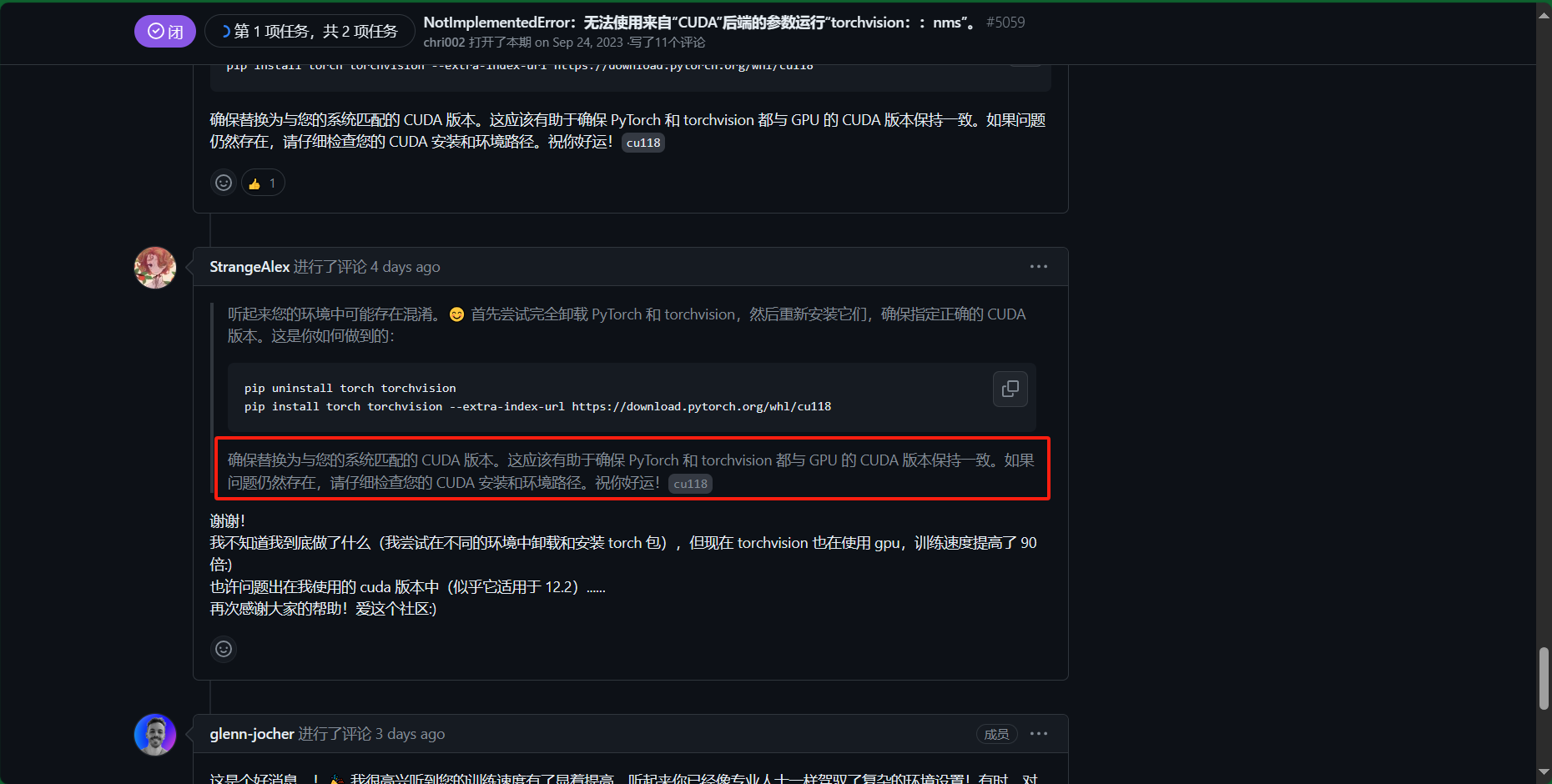
根据https://blog.csdn.net/shiwanghualuo/article/details/122860521
得出:torch:2.1 torchvision:0.16 python:>=3.8, <=3.11
下载torchvision-0.16.0+cu121-cp310-cp310-win_amd64.whl,似乎也可以用命令:pip install torchvision==0.16.0+cu121 -f https://download.pytorch.org/whl/torch_stable.html
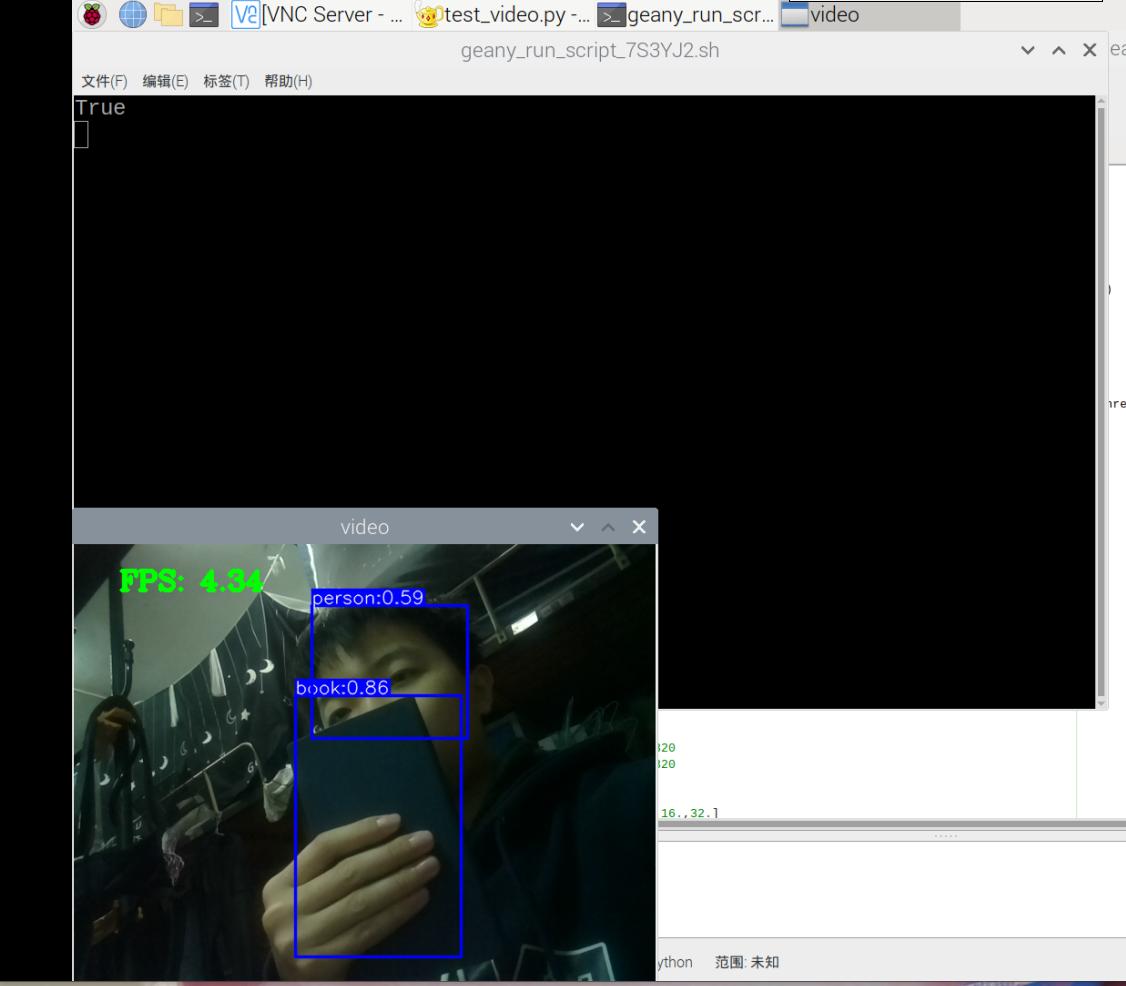
每一步都踏在将要放弃的路上,这个总是让我感觉弄不出来,每次尝试都像是在向老天祷告一般。不过还是成功了,训练速度快了n倍,大概只需要10分钟左右,先前都需要个把小时的。这种感觉,爽
训练出来的模型可以用,不过还是那么不准确,书和收集傻傻分不清,可能是数据集里面的这两个东西有一半的部分被手遮挡了的缘故。
总结: 1.gpu只能帮助分析,特别是gpt3.5,用的都是过时的资料库,或许可以下载些插件什么的,查一些偏的深的bug还得是社区谷歌才行。 2.工科或许都是这样了,每天都会遇到bug,有时甚至想要放弃,换个方法,但还是得边分析,边搜索,必要时求助他人。何以平衡坚持还是放弃、换个方法。坚持不一定能成功,但放弃换个方法也不一定顺畅,总之要有一定的深度后,要有一定的思考和搜索深度后,还是不行,就可以考虑一下求助他人,或是换个方法。浅浅的思考频繁的换方法不可取
实验过程3
接下来的目标就是训练更好更精确的模型了
方法: 1.数据质量和数据增强:收集更多更好数据、数据增强 2.精细调整训练过程:学习率调整、简化问题 3.模型评估与迭代:持续迭代、测试和反馈
步骤一:先选择更合适的数据集,然后训练大一点的模型,然后部署 步骤二:选择更多更合适的数据集,尝试学习在谷歌在线训练更大的模型,然后把它部署。 步骤三:学习精细调整训练过程、学习模型评估与迭代
每当我感受到有压力,没信心做好的时候,总是会拖拖拉拉,无效工作麻痹自我,甚至会逃避,这时候更要做,更要劳动,这很重要。
如何收集和选择合适数据集 https://zhuanlan.zhihu.com/p/55364815
- Kaggle数据集
一脸懵,了解一下分类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
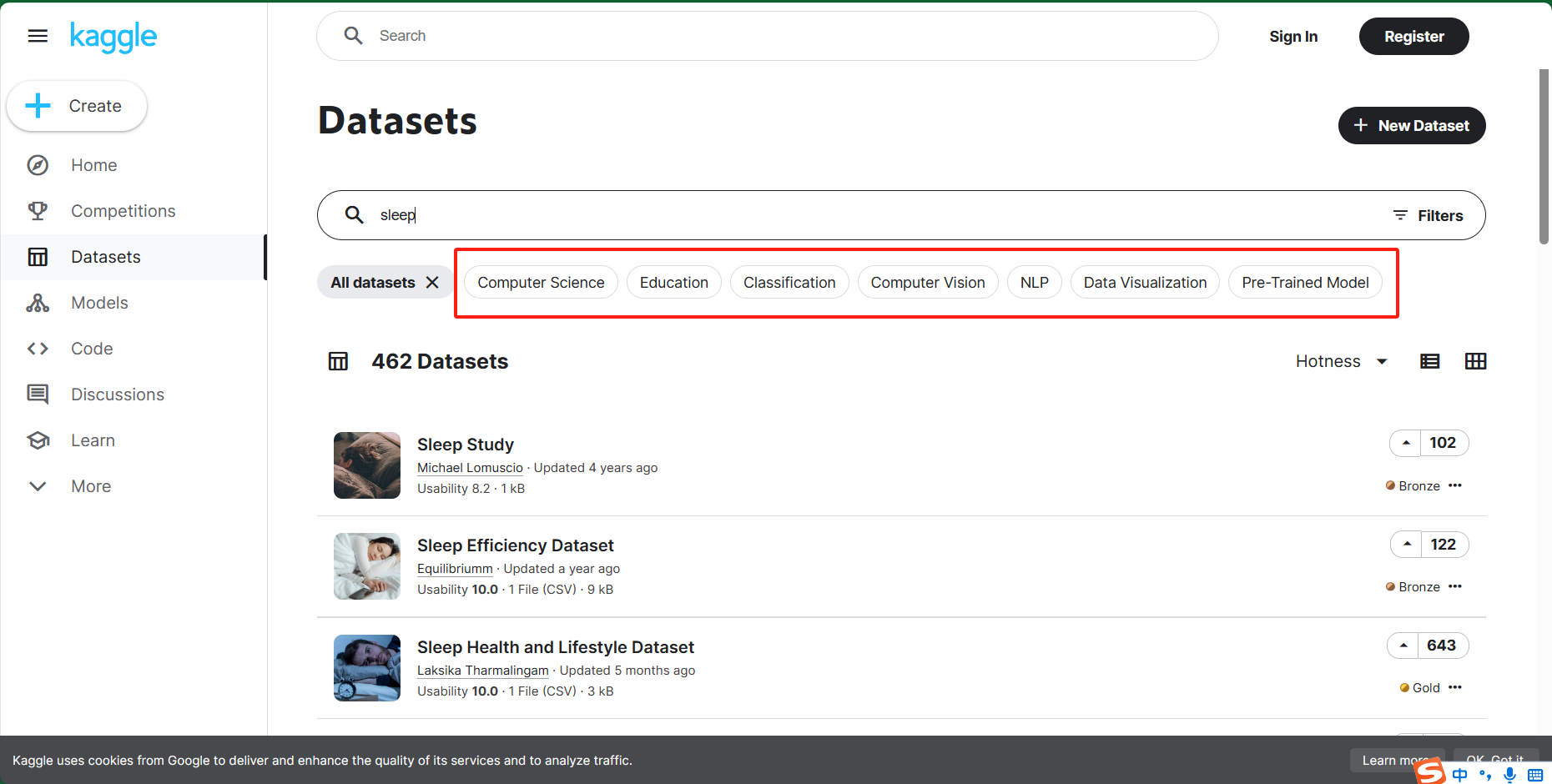
当你在 Kaggle 上浏览数据集时,这些分类代表不同类型的数据集。让我为你解释一下每个类别的含义,并帮助你选择适合目标检测的数据集:
1.Computer Science:
这个分类包含与计算机科学相关的数据集。这可能涵盖了各种主题,例如算法、编程、网络、数据库等。
如果你对计算机科学领域的目标检测感兴趣,你可以查找与计算机视觉相关的数据集。
2.Education:
这里的数据集与教育领域有关。它们可能包括学生表现、教育资源、学校评估等方面的数据。
对于目标检测,这些数据集可能不太适合你的需求。
3.Classification:
分类数据集用于将数据分成不同类别。每个样本都有一个预定义的标签。
如果你想要训练一个目标检测模型,你可能需要更详细的标注,例如边界框。
4.Computer Vision:
这个分类包含与计算机视觉相关的数据集。这些数据集通常包含图像和标注,适合目标检测任务。
你可以在这里寻找人在床上状态的图像数据集。
5.NLP (Natural Language Processing):
NLP 数据集与自然语言处理相关。这些数据集包含文本、语言模型、情感分析等。
对于目标检测,这些数据集不太适合。
6.Data Visualization:
这里的数据集通常用于创建图表、图形和可视化。它们不适合目标检测。
7.Pre-Trained Model:
这个分类通常不是数据集,而是预训练的模型权重。你可以使用这些权重来初始化你的目标检测模型。
基于你的需求,我建议你在 Kaggle 中搜索与“人在床上状态”、“睡眠”、“玩手机”和“看书”相关的数据集。你可以在计算机视觉分类中查找适合的数据集,然后开始训练你的目标检测模型。
Computer Vision、Computer Science
IEEE VIP CUP 2021 数据集:https://www.kaggle.com/datasets/awsaf49/ieee-vip-cup-2021-train-val-dataset 这是挑战赛的数据集,大致是关于睡姿检测的,仰卧、左卧和右卧等 3 个一般类别中做出 15 个姿势。不太适合
我感觉找到合适的数据集可能比较困难,特别是合适的,特别在自己的需求还不是很明确的时候。
需求:状态检测(判断睡眠、玩手机、看书) 分析: 我需要的是一个摄像头,对准了床头。 首先是识别是否处于睡眠状态,其指标有两个,是否开着灯,若没有开灯,则默认睡眠,开着灯的话,若是人脸上的眼睛处于闭合状态,并且还躺着什么都不干很久,则处于睡眠状态。 接着是判断是否在玩手机、是否在看书。其指标是什么,不在于是躺着还是坐着,关键在于手上的东西是什么,是书本,还是手机,通过识别手中书本,手机来初略判断。
但有一些问题,人在睡眠时,开着灯,正面躺着,很容易识别出来,但侧躺着,就不容易,侧躺着玩手机,可能也会玩着玩着就睡着了,然后手机就搁在手边,手机甚至都不会息屏。
这就是平衡难度和舒适度的问题了。从一个健康的角度来看,判断睡眠状态,就只需要识别有没有灯源,全黑环境肯定是睡眠,若是全黑环境里手机在发光,则这个状态不对,直接播报,也有可能会误伤。若是完全没有关灯,那更要播报了。。。。
关键在于不播报的条件是什么,是睡着了,还是以健康的方式睡着了。 后者只需要识别环境是否是完全黑暗的条件。 前者的话,开不开的,有没有手机,有没有书本,侧躺着,正躺着,都可能会睡着。对于玩着玩着睡着的情况,如何判断是睡着了,还是还在玩手机。
或许单靠目标检测很难识别是否处于睡眠状态。
1
2
3
4
5
或许可以这样,到点,摄像头检测
环境全黑——》睡着
环境全黑仍有光源——》提醒容易得青光眼
环境开灯——》识别——》看书学习(播报)
——》玩手机(播报)
我能不能找到合适的数据集。就只关于看书学习和玩手机。 如何寻找这数据集的关键词。在床上,看书,玩手机。 在床上这个环境是必要的吗? 可能是不必要的,在其他环境的话,像是在沙发上,在椅子上,都是坐着,判断看书还是手机,这样的数据集可能找得到。这些环境的人都是坐着的。 而在床上的话,还有一种可能是躺着,侧躺着看书。
所以,不但要找到坐着看书的数据集,还要找一些躺着看书玩手机的数据集。两者结合在一起,构成床上这个环境。
接下来做的,首先是要找到看书,和玩手机这类似的数据集,完成坐着的情况识别的模型。测试一下这个模型在床上使用的效果,是不是能够将坐着时玩手机和看书识别出来。 然后增加一些躺着的玩手机和看书的数据集。训练出模型,测试一下能不能识别坐着和躺着的状态。
步骤一:完成坐着的识别模型(识别黑暗、光源不足————》识别坐着时看书、玩手机) 步骤二:增加躺着的数据集,训练模型。(识别黑暗、光源不足————》识别坐着、躺着时看书、玩手机)
逻辑: 黑暗环境、有一点光源的环境和明亮环境,若是在明亮环境,则进一步识别在看书还是在玩手机 这是两层的识别,需要的是一个模型还是两个模型。若是一个模型,那数据集又是长什么样的。
得问一下老师才行。
结果:分成两步、甚至是三步。先识别环境信息、留下光明环境的标签,然后识别躺着坐着,然后分别识别玩手机,看书。
先完成第一个识别:识别环境(黑暗、有一点光源、明亮)
数据集准备
拍摄两百张环境的照片,并进行标注
黑暗环境: 在完全黑暗的情况下,你可以使用虚拟标注来表示这一状态。虚拟标注是指在没有实际目标的情况下,为图像添加一个标注框。 你可以在图像中随机选择一个区域,然后用标注工具(如LabelMe)创建一个虚拟的标注框,表示这是一个黑暗环境。
有一点光源的环境: 对于有一点光源的环境,你已经知道如何标注了。使用LabelMe或类似的工具,将光源所在的区域框起来,并添加相应的标签。
明亮环境: 在明亮环境下,你可以选择标注整个图像,因为没有需要特别关注的目标。 使用标注工具,将整个图像框起来,并添加“明亮环境”或类似的标签。
上网找了一会,很难找到相应的数据集。还是用树莓派拍照,100张黑暗、10张有一点光源、100张明亮条件
训练部署结果: 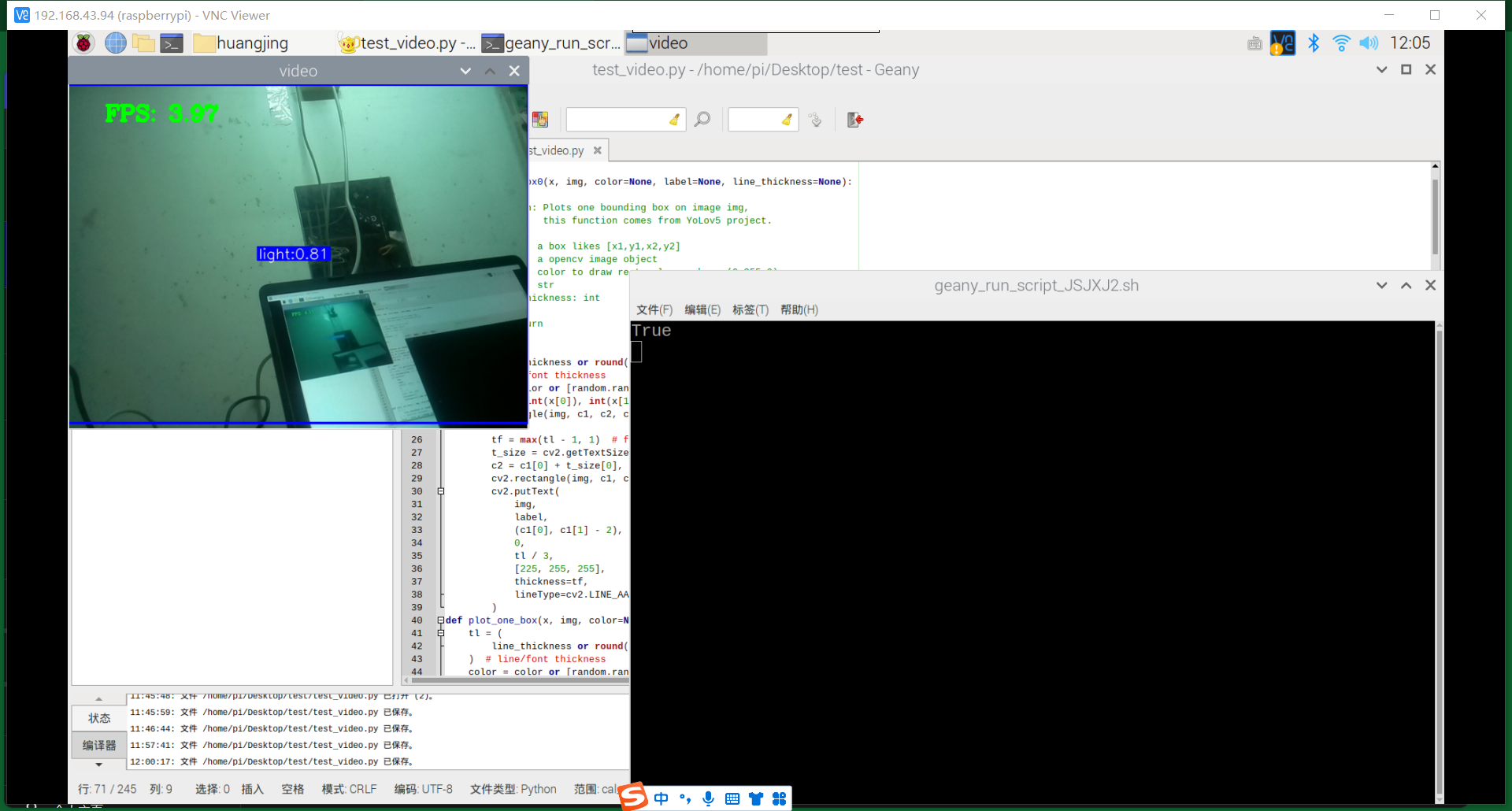
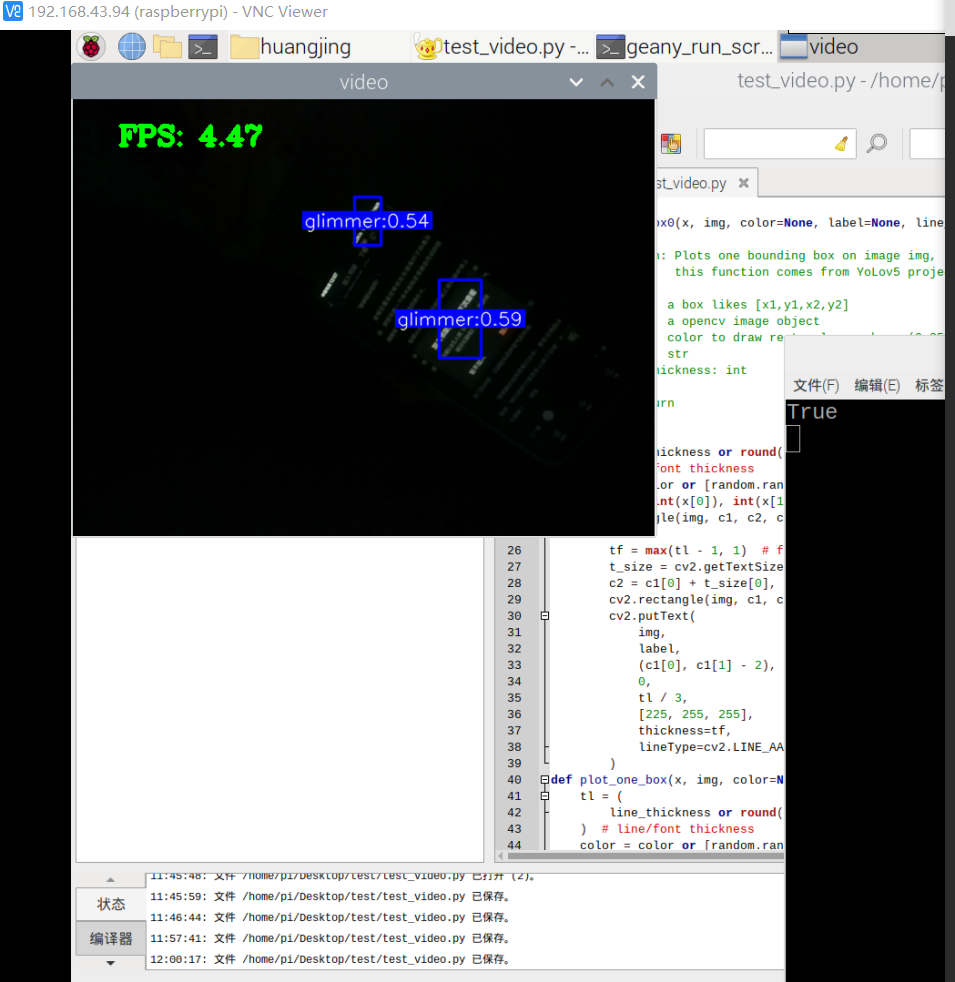
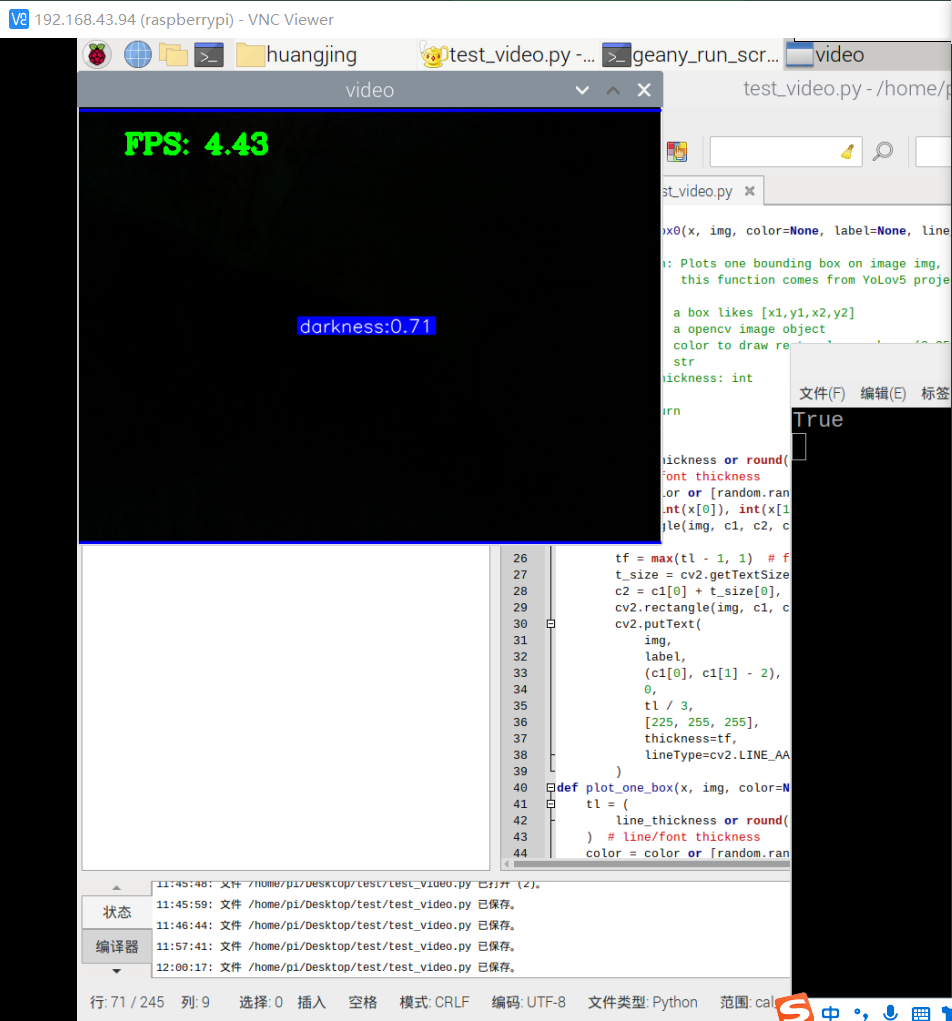
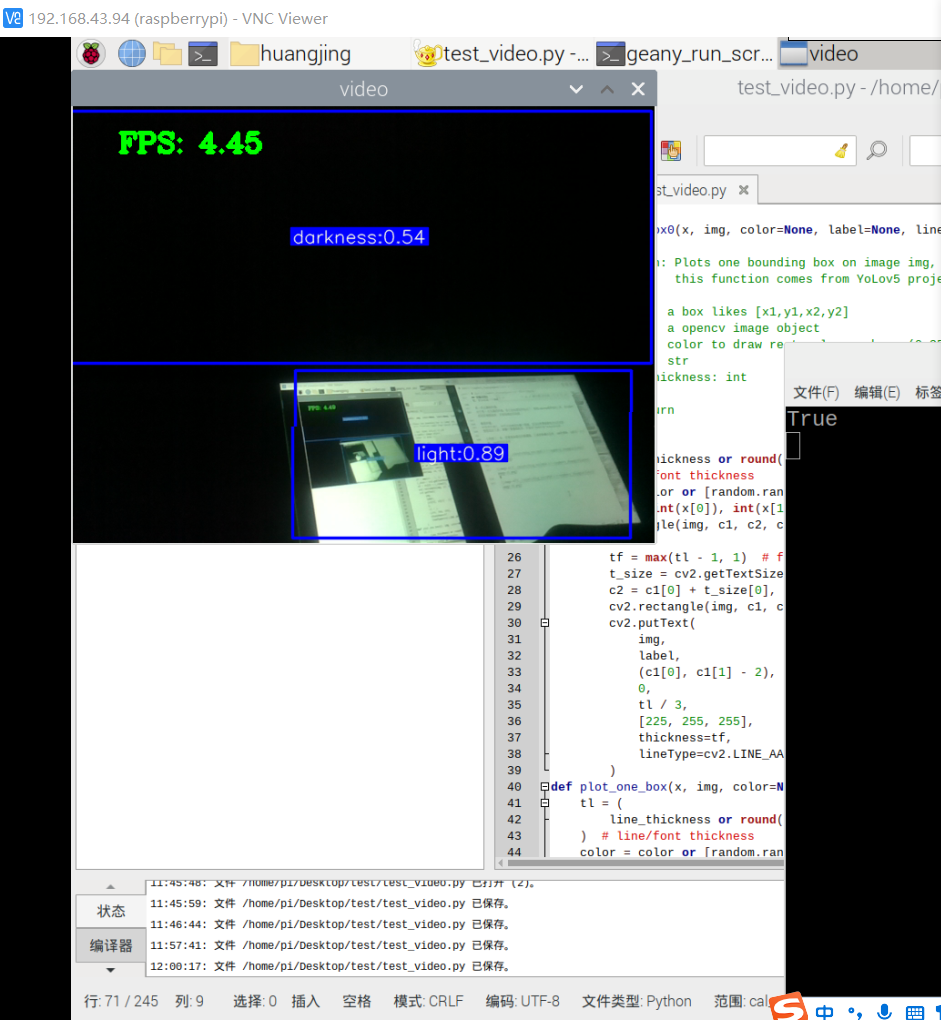
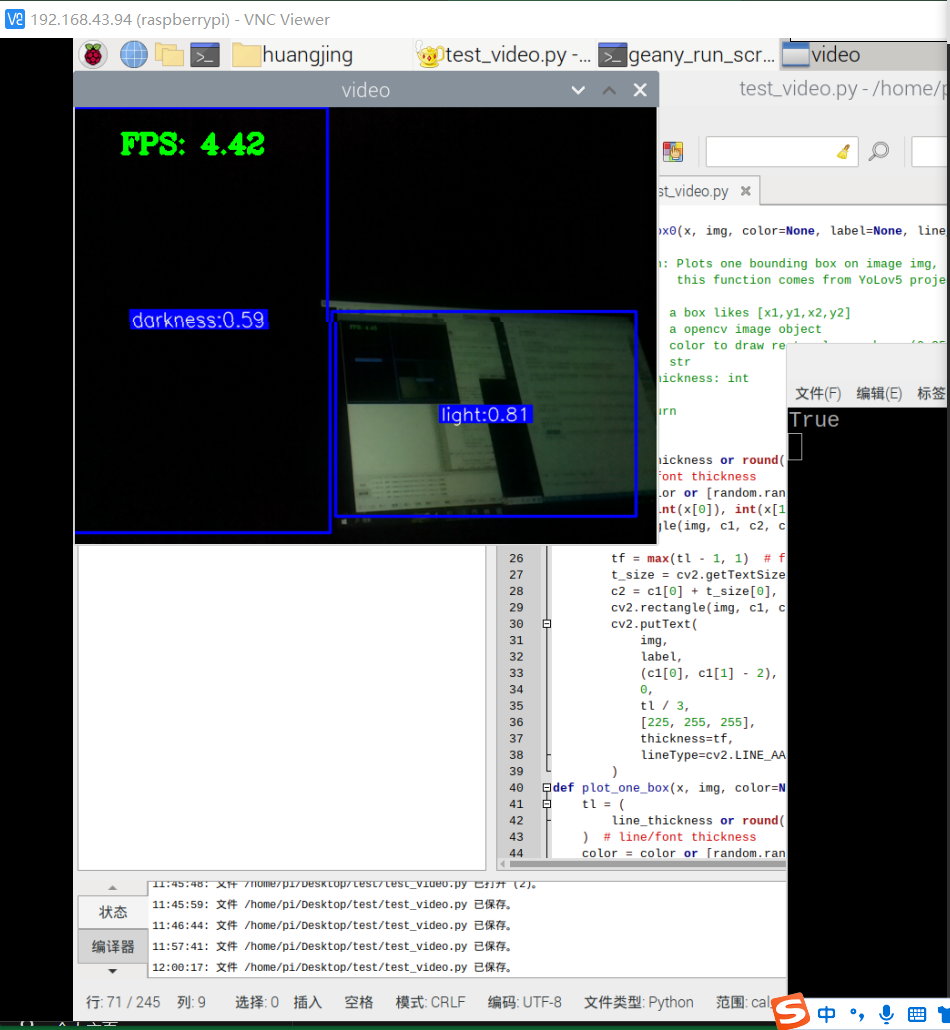
基本能用,对于有三者的情况基本能够识别,但准确率有待提高。而对于大片的光源,像是电脑,则难以分辨是明亮还是有一丝光亮。后续有待提高。
接下来就是在明亮状态下,识别玩手机和看书的状态,这两个状态可能会有很多个姿势,像是侧躺,正躺,坐着,可以在这三个姿势下识别玩手机和看书。
首先,先确认能否使用非树莓派拍摄的图片进行模型的训练,学会使用其他形式的照片训练模型,然后,对上面一个模型进行识别的成功率进行分析判断,若是可能性比较高,则尝试,不行就展开进行更深层度的学习。
收集20多张的图片,标注,拿去训练,发现难以收集jpg格式的图片,还是得学习爬取图片
实验过程4
学习爬取图片,制作数据集 训练模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import os
import requests
def download_image(url, save_path):
try:
response = requests.get(url)
if response.status_code == 200:
with open(save_path, 'wb') as f:
f.write(response.content)
print(f"Image saved at {save_path}")
else:
print(f"Failed to download image from {url}")
except Exception as e:
print(f"Error: {e}")
def main():
image_url = "https://example.com/image.jpg" # Replace with the actual image URL
save_directory = "path/to/save/images" # Replace with your desired local directory
if not os.path.exists(save_directory):
os.makedirs(save_directory)
image_name = os.path.basename(image_url)
save_path = os.path.join(save_directory, image_name)
download_image(image_url, save_path)
if __name__ == "__main__":
main()
大致原理的:批量获取jpg的url路径,然后用request获取数据直接下载,然后用os或是ultil保存。试了一会,发现同样效率不高,bing和baidu似乎都有反爬虫的防御,爬取的都是重复的东西。而且爬取,手动收集的图片良莠不齐,奇奇怪怪的还不如自己拍的。质量得不到保证 还是去csdn上买比较快。现在一个小时大约值20块,可以接收用5块钱换15分钟的交易。可以分开买看书和玩手机的数据集 csdn依旧是那么恶心,居然是付费资源,要90多,服
在https://aistudio.baidu.com/datasetdetail/105315/0下载play_phone的数据集
1
2
3
4
5
6
7
如何使用谷歌英文搜索资料,
为了获取关于读书状态的图像数据集,你可以使用一系列英文关键词进行搜索。由于你的目标是训练一个能够识别读书状态的YOLOv5模型,你需要找到包含各种读书场景的图像,比如在不同环境中阅读、使用不同姿势阅读等。以下是一些建议的搜索关键词:
"Reading posture dataset":搜索关于阅读姿势的数据集,这可能会包括坐着、躺着或站着阅读的图片。
"Book reading dataset":这个搜索可以提供更广泛的关于阅读书籍的场景图片,可能包括不同年龄和背景的人。
"People reading dataset":这个关键词组合更加泛化,能找到各种人阅读的场景,不局限于特定的姿势或环境。
"Reading images dataset":这是一个通用的搜索,旨在找到包含阅读活动的图片数据集。
"Educational reading dataset" or "Academic reading dataset":如果你想要的数据集更偏向于教育或学术场景,这些搜索词可能会更有帮助。
不应该啊,找不到。或许关键词不太对
又找了一个小时,看来是不能直接用关键词直接寻找到看书的数据集了,也可能是我不会用英文关键词。或许我应该学习一下外国人是怎么搜索资料的了。
开一个专题,边学习边记录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
我要做一个yolo模型,需要数据集,关于阅读的,识别人是否在看书学习。这个的数据集应该怎么搜索,给我5个中文关键词、5个英文关键词、5个日文关键词
中文关键词:
阅读行为数据集
人在看书学习的图像数据
阅读姿势识别数据集
学习行为图像数据
人在阅读时的目标检测数据集
英文关键词:
Reading behavior dataset
Images of people reading and studying
Reading posture recognition dataset
Learning behavior images
Object detection dataset for reading activities
日文关键词:
読書行動データセット
人々が読書や勉強をしている画像
読書のポーズ認識データセット
学習行動の画像
読書活動の物体検出データセット
intitle:”阅读*数据集” “目标检测” https://blog.csdn.net/FL1623863129/article/details/136298888
阅读 OR 看书 OR 学习 目标检测 “数据集”(20700000条) https://tianchi.aliyun.com/dataset/ 学生课堂行为检测:SCB-dataset3 识别书:https://kylinhx.gitee.io/2023/03/12/ObjectDetectionDatasetsSurey/
目标检测和行为识别是两码事,或许都可以用一个模型实现,但太麻烦了,改为识别书籍:https://tianchi.aliyun.com/dataset/141479?t=1710578284771
现在有了phone和book的txt文件,连的id都为0,使用代码将book的id全部都改为1,然后class.txt;play_phone,book
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import os
# 指定目录路径
directory_path = r"D:\git_cangku\data\book\val"
# 获取目录中所有的.txt文件
txt_files = [f for f in os.listdir(directory_path) if f.endswith(".txt")]
# 遍历每个.txt文件并进行修改
for txt_file in txt_files:
file_path = os.path.join(directory_path, txt_file)
with open(file_path, "r") as f:
content = f.read()
# 将每行的第一个0替换为1
modified_content = "\n".join(line.replace("0 ", "1 ", 1) for line in content.splitlines())
# 将修改后的内容写回文件
with open(file_path, "w") as f:
f.write(modified_content)
print(f"All .txt files in {directory_path} have been updated.")
快7000张的数据集,10h以上。挺久的,希望一切顺利
跑了接近6个小时的时候,快一般的时候,看电脑时,发现pycham直接关闭了,没了。正好晚上,重新跑过,看看能不能成功。不能的话,就只能分析一下原因了,再不行用谷歌额度来跑。
跑了12个小时,部署好,发现效果不好。
结果: 1.图片检测,部分图片会出现满图片的框框,被全部覆盖,且置信度接近于0(可能是因为图片上有什么防伪的技术吧) 2.图片检测,书本很容易就检测出来(可能是因为书本的数据集不太好,没有经过挑选) 3.视频检测,玩手机这个行为很难检测出来(可能与玩手机的数据集不太好有关,所用的数据集都是行人拿着手机,然后大多都是打电话,很少玩手机)
解决: 1.用多样的标准的图片和视频测试,记录测试结果 2.在电脑上部署模型,再用上面的进行测试。 3.对数据集进行挑选 4.了解yolov5-lite模型训练一般用多少图片,如何规范的训练。
我觉得,应该是书本的数据集太差了,影响了手机的识别,先用1000张图片训练一下手机识别的模型,再然后用1000张训练书本识别的模型,分别测试一下两个模型。当两个都调试好后,再弄成一个模型。
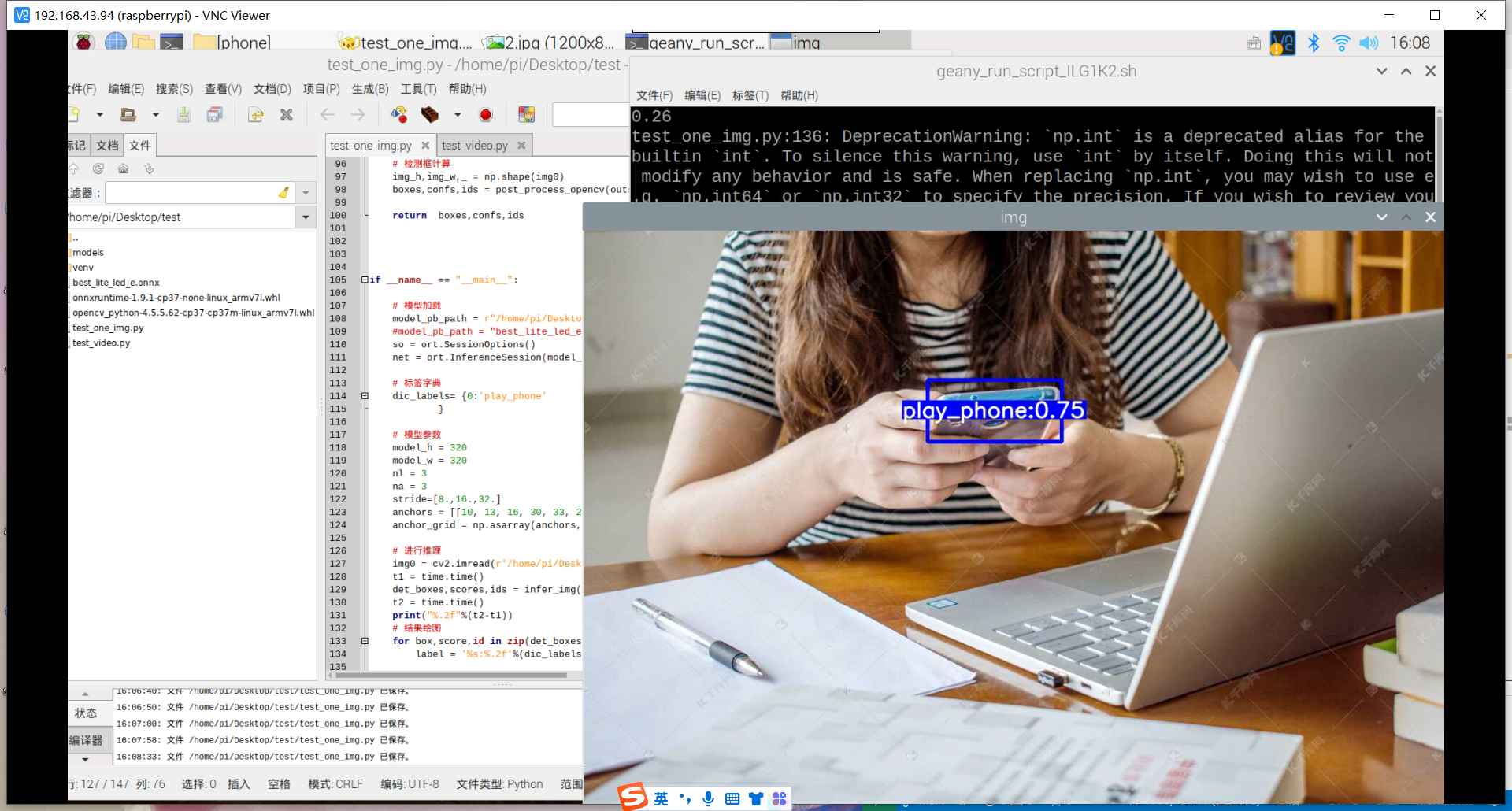
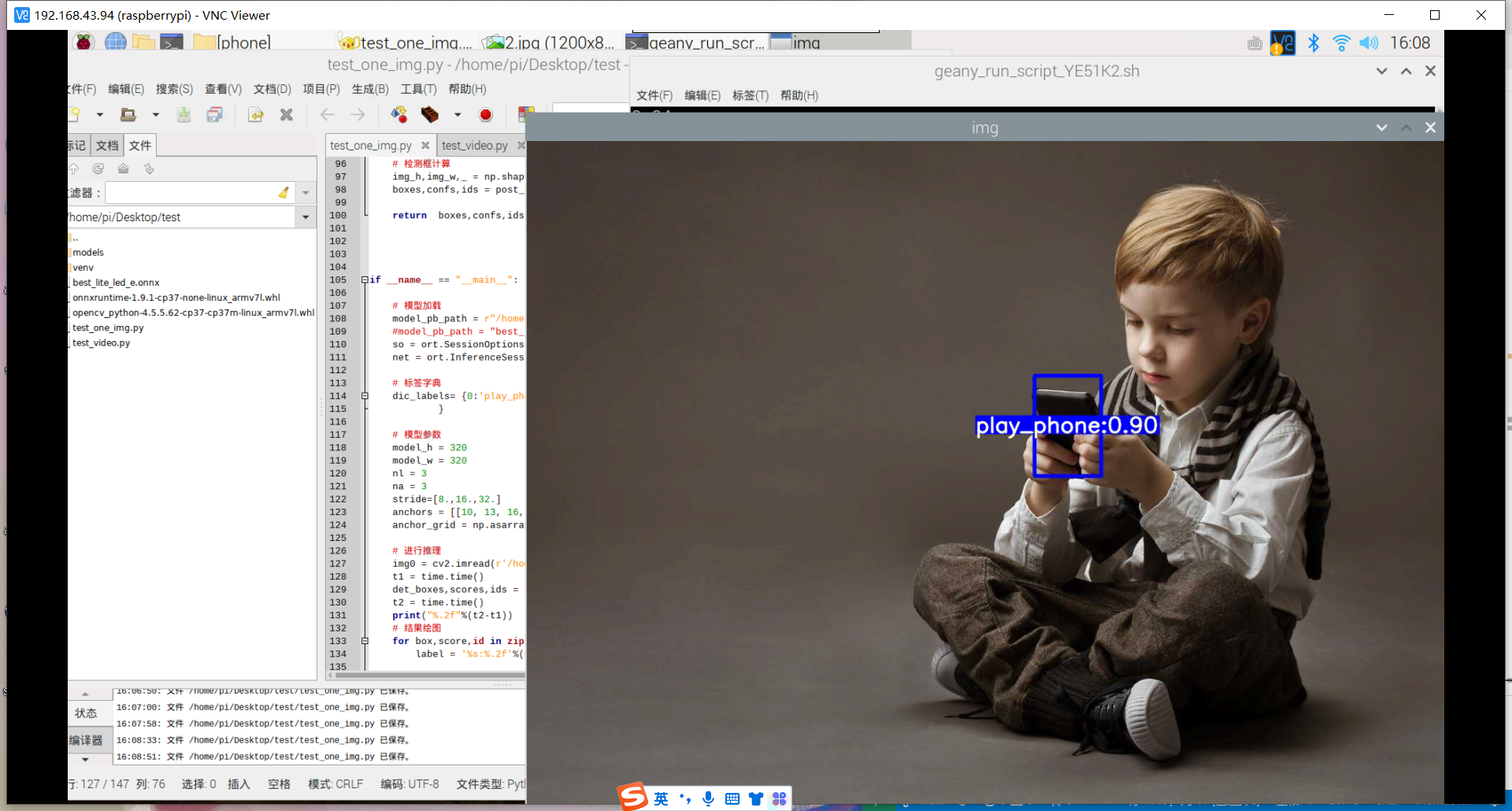
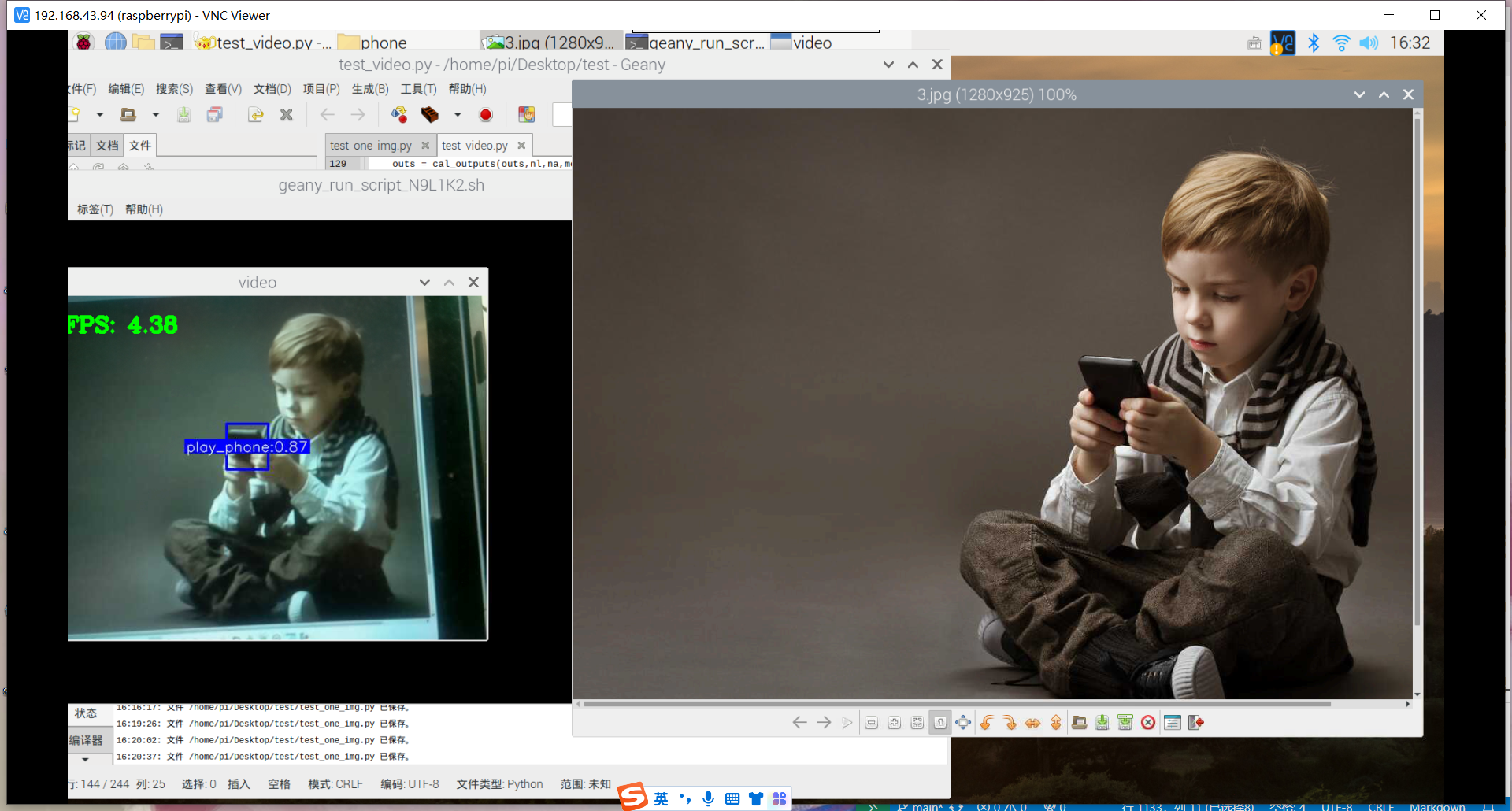
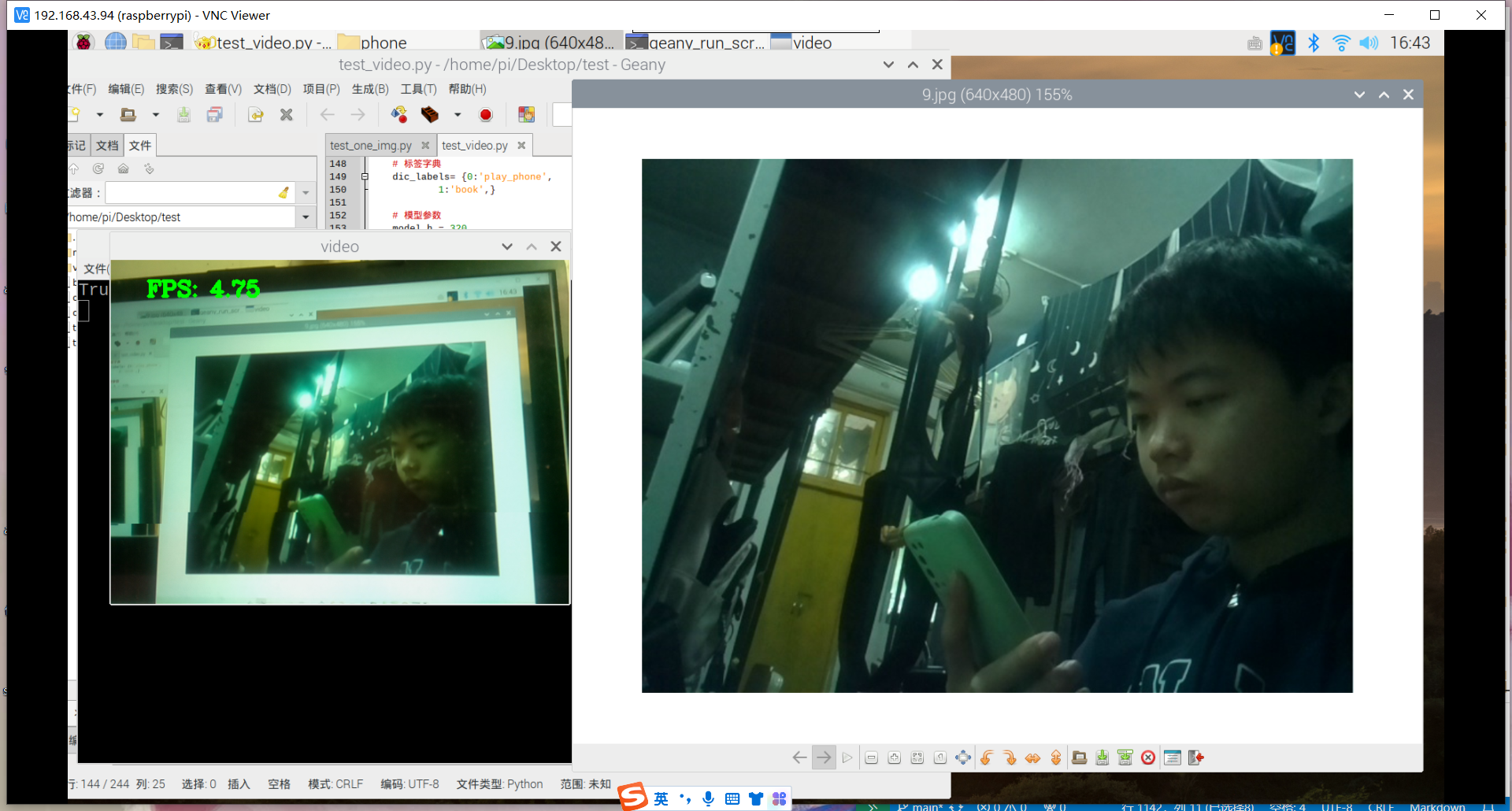
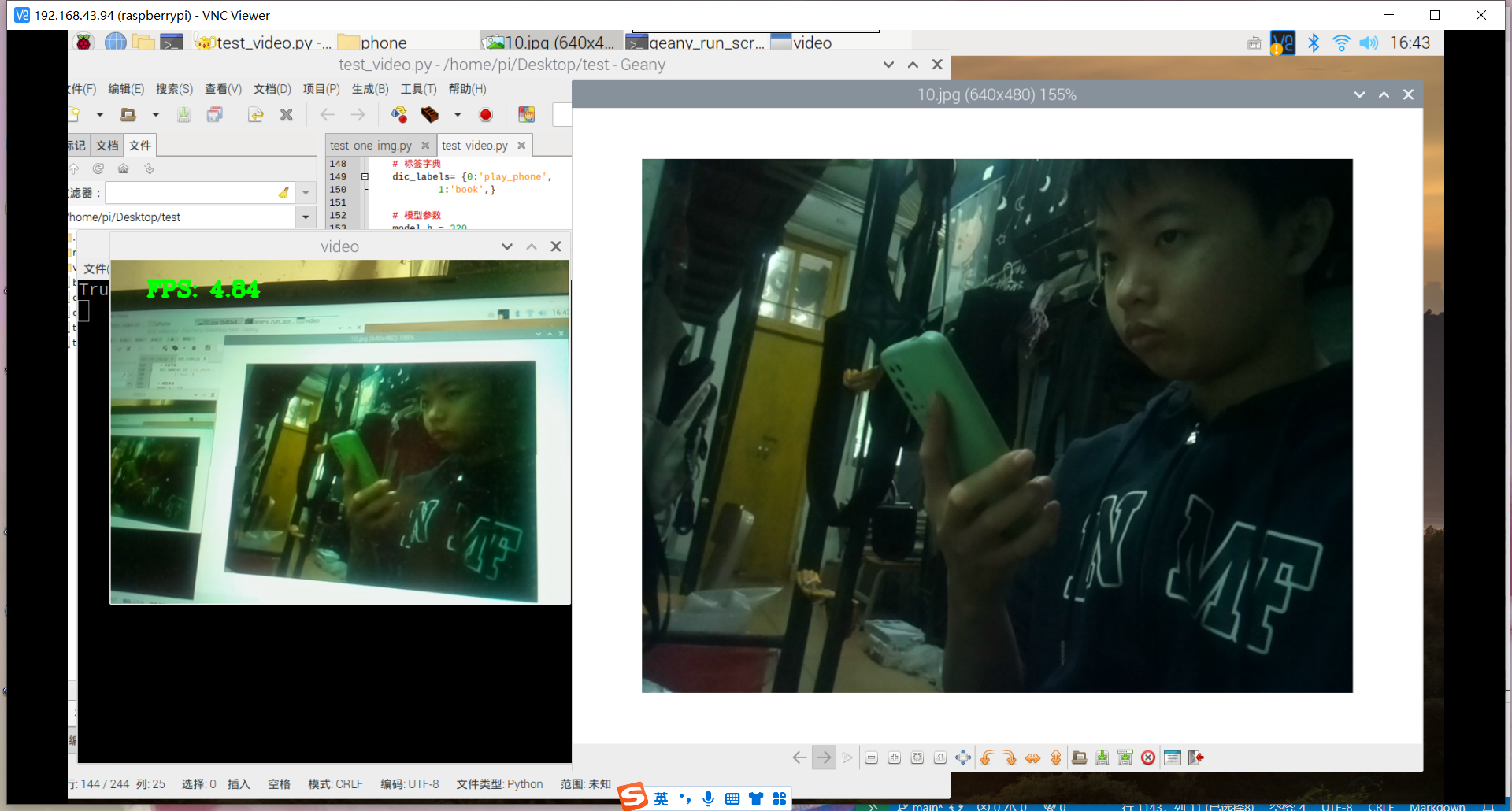
训练好了玩手机的识别模型:结果如下
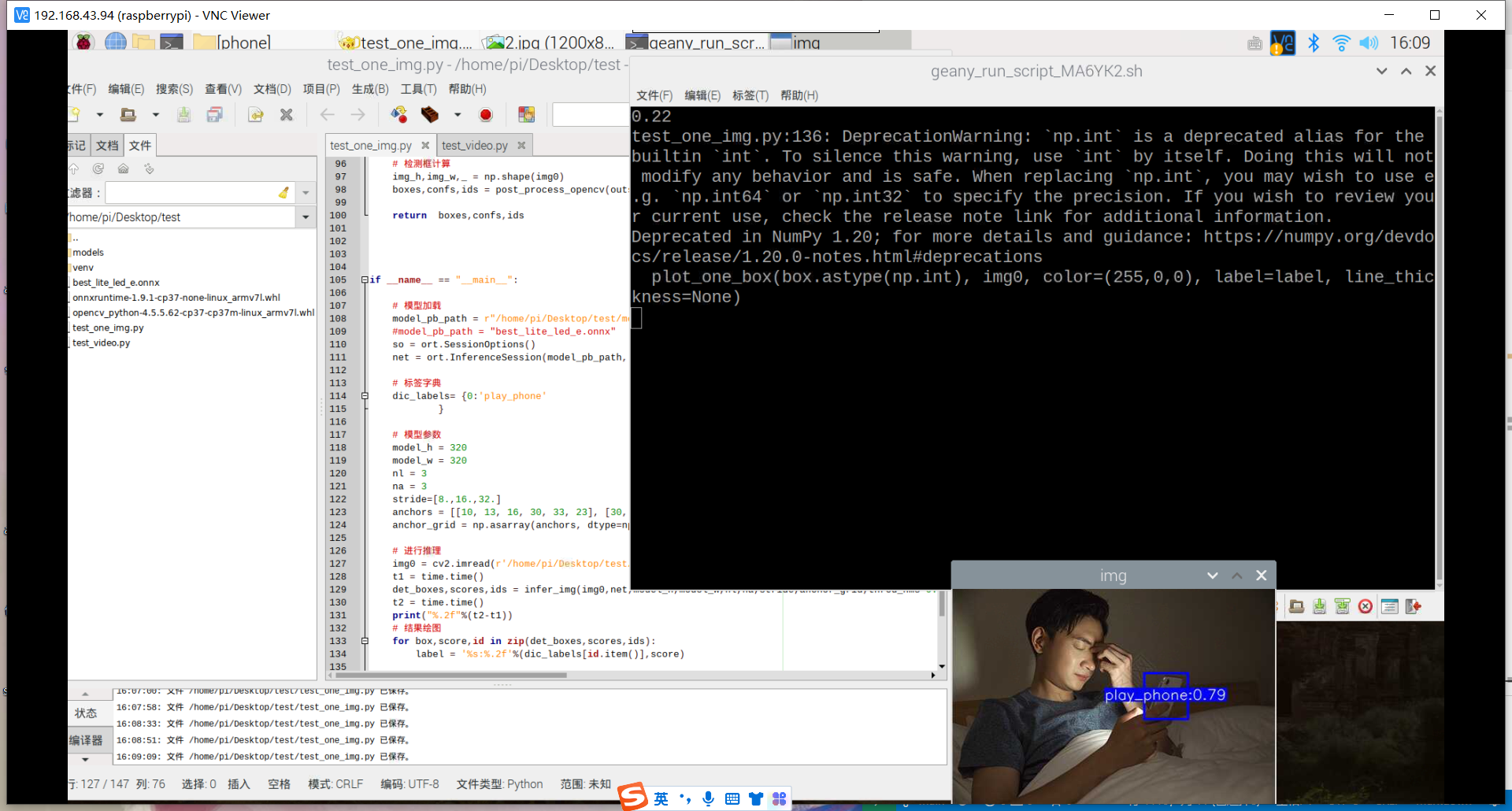
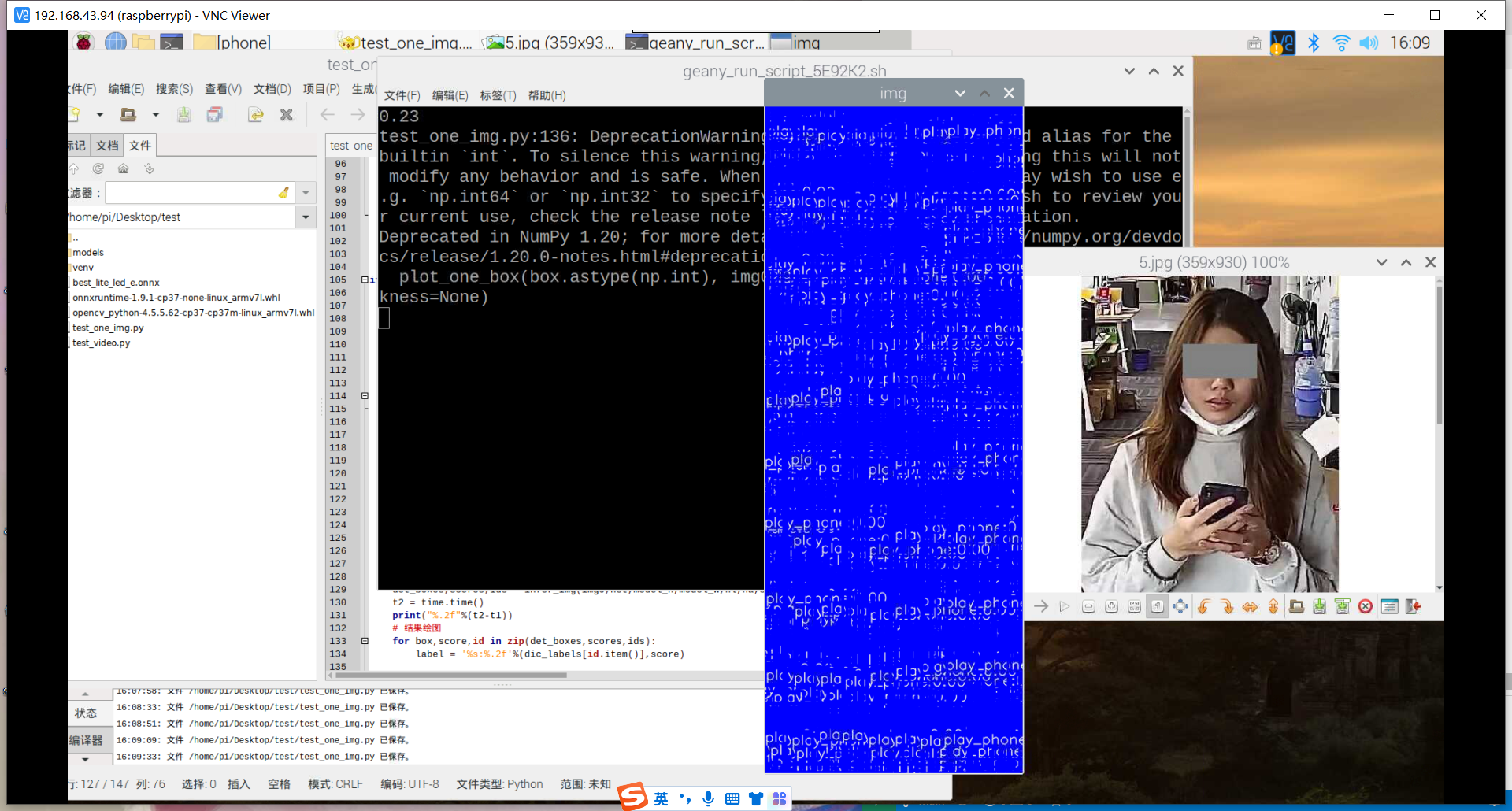
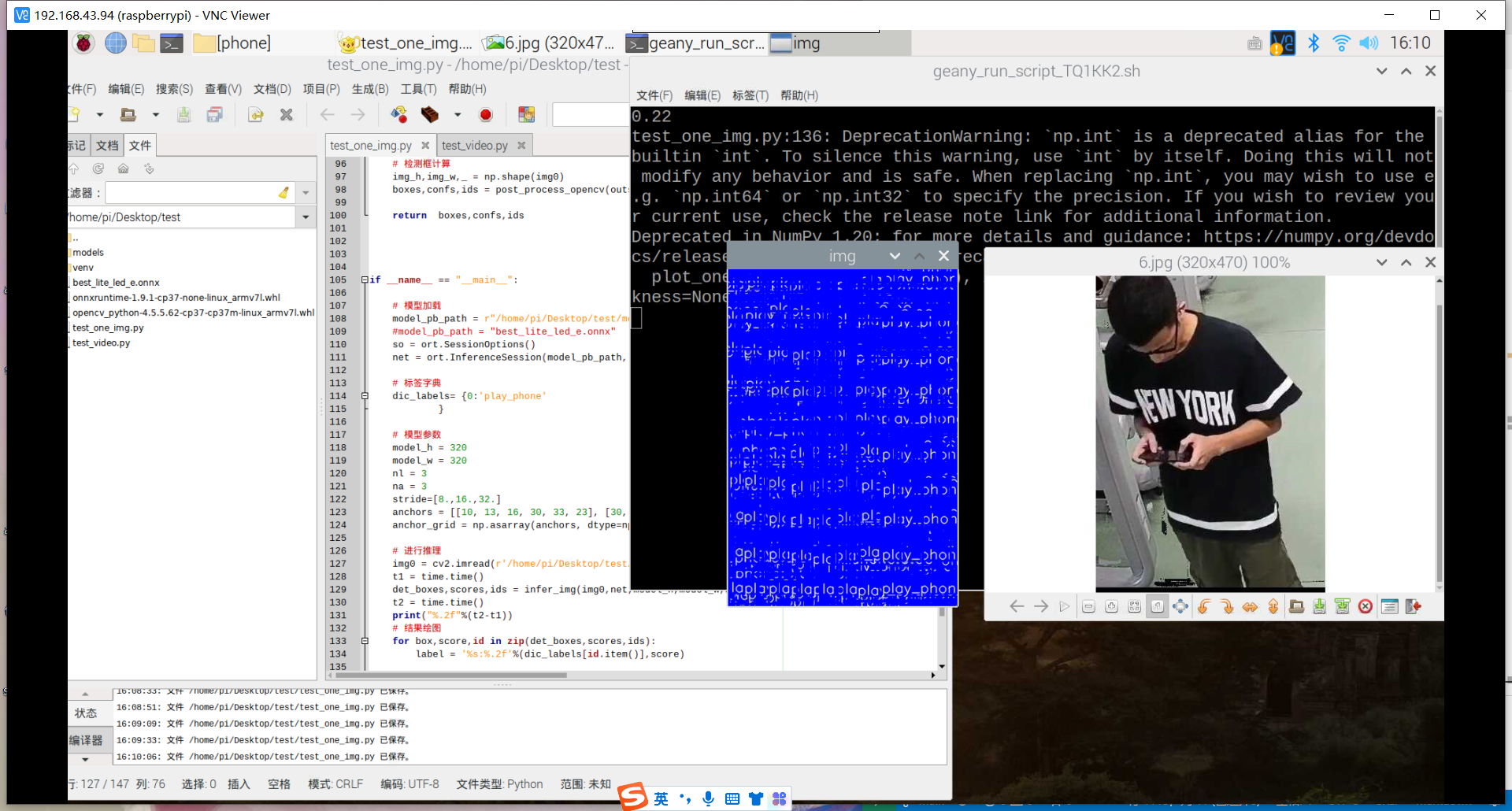
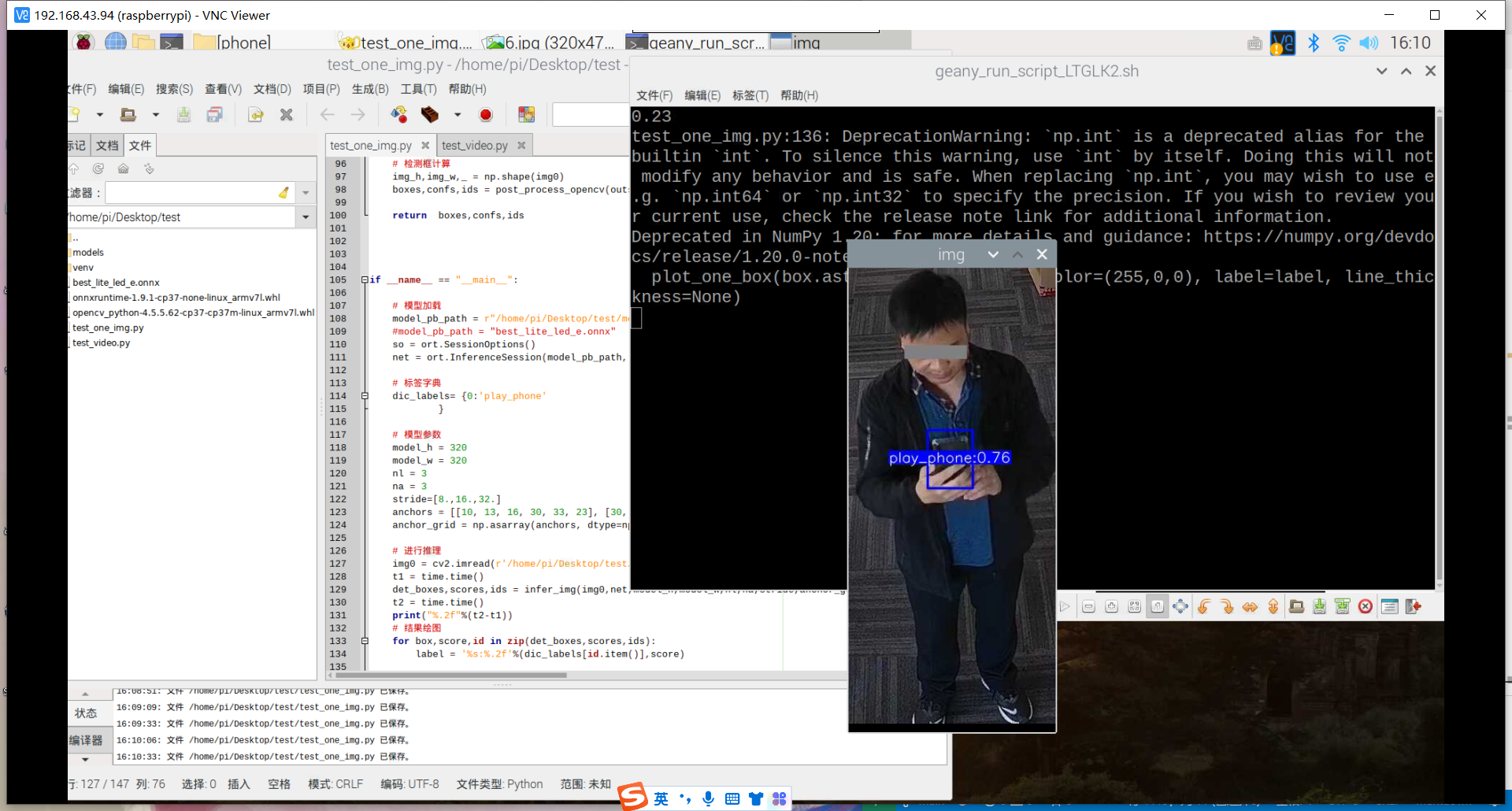
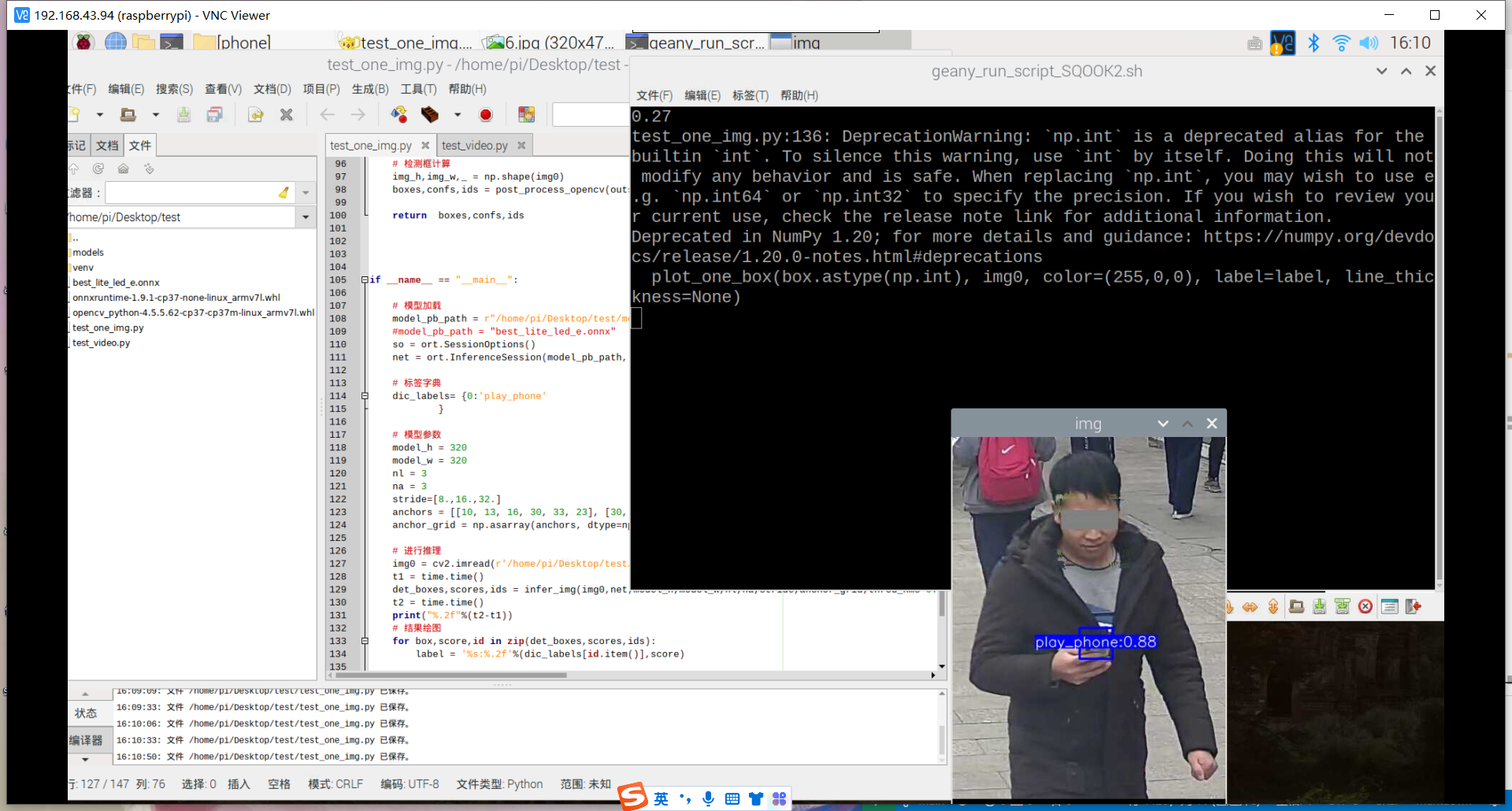
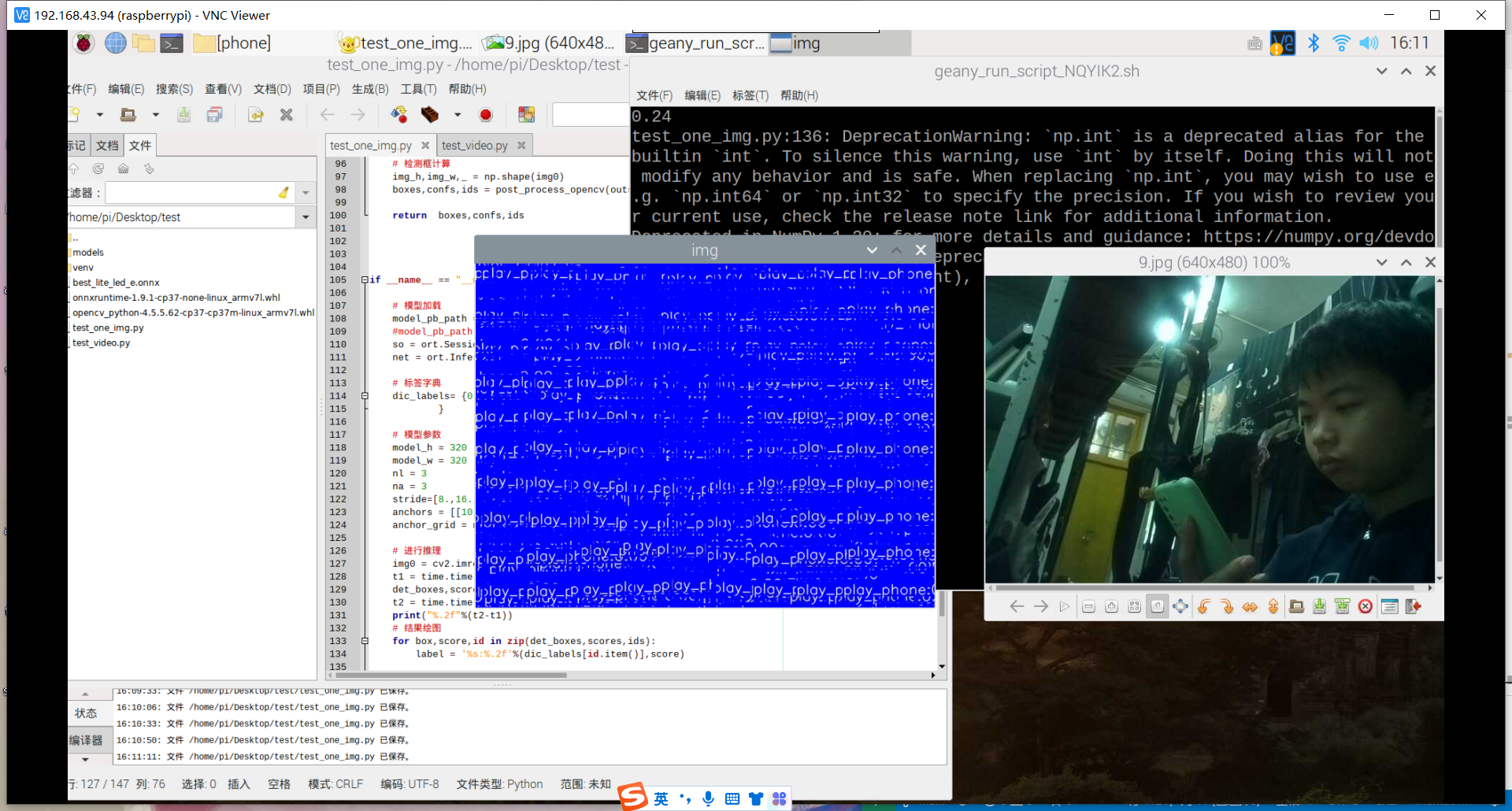
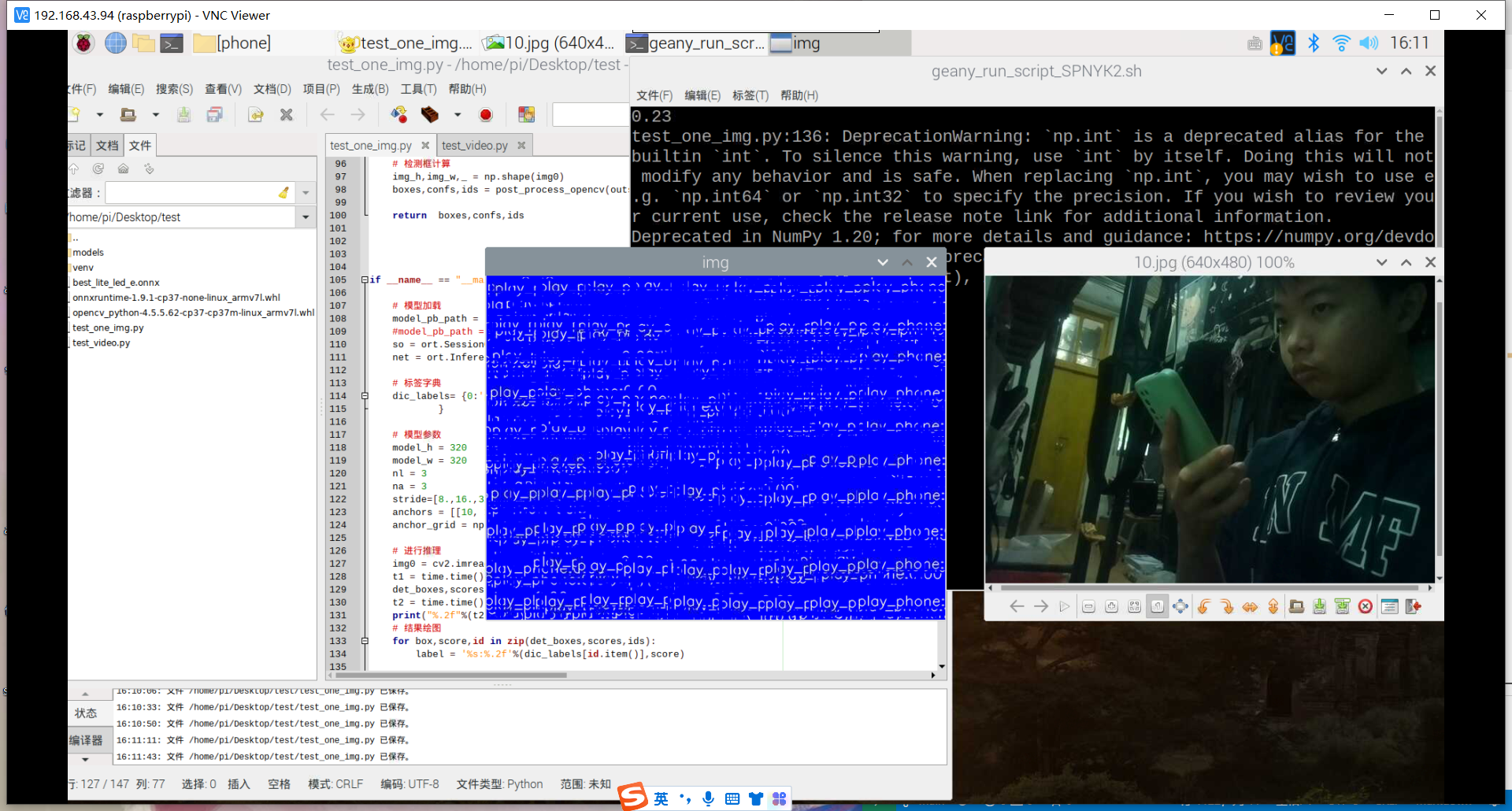
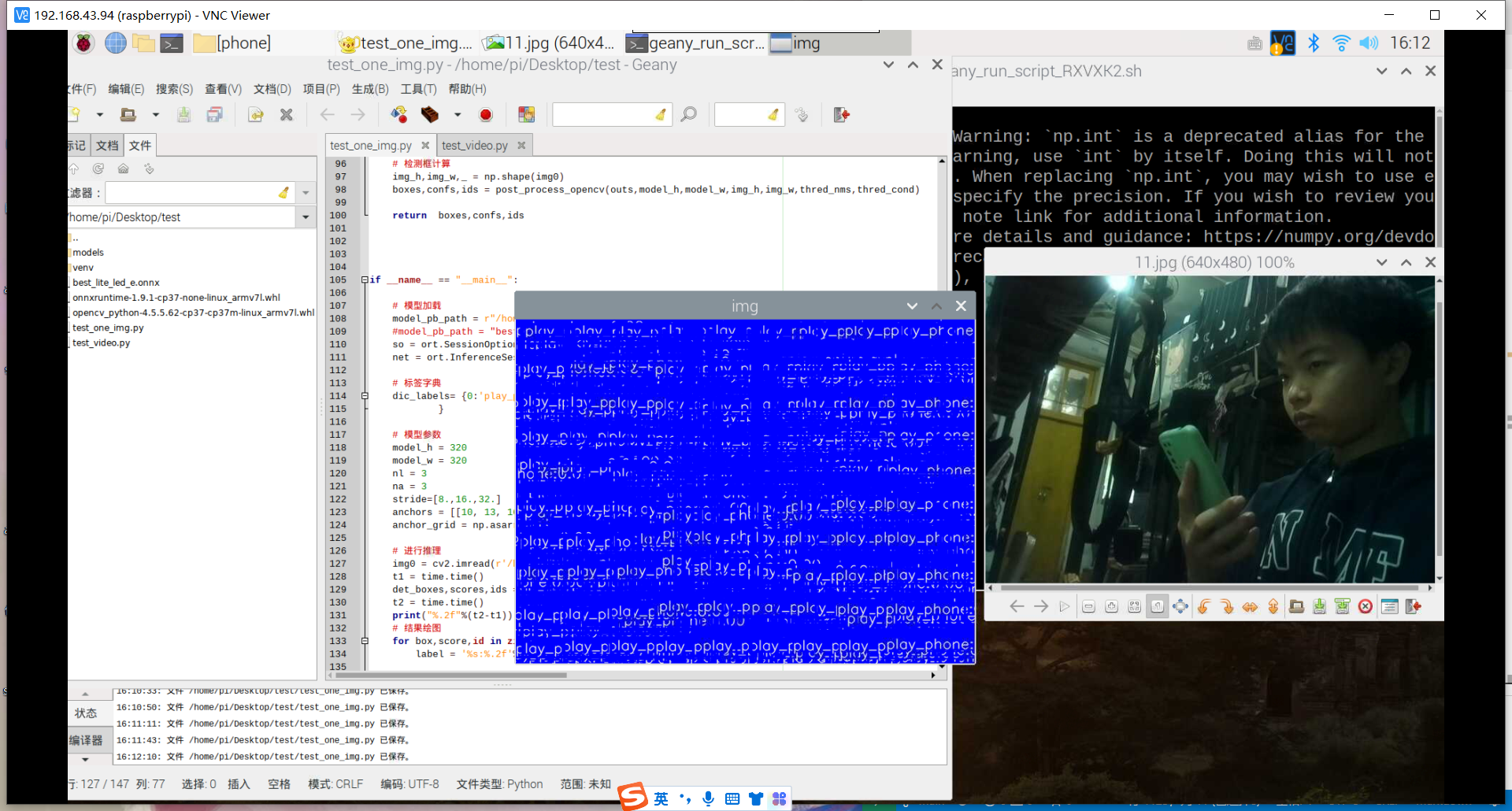
然后用之前老师范例教导训练的模型进行识别,试试失败的效果,结果发现也和上面识别失败的结果一样,就是图片被蓝色框框覆盖。
其实手机的识别还是可以的,但它的数据集不太合适,数据集是行人在路上玩手机(拿着手机、打电话偏多,而且手机还很小目标距离很远),也就是数据集不太丰富,过偏,导致某些情况下很明显在玩手机却没有识别出来,因此要丰富数据集。
想来书籍的识别也是如此,数据集太偏,不符合实际情况,导致一些很明显的情况却识别不出来。
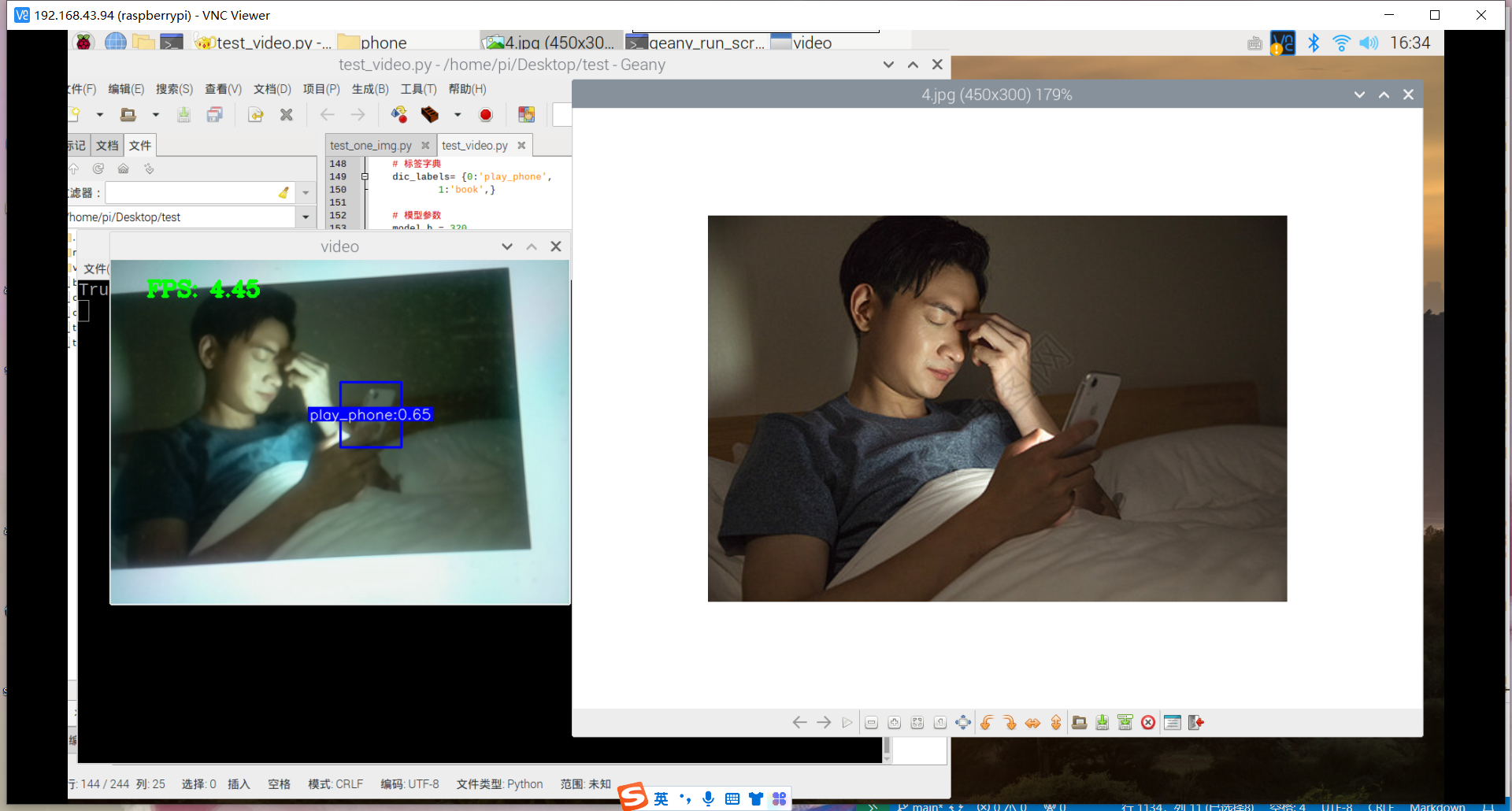
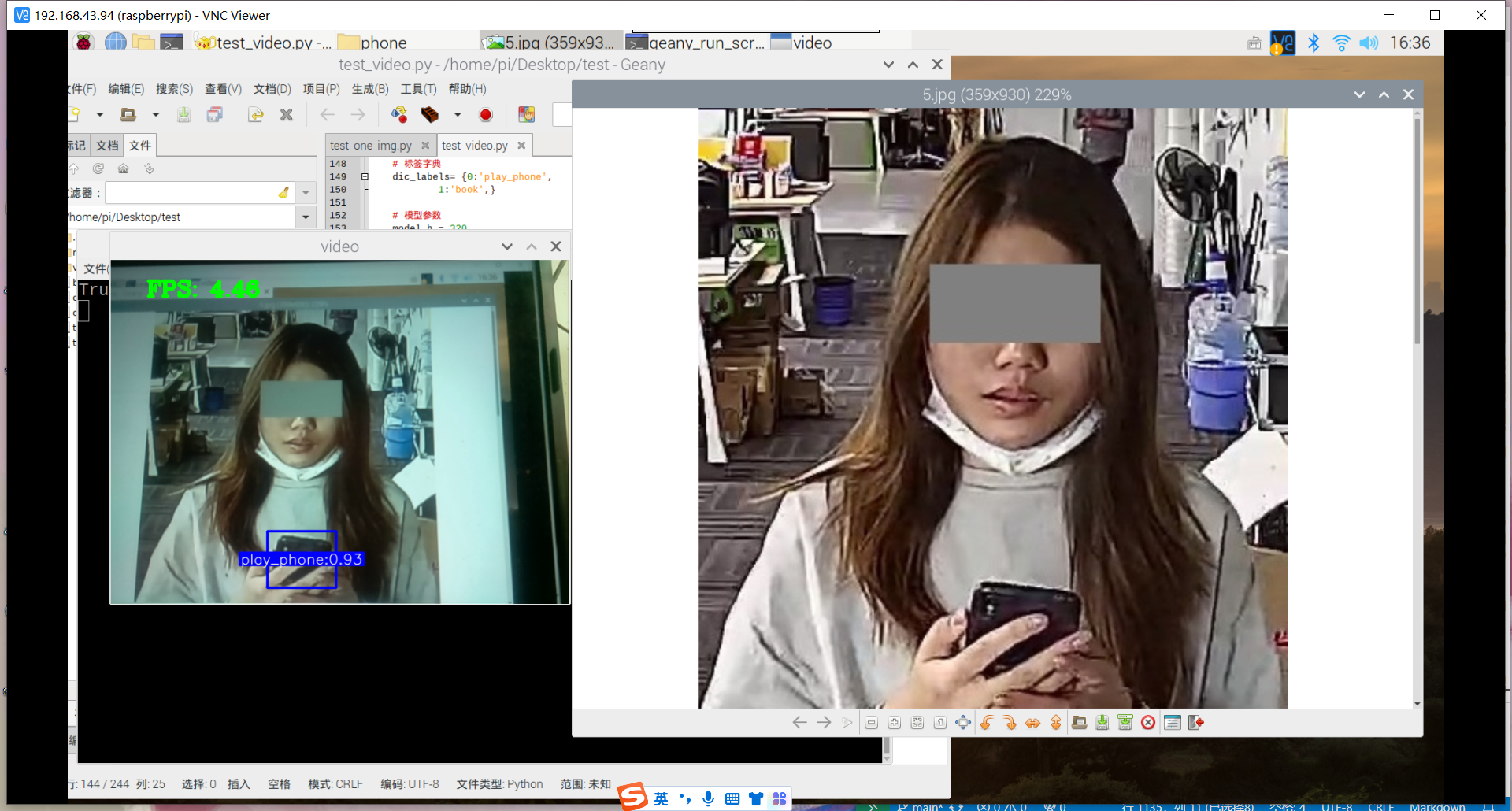
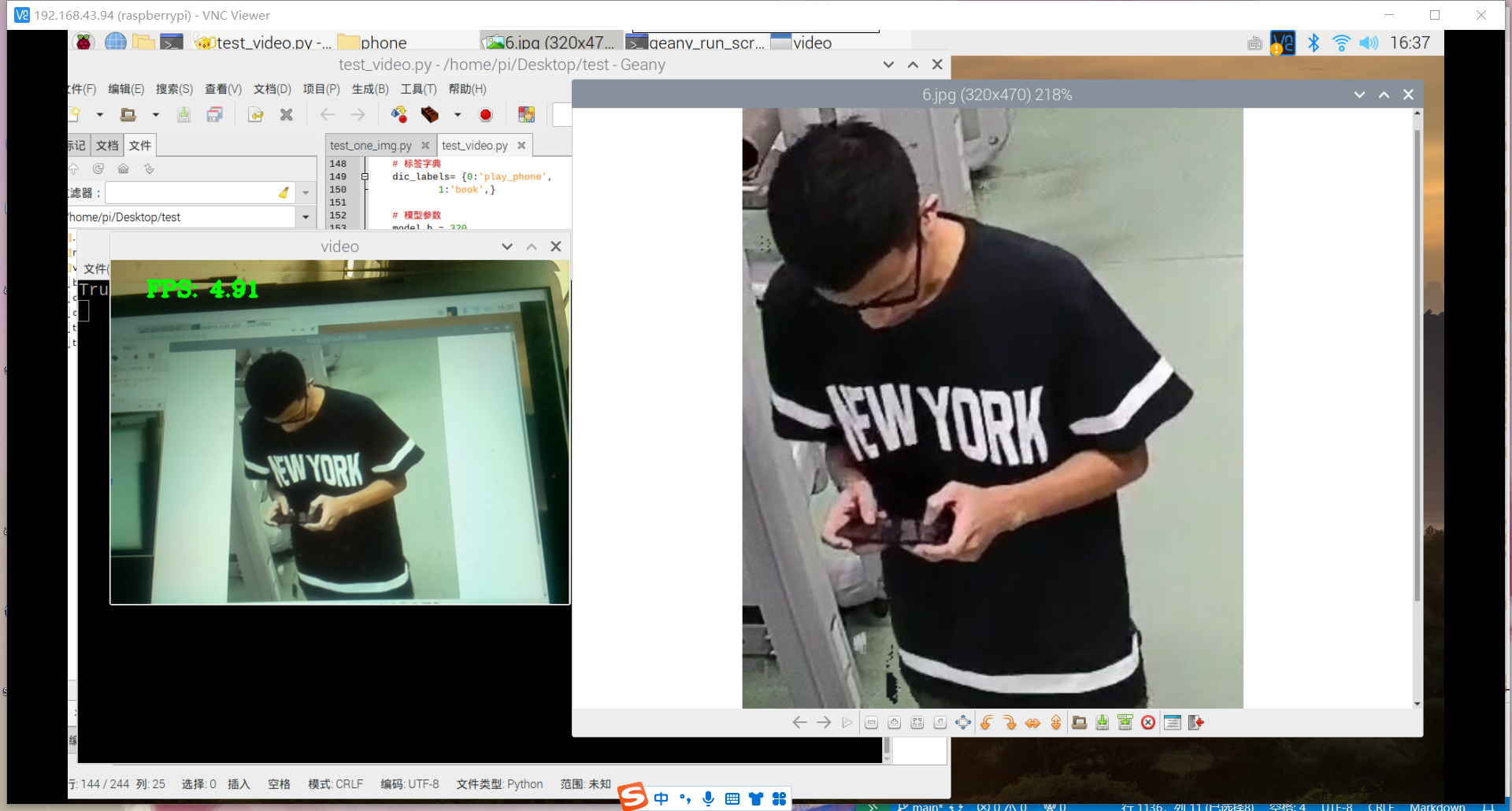
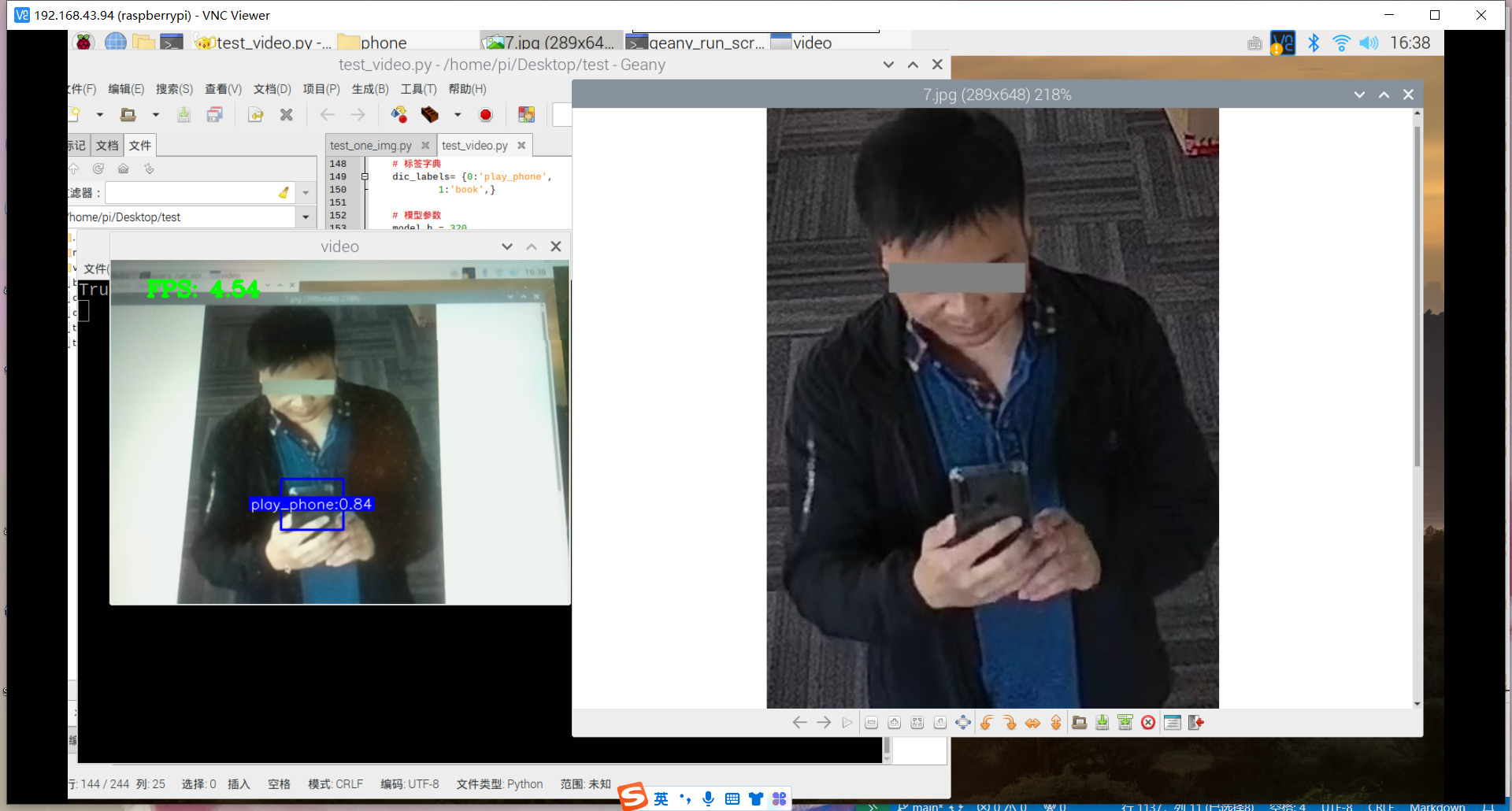
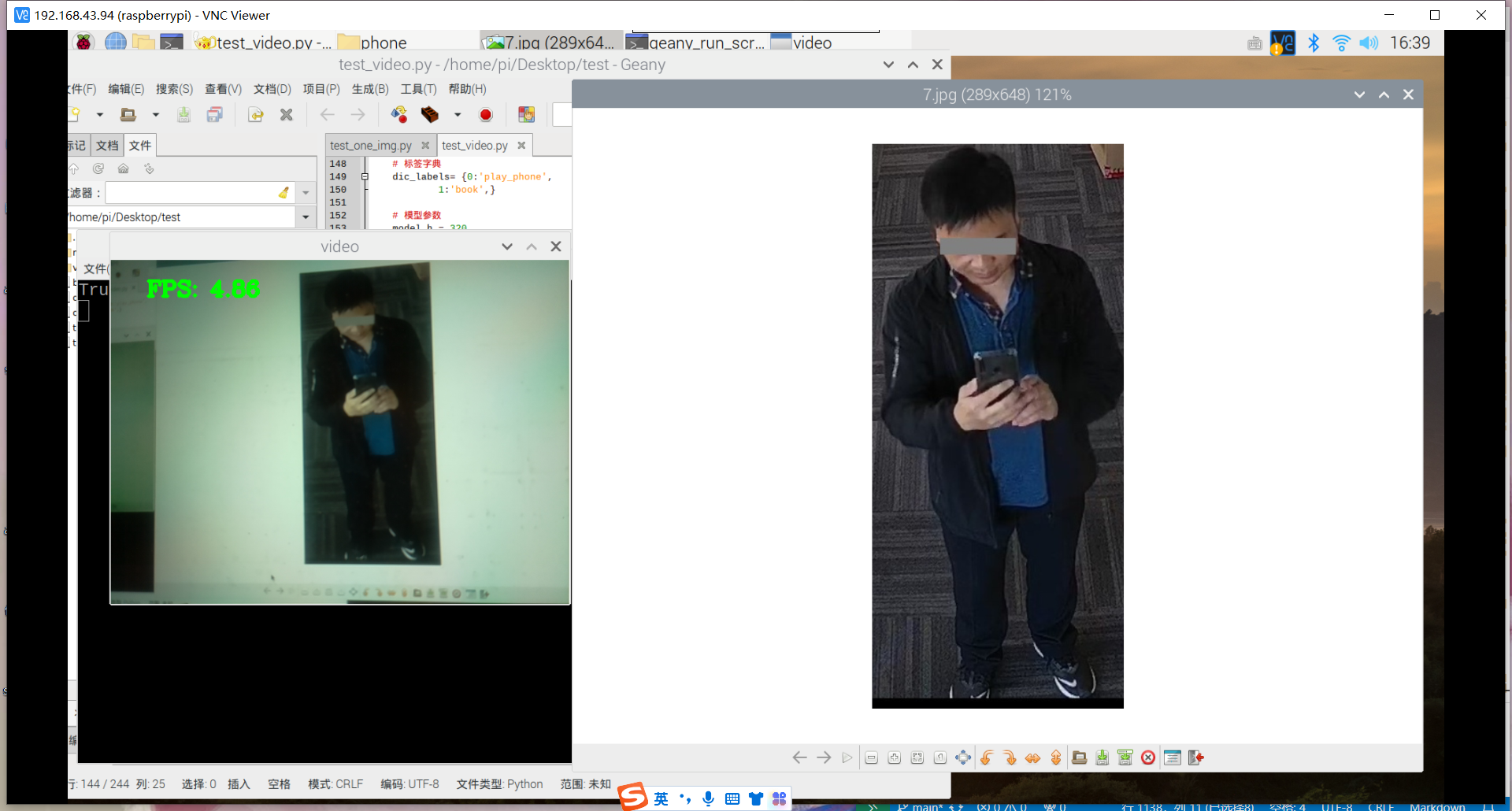
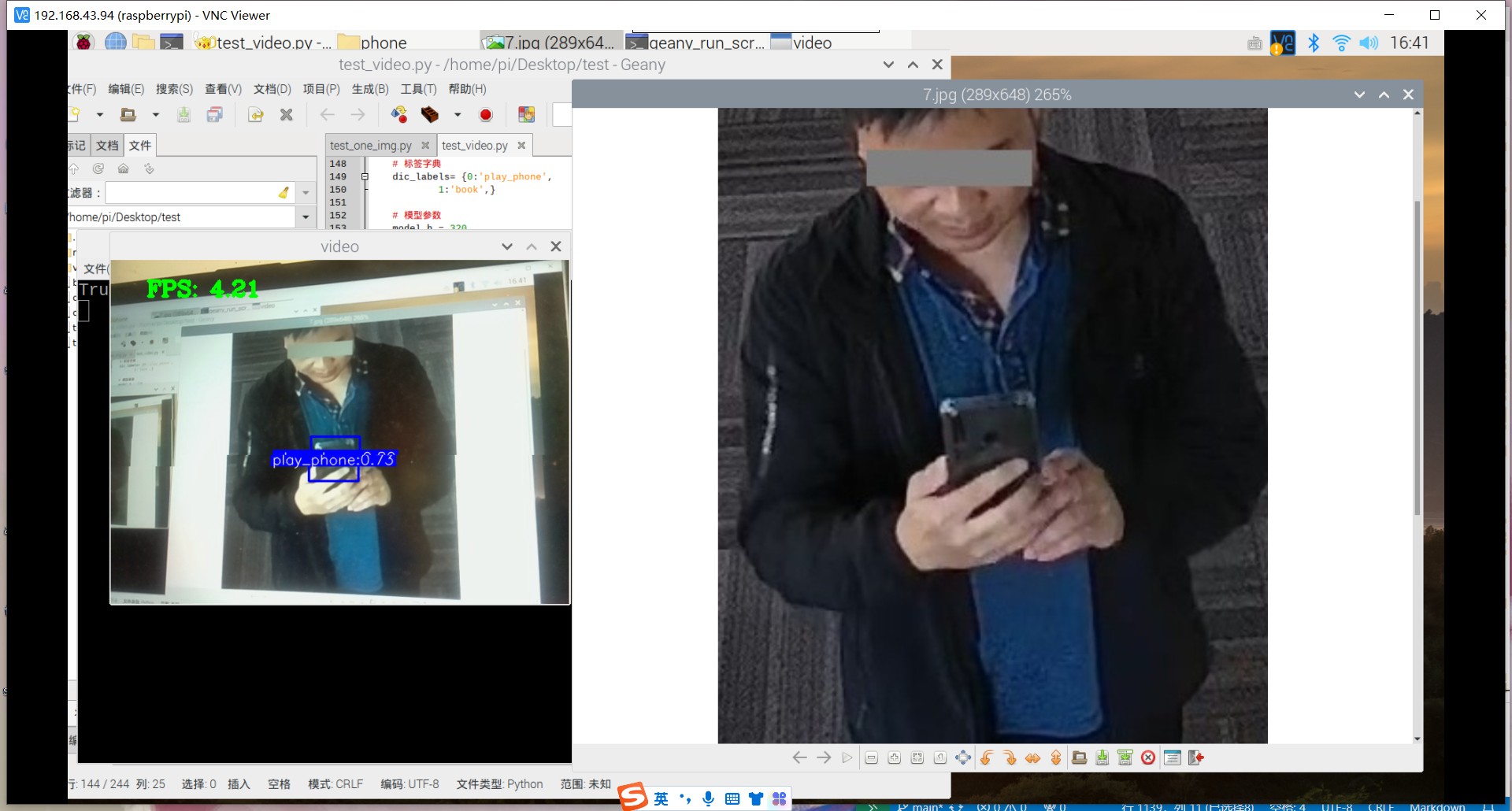
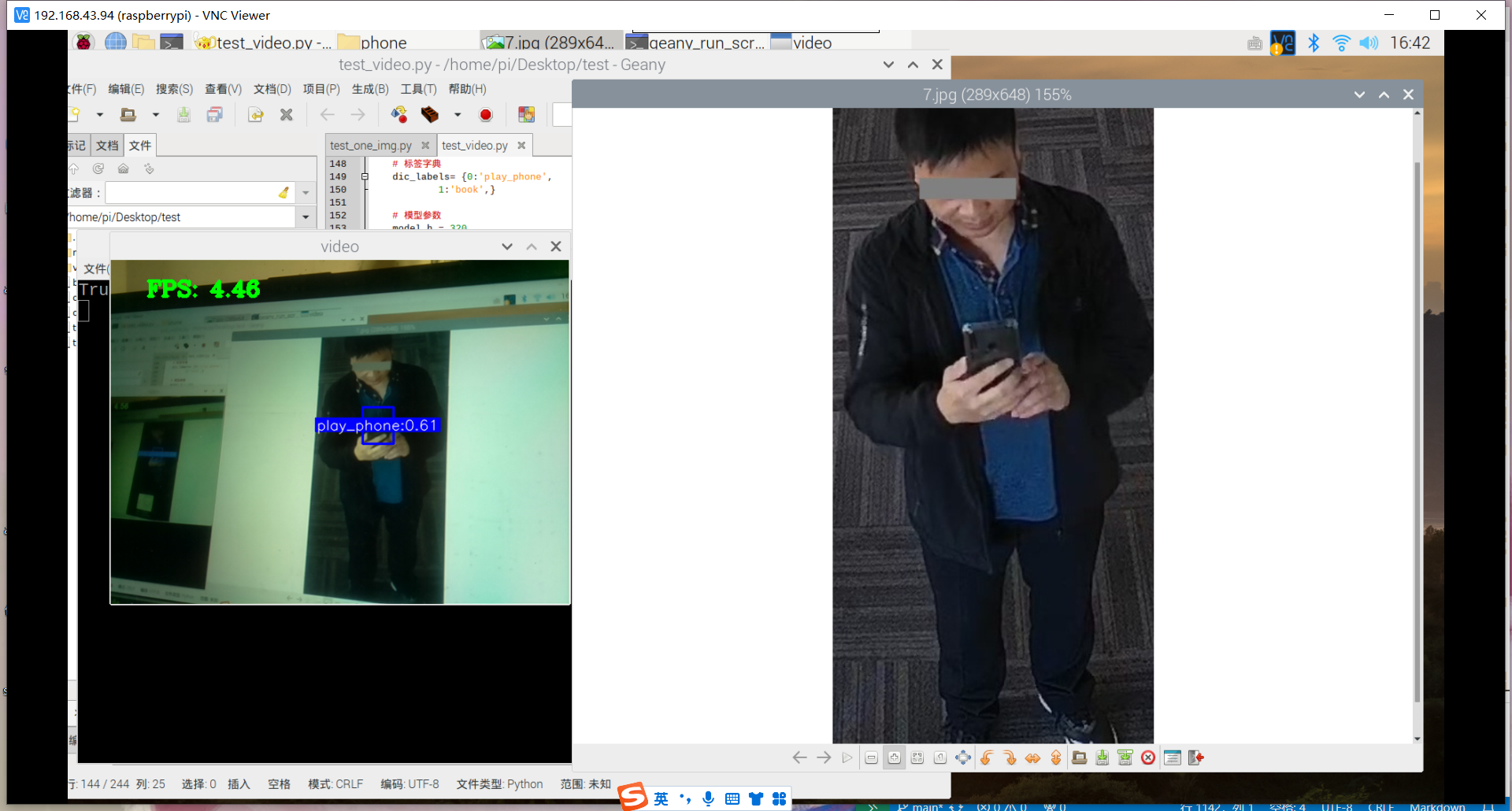
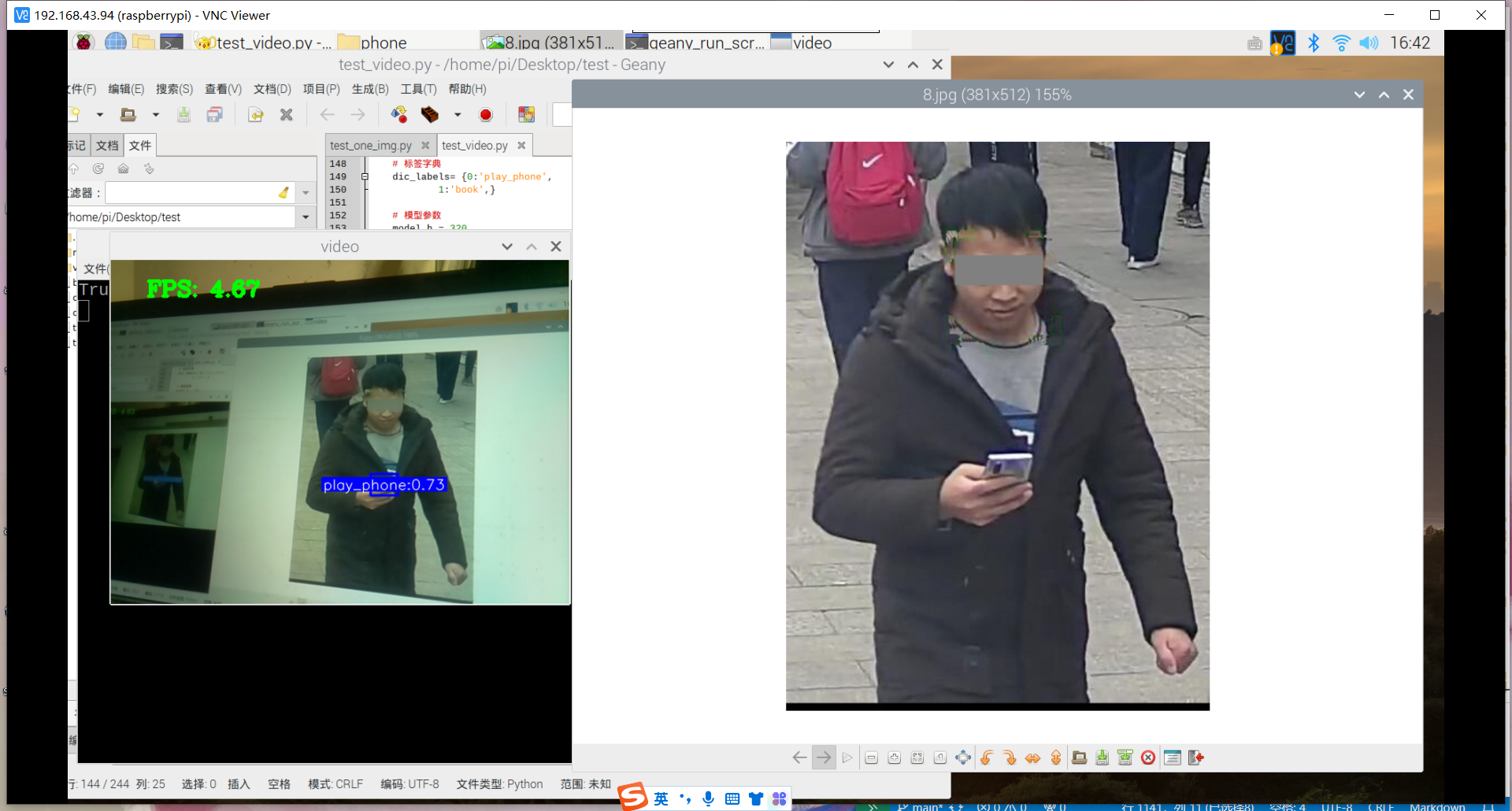
 原因:1.数据集不够丰富、2.树莓派摄像头不够清晰、手抖拍不清晰
原因:1.数据集不够丰富、2.树莓派摄像头不够清晰、手抖拍不清晰
先完成手机的识别,再然后书本,再然后结合。
1.买个支架和舵机,使之平稳,到后面可能控制舵机改变方向 2.提高摄像的清晰度,(换成usb摄像头/提高清晰度) 3.丰富数据集
其中,数据集最为重要,弄好后,在试一下模型能不能用,能不能在现实情况下识别出来。
当模型没问题后,再来搞摄像头的问题。
数据集关键词:床上玩手机、椅子上玩手机、地铁玩手机、教室玩手机、旅游玩手机、飞机玩手机、在饭店玩手机、吃饭时玩手机、酒吧玩手机、办公室玩手机、厕所玩手机、医院玩手机、宿舍玩手机、咖啡玩手机、自行车玩手机、工地玩手机、老人玩手机、孩子玩手机、上班玩手机、走路玩手机、街上玩手机、模特玩手机
手机够1000张合格的数据集,接着就是训练模型。根据老师的建议,或许可以更改一下模型,调整一下数据集的光亮程度什么的,形成新的数据集,使之更合适于宿舍的光线。
问题:我训练了一个yolov5-lite模型,但使用于视频检测的时候,却发现很难识别,我怀疑是光线的问题,训练的数据集都是那种很亮的图片,而实际测试的时候,测试的环境近乎在黄昏的环境。这怎么办
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
如果您的训练数据集中使用的是明亮的图片,而实际测试环境是黄昏或光线较暗的环境,这可能会影响模型的性能和准确度。为了解决这个问题,您可以考虑以下几个方面:
数据集增强:尝试使用一些数据增强技术来模拟不同光照条件下的图像。例如,可以调整图像的亮度、对比度或添加光照变化等。通过在训练数据集中引入不同光照条件下的样本,可以帮助模型更好地适应不同环境下的识别。
数据集扩充:收集更多在黄昏或光线较暗环境下的样本,并将其添加到训练数据集中。这样可以使模型更好地学习在光线不足的情况下进行准确的目标检测。
调整模型结构:考虑调整模型的结构或参数,使其更适应在光线较暗的环境下进行检测。例如,可以增加模型的层数或神经元数量,以提高模型的感知能力和鲁棒性。
后期处理:在进行目标检测之后,可以尝试应用一些后期处理技术来改善结果。例如,使用图像增强算法来增强图像的亮度和对比度,或者使用背景减除算法来消除光照变化的影响。
使用更适应光线变化的模型:如果您的应用场景中经常遇到光线变化的情况,可以考虑使用一些对光照变化更鲁棒的目标检测模型。例如,YOLOv4、YOLOv5-x或一些基于深度学习和光照不变性的方法。
调整环境条件:尽可能调整测试环境的光线条件,使其更接近训练数据集中使用的光照条件。这可以通过增加额外的照明或调整摄像机设置等方式实现。
需要注意的是,调整模型或数据集时,要确保在新的环境中进行充分的测试和验证,以确保模型在各种条件下的性能和准确度。
另外,如果您的模型在其他光照条件下表现良好,但在黄昏或光线较暗的环境下效果不佳,那么可能需要更多针对该特定环境的优化和调整。
尝试: 1.学习使用学习增强技术,模拟不同光照下的图像 2.后期处理,可以使用一些图像增强算法,增强图像的亮度和对比度,然后在进行目标检测 3.调整或是更换模型
问题:如何增强数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
数据集增强是一种通过对原始数据进行变换和扩充来增加数据多样性的技术,以改善模型的泛化能力和鲁棒性。以下是一些常用的数据集增强方法,您可以根据具体情况选择适合的方法:
随机裁剪(Random Cropping):随机裁剪图像的一部分,并将其作为新的训练样本。可以在不同位置和尺寸上进行裁剪,以增加样本的多样性。
图像翻转(Image Flipping):对图像进行水平或垂直翻转,以增加样本的多样性。例如,可以将图像水平翻转,然后将翻转后的图像作为新的训练样本。
图像缩放和旋转(Image Scaling and Rotation):对图像进行缩放和旋转操作,以模拟不同尺度和角度下的目标。可以随机选择缩放比例和旋转角度,以增加样本的多样性。
色彩变换(Color Transform):对图像进行色彩变换,如亮度、对比度、饱和度的调整,以模拟不同光照条件下的图像。可以通过调整图像的色彩通道或应用滤波器来实现。
添加噪声(Adding Noise):向图像中添加随机噪声,如高斯噪声、椒盐噪声等,以增加模型对噪声的鲁棒性。
数据混合(Data Mixing):将多个图像进行混合或叠加,生成新的训练样本。例如,可以将两个图像按一定的比例进行混合,以生成新的样本。
平移和仿射变换(Translation and Affine Transformation):对图像进行平移、旋转、缩放和剪切等仿射变换,以增加样本的多样性。
随机遮挡(Random Occlusion):在图像中随机添加遮挡物,如矩形块或随机形状,以模拟遮挡或部分目标的场景。
增加样本数量(Increasing Sample Count):通过复制、重复或扩充已有样本,增加训练数据的数量。可以采用重复采样、剪切图像或随机生成样本等方法。
这些方法可以单独或组合使用,具体选择哪些方法取决于您的应用场景和数据特点。在实施数据集增强时,要确保生成的新样本仍然保持目标的真实性和可识别性。同时,注意在数据集增强过程中维持类别平衡,以避免引入偏差。
另外,还可以考虑使用开源的数据集增强工具,如imgaug、Albumentations等,它们提供了丰富的数据增强方法和易于使用的接口,可以帮助简化数据集增强的流程。
问题:如何进行色彩变换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
进行色彩变化可以通过一些图像处理技术和算法来实现。以下是几种常用的色彩变化方法:
调整亮度(Brightness Adjustment):通过改变图像的亮度值来调整图像的明暗程度。可以使用以下方法之一:
线性变换:将每个像素的亮度值乘以一个缩放因子来增加或减少亮度。
直方图均衡化:通过重新分布图像的亮度值来增强对比度和亮度。
调整对比度(Contrast Adjustment):通过改变图像的对比度来增强或减弱图像中不同区域之间的差异。可以使用以下方法之一:
线性变换:将像素的亮度值乘以一个缩放因子来调整对比度。
自适应直方图均衡化:类似于直方图均衡化,但可以根据图像的局部区域进行自适应的亮度调整。
调整饱和度(Saturation Adjustment):通过改变图像的饱和度来增强或减弱图像中的色彩强度。可以使用以下方法之一:
HSV调整:将图像从RGB颜色空间转换到HSV颜色空间,然后调整饱和度通道的值。
线性变换:将像素的饱和度值乘以一个缩放因子来调整饱和度。
色彩平衡(Color Balance):通过调整图像中不同颜色通道的强度来改变图像的整体色彩。可以根据需要增加或减少特定颜色通道的值。
调整色调(Hue Adjustment):通过改变图像的色调来改变图像中颜色的整体偏移。可以使用以下方法之一:
HSV调整:将图像从RGB颜色空间转换到HSV颜色空间,然后调整色调通道的值。
线性变换:将像素的色调值加上一个偏移量来调整色调。
这些方法可以使用图像处理库(如OpenCV、PIL)或深度学习框架中的图像处理函数来实现。具体实现的代码可能会有所不同,取决于您选择的工具和编程语言。您可以根据自己的需求选择适当的参数和方法来进行色彩变化,并进行实验和调整以获得最佳效果。
数据增强
方法1:https://zhuanlan.zhihu.com/p/580489624 方法2:https://blog.csdn.net/qq_52050692/article/details/119698239
像素值反转
概述:用255减去像素点上的RGB值
1
2
3
4
5
from PIL import Image, ImageChops
img = Image.open("/pic/2.jpg")
inv_img = ImageChops.invert(img) #像素值反转
inv_img.show()

色彩抖动
概述:通过随机调整原始图片的饱和度,亮度,对比度,锐度来对产生新的图像。
方法1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
import numpy as np
from PIL import Image
from PIL import ImageEnhance
import cv2
import random
import matplotlib.pyplot as plt
def randomColor(image, saturation=0, brightness=0, contrast=0, sharpness=0):
if random.random() < saturation:
random_factor = np.random.randint(0, 31) / 10. # 随机因子
image = ImageEnhance.Color(image).enhance(random_factor) # 调整图像的饱和度
if random.random() < brightness:
random_factor = np.random.randint(10, 21) / 10. # 随机因子
image = ImageEnhance.Brightness(image).enhance(random_factor) # 调整图像的亮度
if random.random() < contrast:
random_factor = np.random.randint(10, 21) / 10. # 随机因1子
image = ImageEnhance.Contrast(image).enhance(random_factor) # 调整图像对比度
if random.random() < sharpness:
random_factor = np.random.randint(0, 31) / 10. # 随机因子
ImageEnhance.Sharpness(image).enhance(random_factor) # 调整图像锐度
return image
img = cv2.imread("/pic/2.jpg")
cj_img = Image.fromarray(img)
sa_img = np.asarray(randomColor(cj_img, saturation=1))
br_img = np.asarray(randomColor(cj_img, brightness=1))
co_img = np.asarray(randomColor(cj_img, contrast=1))
sh_img = np.asarray(randomColor(cj_img, sharpness=1))
rc_img = np.asarray(randomColor(cj_img, saturation=1, \
brightness=1, contrast=1, sharpness=1))
#plt.title设置中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(15, 10))
plt.subplot(2,3,1), plt.imshow(img)
plt.axis('off'); plt.title('原图')
plt.subplot(2,3,2), plt.imshow(sa_img)
plt.axis('off'); plt.title('调整饱和度')
plt.subplot(2,3,3), plt.imshow(br_img)
plt.axis('off'); plt.title('调整亮度')
plt.subplot(2,3,4), plt.imshow(co_img)
plt.axis('off'); plt.title('调整对比度')
plt.subplot(2,3,5), plt.imshow(sh_img)
plt.axis('off'); plt.title('调整锐度')
plt.subplot(2,3,6), plt.imshow(rc_img)
plt.axis('off'); plt.title('调整所有项')
plt.show()


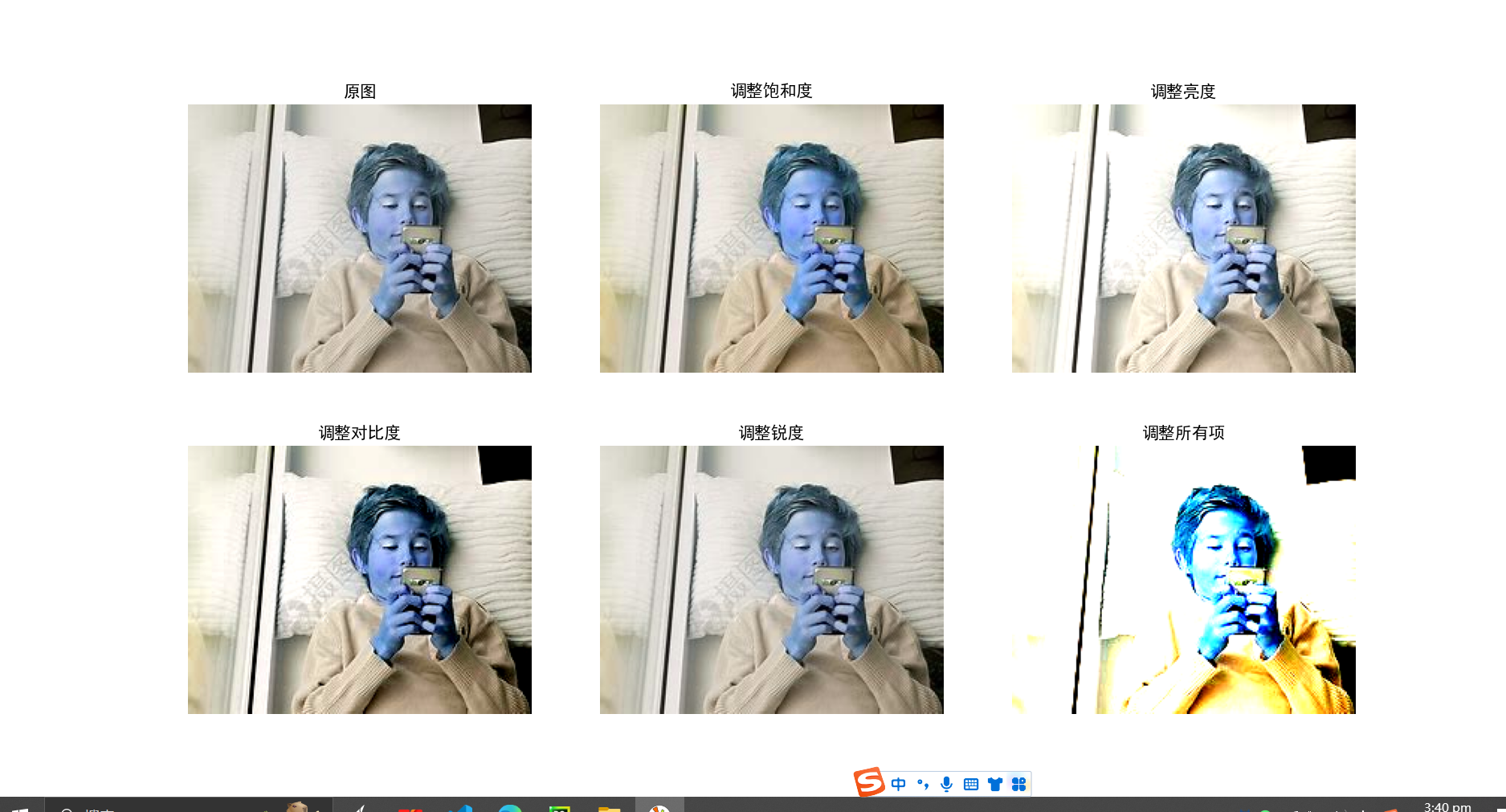
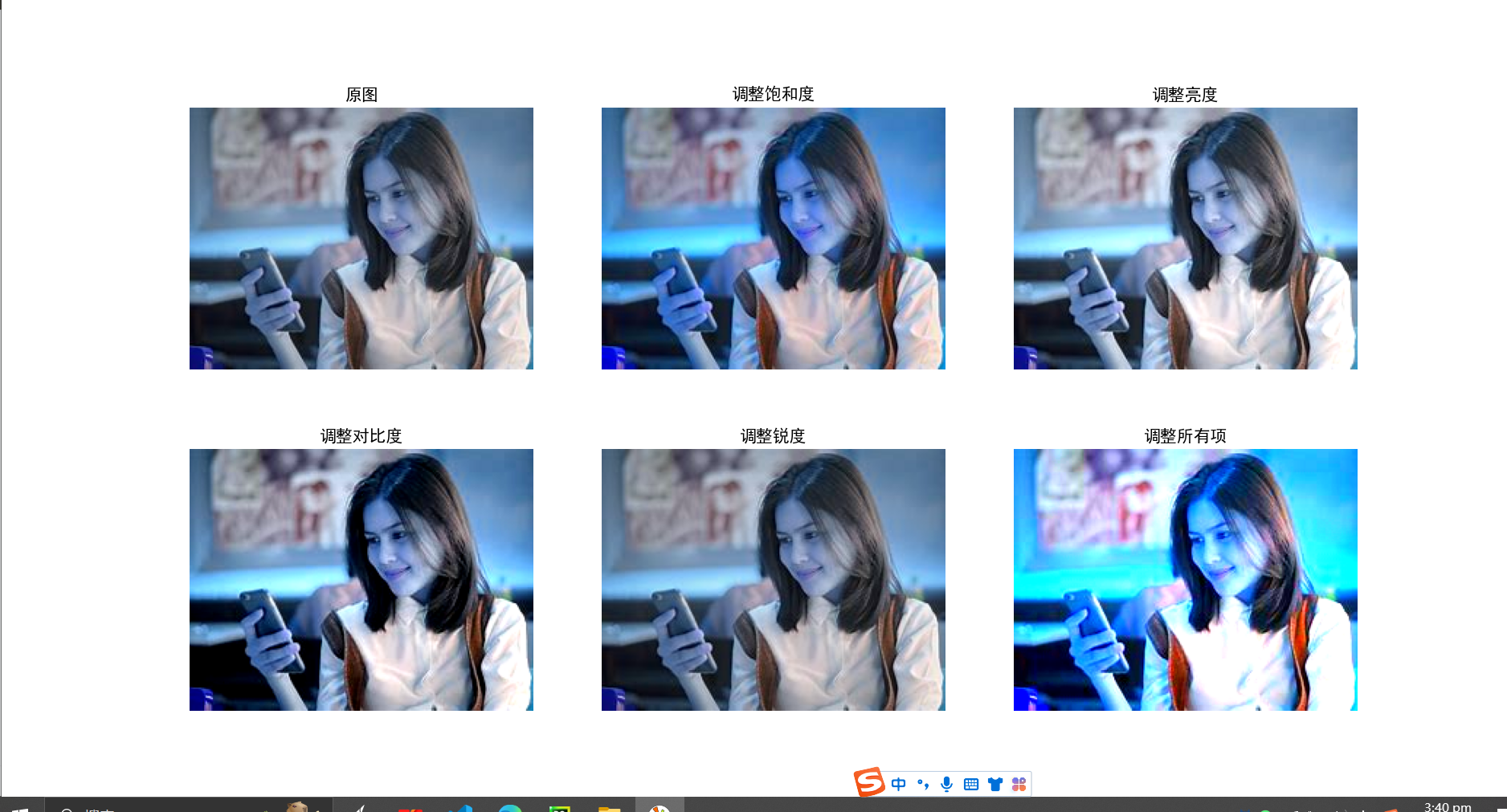
这个有点不对劲
改进:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
import numpy as np
from PIL import Image
from PIL import ImageEnhance
import cv2
import random
import matplotlib.pyplot as plt
def randomColor(image, saturation=0, brightness=0, contrast=0, sharpness=0):
if random.random() < saturation:
random_factor = np.random.uniform(0.8, 1.2) # 随机因子
image = ImageEnhance.Color(image).enhance(random_factor) # 调整图像的饱和度
if random.random() < brightness:
random_factor = np.random.uniform(0.8, 1.2) # 随机因子
image = ImageEnhance.Brightness(image).enhance(random_factor) # 调整图像的亮度
if random.random() < contrast:
random_factor = np.random.uniform(0.8, 1.2) # 随机因子
image = ImageEnhance.Contrast(image).enhance(random_factor) # 调整图像对比度
if random.random() < sharpness:
random_factor = np.random.uniform(0.8, 1.2) # 随机因子
image = ImageEnhance.Sharpness(image).enhance(random_factor) # 调整图像锐度
return image
img = cv2.imread("/pic/2.jpg")
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 转换颜色空间为RGB
cj_img = Image.fromarray(img_rgb)
sa_img = np.asarray(randomColor(cj_img, saturation=1))
br_img = np.asarray(randomColor(cj_img, brightness=1))
co_img = np.asarray(randomColor(cj_img, contrast=1))
sh_img = np.asarray(randomColor(cj_img, sharpness=1))
rc_img = np.asarray(randomColor(cj_img, saturation=1, brightness=1, contrast=1, sharpness=1))
#plt.title设置中文
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(15, 10))
plt.subplot(2, 3, 1), plt.imshow(img_rgb)
plt.axis('off')
plt.title('原图')
plt.subplot(2, 3, 2), plt.imshow(sa_img)
plt.axis('off')
plt.title('调整饱和度')
plt.subplot(2, 3, 3), plt.imshow(br_img)
plt.axis('off')
plt.title('调整亮度')
plt.subplot(2, 3, 4), plt.imshow(co_img)
plt.axis('off')
plt.title('调整对比度')
plt.subplot(2, 3, 5), plt.imshow(sh_img)
plt.axis('off')
plt.title('调整锐度')
plt.subplot(2, 3, 6), plt.imshow(rc_img)
plt.axis('off')
plt.title('调整所有项')
plt.tight_layout()
plt.show()
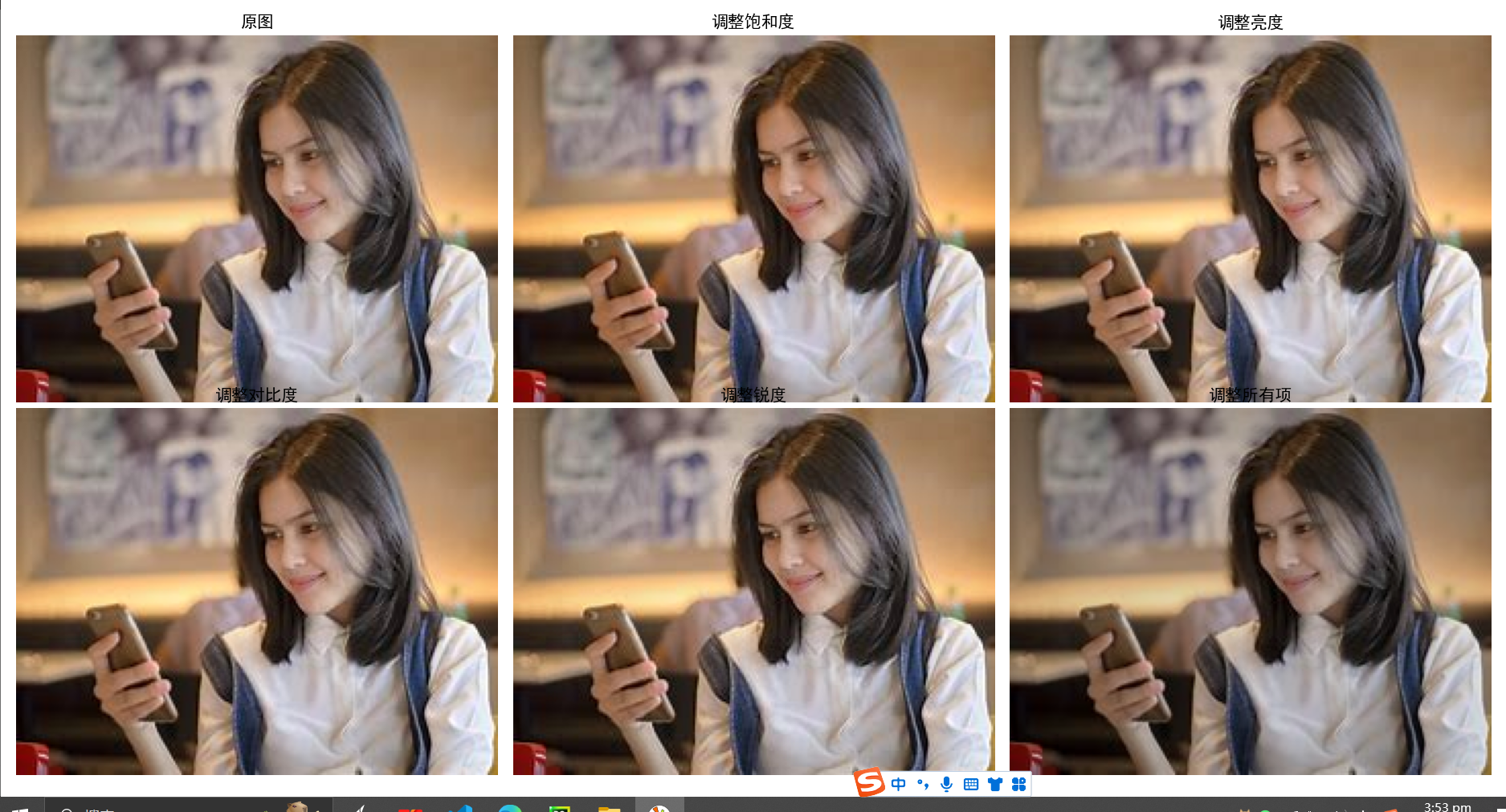

色彩增强
概述:ACE考虑了图像中颜色和亮度的空间位置关系,进行局部特性的自适应滤波,实现具有局部和非线性特征的图像亮度与色彩调整和对比度调整,同时满足灰色世界理论假设和白色斑点假设。
自动色彩增强(Automatic Color Enhancement, ACE)是一种常用的图像增强方法,它的主要作用如下:
增强图像的色彩饱和度和对比度:
ACE能够自适应地增强图像中物体的色彩饱和度,使图像整体看起来更丰富多彩。 同时ACE也能够增强图像的对比度,突出重要物体和区域,提高图像整体的视觉效果。 改善图像的亮度分布:
ACE可以根据图像的整体亮度情况,调整图像各区域的亮度分布,使整体亮度更加均匀自然。 这对于处理高反差或者阴暗环境下的图像非常有帮助。 提高图像的视觉质量:
ACE通过自适应增强图像的色彩和亮度,能够有效提高图像的清晰度、锐利度和细节表现。 从而使图像看起来更加生动清晰,提升整体的视觉效果。 总的来说,ACE是一种非常实用的图像增强算法,能够根据图像的特点自动调节色彩和亮度,提高图像的视觉感受。在目标检测等计算机视觉任务中,ACE也是一种常用的预处理手段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
import cv2
import numpy as np
import math
def stretchImage(data, s=0.005, bins=2000): # 线性拉伸,去掉最大最小0.5%的像素值,然后线性拉伸至[0,1]
ht = np.histogram(data, bins);
d = np.cumsum(ht[0]) / float(data.size)
lmin = 0;
lmax = bins - 1
while lmin < bins:
if d[lmin] >= s:
break
lmin += 1
while lmax >= 0:
if d[lmax] <= 1 - s:
break
lmax -= 1
return np.clip((data - ht[1][lmin]) / (ht[1][lmax] - ht[1][lmin]), 0, 1)
g_para = {}
def getPara(radius=5): # 根据半径计算权重参数矩阵
global g_para
m = g_para.get(radius, None)
if m is not None:
return m
size = radius * 2 + 1
m = np.zeros((size, size))
for h in range(-radius, radius + 1):
for w in range(-radius, radius + 1):
if h == 0 and w == 0:
continue
m[radius + h, radius + w] = 1.0 / math.sqrt(h ** 2 + w ** 2)
m /= m.sum()
g_para[radius] = m
return m
def zmIce(I, ratio=4, radius=300): # 常规的ACE实现
para = getPara(radius)
height, width = I.shape
zh, zw = [0] * radius + [x for x in range(height)] + [height - 1] * radius, [0] * radius + [x for x in range(width)] + [width - 1] * radius
Z = I[np.ix_(zh, zw)]
res = np.zeros(I.shape)
for h in range(radius * 2 + 1):
for w in range(radius * 2 + 1):
if para[h][w] == 0:
continue
res += (para[h][w] * np.clip((I - Z[h:h + height, w:w + width]) * ratio, -1, 1))
return res
def zmIceFast(I, ratio, radius): # 单通道ACE快速增强实现
height, width = I.shape[:2]
if min(height, width) <= 2:
return np.zeros(I.shape) + 0.5
Rs = cv2.resize(I, ((width + 1) // 2, (height + 1) // 2))
Rf = zmIceFast(Rs, ratio, radius) # 递归调用
Rf = cv2.resize(Rf, (width, height))
Rs = cv2.resize(Rs, (width, height))
return Rf + zmIce(I, ratio, radius) - zmIce(Rs, ratio, radius)
def zmIceColor(I, ratio=4, radius=3): # rgb三通道分别增强,ratio是对比度增强因子,radius是卷积模板半径
res = np.zeros(I.shape)
for k in range(3):
res[:, :, k] = stretchImage(zmIceFast(I[:, :, k], ratio, radius))
return res
if __name__ == '__main__':
m = zmIceColor(cv2.imread("/pic/2.jpg") / 255.0) * 255
cv2.imwrite('/pic/zmIce.jpg', m)


RGB颜色增强
RGB颜色增强是一种图像增强技术,它的主要作用包括:
增强图像的色彩饱和度:
RGB颜色增强通过调整图像的RGB三通道值,可以增强图像中物体的色彩饱和度,使颜色看起来更加丰富鲜艳。 调整图像的色彩平衡:
有时由于拍摄环境或设备问题,图像可能存在色偏现象。RGB颜色增强可以通过对RGB三通道的调整,来修正图像的整体色彩平衡,还原更加自然的色彩效果。 突出重要区域:
通过选择性地增强某些区域的色彩饱和度,可以使重要物体或区域更加醒目,从而吸引观察者的注意力。 提高图像的视觉质量:
RGB颜色增强通过改善图像的色彩表现,可以使图像看起来更加生动、清晰,整体提升视觉效果。 总的来说,RGB颜色增强是一种常见的图像预处理手段,它可以有效改善图像的色彩特性,增强视觉感受,在许多计算机视觉任务中都有应用价值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
def hist_ave_2(src):
L=np.unique(src)
cdf=(np.histogram(src.flatten(),L.size)[0]/src.size).cumsum()
cdf=(cdf*L.max()+0.5)
return np.interp(src.flatten(),L,cdf).reshape(src.shape)
img=np.array(Image.open("/pic/2.jpg"))
img_co=img.copy()
i_r,i_g,i_b=img[:,:,0],img[:,:,1],img[:,:,2]
i_r=hist_ave_2(i_r)
i_g=hist_ave_2(i_g)
i_b=hist_ave_2(i_b)
img_co[:,:,0]=i_r
img_co[:,:,1]=i_g
img_co[:,:,2]=i_b
fig,(ax0,ax1)=plt.subplots(1,2)
fig.dpi=150
ax0.imshow(img)
ax0.set_title("Original")
ax1.imshow(img_co)
ax1.set_title("Color Image Enhancement(RGB)")
plt.show()
HSI颜色增强
HSI颜色增强是一种基于HSI色彩模型的图像增强技术,它的主要作用如下:
独立调整色相(Hue)、饱和度(Saturation)和亮度(Intensity):
HSI模型将颜色信息与亮度信息分开表示,这使得我们可以独立调整这三个属性,实现更精细的颜色控制。 增强色彩饱和度:
HSI颜色增强可以通过提高饱和度(Saturation)通道的值,来增强图像中物体的色彩鲜艳度。 调整色调(Hue)分布:
通过对色相(Hue)通道的调整,可以改变图像整体的色调分布,实现对色彩的特定优化。 改善亮度分布:
HSI颜色增强可以独立调整亮度(Intensity)通道,优化图像的整体亮度,消除过亮或过暗的区域。 增强视觉感受:
通过上述对色相、饱和度和亮度的独立控制,HSI颜色增强可以有效提升图像的视觉效果,使之更加生动清晰。 总之,HSI颜色增强是一种非常灵活的图像预处理手段,可以针对不同的色彩和亮度问题进行针对性的调整,从而大幅提升图像的视觉质量。在很多计算机视觉应用中都有广泛应用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import cv2
import numpy as np
from matplotlib import pyplot as plt
def hist_ave_2(src):
L=np.unique(src)
cdf=(np.histogram(src.flatten(),L.size)[0]/src.size).cumsum()
cdf=(cdf*L.max()+0.5)
return np.interp(src.flatten(),L,cdf).reshape(src.shape)
img=cv2.imread("/pic/2.jpg")
img_=img.copy()
img_=cv2.cvtColor(img_,cv2.COLOR_BGR2HSV)
#对I通道进行处理
i_i=img_[:,:,2]
i_i=hist_ave_2(i_i)
img_[:,:,2]=i_i
img_=cv2.cvtColor(img_,cv2.COLOR_HSV2RGB)
fig,(ax0,ax1)=plt.subplots(1,2)
fig.dpi=150
ax0.imshow(img)
ax0.set_title("Original")
ax1.imshow(img_)
ax1.set_title("Color Image Enhancement(HSI)")
plt.show()
减色处理——色彩量化
概述:将图像用 32、96、160、224 这4个像素值表示。即将图像由256³压缩至4³,RGB的值只取{32,96,160,224},这被称作色彩量化。
减色处理 - 色彩量化(Color Quantization)的主要作用包括:
降低图像的颜色数量:
色彩量化通过将图像的颜色空间压缩到较小的颜色集合中,可以大幅减少图像中使用的颜色数量。 减小图像文件大小:
通过减少颜色数量,色彩量化可以有效压缩图像的文件大小,降低存储和传输的资源消耗。这在一些对存储空间或带宽有要求的应用中非常有用。 提高图像的渲染效率:
减少颜色数量可以降低图像的渲染复杂度,提高在某些设备(如嵌入式系统)上的渲染速度。 改善特定设备的显示效果:
某些设备(如老旧显示器)可能只支持较少的颜色数量。色彩量化可以将图像的颜色映射到设备支持的颜色空间,从而确保图像在该设备上显示正确。 增强图像的艺术效果:
有时通过有意识地减少颜色数量,可以为图像增添一些复古、绘画等特殊的艺术效果。 总的来说,色彩量化是一种常用的图像预处理技术,它可以根据实际需求有效地减少图像的颜色数量,从而在存储、渲染、显示等方面带来优势。在某些创作性应用中也有特殊的艺术价值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import cv2
import numpy as np
# 减色处理
def dicrease_color(img):
out = img.copy()
out = out // 64 * 64 + 32
return out
# 读入图像
img = cv2.imread("/pic/3.jpg")
img = cv2.resize(img,(800,600))
# 减色处理,也叫色彩量化
out = dicrease_color(img)
cv2.imwrite("/pic/2.jpg", out)
cv2.imshow("result", out)
cv2.waitKey(0)
cv2.destroyAllWindows()


彩色空间转换(RGB与HSI)
彩色空间转换(RGB to HSI)的主要作用包括:
分离亮度和色彩信息:
RGB颜色空间将颜色信息与亮度信息耦合在一起,而转换到HSI颜色空间后,可以将色相(Hue)、饱和度(Saturation)和亮度(Intensity)三个特性独立表示。这对于图像处理和分析很有帮助。 增强色彩特性的控制:
由于HSI模型独立表示了色彩信息和亮度信息,我们可以对这些特性进行更精细的调整和控制,如独立调整饱和度或色相等。这在图像增强、颜色校正等应用中很有用。 改善图像的视觉质量:
通过HSI颜色空间的转换和独立调整,可以有效改善图像的色彩表现和亮度分布,从而提升整体的视觉质量。 支持基于颜色的图像分析:
HSI模型的色彩特性描述更接近人类的感知,因此在基于颜色的图像分割、对象检测等计算机视觉任务中更有优势。 压缩和编码的优化:
有时将RGB图像转换为HSI后,可以利用HSI各通道的特性,对图像进行更高效的压缩和编码。 总之,颜色空间的转换,特别是从RGB到HSI,可以为图像处理和分析提供更多的自由度和控制力,从而优化图像的视觉质量和性能。这种技术在很多计算机视觉应用中都有广泛应用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
import matplotlib.pyplot as plt
import cv2 as cv
import numpy as np
# 显示汉字用
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义显示一张图片函数
def imshow(image):
if image.ndim == 2:
plt.imshow(image, cmap='gray') # 指定为灰度图像
else:
plt.imshow(cv.cvtColor(image, cv.COLOR_BGR2RGB))
# 定义坐标数字字体及大小
def label_def():
plt.xticks(fontproperties='Times New Roman', size=8)
plt.yticks(fontproperties='Times New Roman', size=8)
plt.axis('off') # 关坐标,可选
# 读取图片
img_orig = cv.imread('/pic/2.jpg', 1) # 读取彩色图片
# RGB到HSI的变换
def rgb2hsi(image):
b, g, r = cv.split(image) # 读取通道
r = r / 255.0 # 归一化
g = g / 255.0
b = b / 255.0
eps = 1e-6 # 防止除零
img_i = (r + g + b) / 3 # I分量
img_h = np.zeros(r.shape, dtype=np.float32)
img_s = np.zeros(r.shape, dtype=np.float32)
min_rgb = np.zeros(r.shape, dtype=np.float32)
# 获取RGB中最小值
min_rgb = np.where((r <= g) & (r <= b), r, min_rgb)
min_rgb = np.where((g <= r) & (g <= b), g, min_rgb)
min_rgb = np.where((b <= g) & (b <= r), b, min_rgb)
img_s = 1 - 3*min_rgb/(r+g+b+eps) # S分量
num = ((r-g) + (r-b))/2
den = np.sqrt((r-g)**2 + (r-b)*(g-b))
theta = np.arccos(num/(den+eps))
img_h = np.where((b-g) > 0, 2*np.pi - theta, theta) # H分量
img_h = np.where(img_s == 0, 0, img_h)
img_h = img_h/(2*np.pi) # 归一化
temp_s = img_s - np.min(img_s)
temp_i = img_i - np.min(img_i)
img_s = temp_s/np.max(temp_s)
img_i = temp_i/np.max(temp_i)
image_hsi = cv.merge([img_h, img_s, img_i])
return img_h, img_s, img_i, image_hsi
# HSI到RGB的变换
def hsi2rgb(image_hsi):
eps = 1e-6
img_h, img_s, img_i = cv.split(image_hsi)
image_out = np.zeros((img_h.shape[0], img_h.shape[1], 3))
img_h = img_h*2*np.pi
print(img_h)
img_r = np.zeros(img_h.shape, dtype=np.float32)
img_g = np.zeros(img_h.shape, dtype=np.float32)
img_b = np.zeros(img_h.shape, dtype=np.float32)
# 扇区1
img_b = np.where((img_h >= 0) & (img_h < 2 * np.pi / 3), img_i * (1 - img_s), img_b)
img_r = np.where((img_h >= 0) & (img_h < 2 * np.pi / 3),
img_i * (1 + img_s * np.cos(img_h) / (np.cos(np.pi/3 - img_h))), img_r)
img_g = np.where((img_h >= 0) & (img_h < 2 * np.pi / 3), 3 * img_i - (img_r + img_b), img_g)
# 扇区2 # H=H-120°
img_r = np.where((img_h >= 2*np.pi/3) & (img_h < 4*np.pi/3), img_i * (1 - img_s), img_r)
img_g = np.where((img_h >= 2*np.pi/3) & (img_h < 4*np.pi/3),
img_i * (1 + img_s * np.cos(img_h-2*np.pi/3) / (np.cos(np.pi - img_h))), img_g)
img_b = np.where((img_h >= 2*np.pi/3) & (img_h < 4*np.pi/3), 3 * img_i - (img_r + img_g), img_b)
# 扇区3 # H=H-240°
img_g = np.where((img_h >= 4*np.pi/3) & (img_h <= 2*np.pi), img_i * (1 - img_s), img_g)
img_b = np.where((img_h >= 4*np.pi/3) & (img_h <= 2*np.pi),
img_i * (1 + img_s * np.cos(img_h-4*np.pi/3) / (np.cos(5*np.pi/3 - img_h))), img_b)
img_r = np.where((img_h >= 4*np.pi/3) & (img_h <= 2*np.pi), 3 * img_i - (img_b + img_g), img_r)
temp_r = img_r - np.min(img_r)
img_r = temp_r/np.max(temp_r)
temp_g = img_g - np.min(img_g)
img_g = temp_g/np.max(temp_g)
temp_b = img_b - np.min(img_b)
img_b = temp_b/np.max(temp_b)
image_out = cv.merge((img_r, img_g, img_b)) # 按RGB合并,后面不用转换通道
# print(image_out.shape)
return image_out
if __name__ == '__main__': # 运行当前函数
h, s, i, hsi = rgb2hsi(img_orig) # RGB到HSI的变换
img_revise = np.float32(hsi2rgb(hsi)) # HSI复原到RGB
# h, s, i = cv.split(cv.cvtColor(img_orig, cv.COLOR_BGR2HSV)) # 自带库函数HSV模型
im_b, im_g, im_r = cv.split(img_orig) # 获取RGB通道数据
plt.subplot(241), plt.imshow(cv.cvtColor(img_orig, cv.COLOR_BGR2RGB)), plt.title('原始图'), label_def()
plt.subplot(242), plt.imshow(im_r, 'gray'), plt.title('R'), label_def()
plt.subplot(243), plt.imshow(im_g, 'gray'), plt.title('G'), label_def()
plt.subplot(244), plt.imshow(im_b, 'gray'), plt.title('B'), label_def()
plt.subplot(245), plt.imshow(hsi), plt.title('HSI图'), label_def()
plt.subplot(246), plt.imshow(h, 'gray'), plt.title('H(色调)'), label_def()
plt.subplot(247), plt.imshow(s, 'gray'), plt.title('S(饱和度)'), label_def()
plt.subplot(248), plt.imshow(i, 'gray'), plt.title('I(亮度)'), label_def()
plt.show()
plt.subplot(121), plt.imshow(cv.cvtColor(img_orig, cv.COLOR_BGR2RGB)), plt.title('原RGB'), label_def()
plt.subplot(122), plt.imshow(img_revise), plt.title('HSI重建RGB'), label_def()
plt.show()




彩色图像直方图均衡化
彩色图像直方图均衡化的主要作用包括:
增强图像对比度:
直方图均衡化通过拉伸图像灰度或颜色分布,可以显著提高图像的对比度,使暗区和亮区的细节更加清晰可见。 改善亮度分布:
均衡化后,图像的亮度分布会更加均匀,避免出现过暗或过亮的区域,从而提升整体的视觉质量。 增强图像细节表现:
通过对比度和亮度的优化,直方图均衡化能够突出图像中的细节和纹理,使物体轮廓和特征更加清晰。 提高图像分析的效果:
增强的对比度和细节有利于后续的图像分割、特征提取等计算机视觉任务,提高算法的鲁棒性。 改善视觉效果:
直方图均衡化可以使图像看起来更加生动、清晰,增强人类观察者的视觉体验。 兼容多种设备显示:
均衡化后的图像在不同设备上的显示效果更加一致,避免出现失真或偏色的问题。 总的来说,彩色图像直方图均衡化是一种常用的预处理技术,它可以有效改善图像的对比度、亮度分布和细节表现,从而提升图像的视觉质量和分析性能。在很多计算机视觉应用中都有广泛使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#6. 彩色图像直方图均衡化
import numpy as np
import cv2
def hisEqulColor(img):
ycrcb = cv2.cvtColor(img, cv2.COLOR_BGR2YCR_CB)
channels = cv2.split(ycrcb)
print(len(channels))
cv2.equalizeHist(channels[0], channels[0])
cv2.merge(channels, ycrcb)
cv2.cvtColor(ycrcb, cv2.COLOR_YCR_CB2BGR, img)
return img
im = cv2.imread('/pic/2.jpg')
print(np.shape(im))
im=cv2.resize(im,(800,600))
cv2.imshow('im1', im)
cv2.waitKey(0)
eq = hisEqulColor(im)
cv2.imshow('image2',eq )
cv2.waitKey(0)




方法2(翻转,色域变换,噪声,大小改变,模糊,色彩抖动,均衡化)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
#已有:翻转,色域变换,噪声,大小改变,模糊,色彩抖动,均衡化
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image,ImageEnhance
from matplotlib.colors import rgb_to_hsv, hsv_to_rgb
import os
import random
#限制对比度自适应直方图均衡
def clahe(image):
b, g, r = cv2.split(image)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
b = clahe.apply(b)
g = clahe.apply(g)
r = clahe.apply(r)
image_clahe = cv2.merge([b, g, r])
return image_clahe
#伽马变换
def gamma(image):
fgamma = 2
image_gamma = np.uint8(np.power((np.array(image) / 255.0), fgamma) * 255.0)
cv2.normalize(image_gamma, image_gamma, 0, 255, cv2.NORM_MINMAX)
cv2.convertScaleAbs(image_gamma, image_gamma)
return image_gamma
#直方图均衡
def hist(image):
r, g, b = cv2.split(image)
r1 = cv2.equalizeHist(r)
g1 = cv2.equalizeHist(g)
b1 = cv2.equalizeHist(b)
image_equal_clo = cv2.merge([r1, g1, b1])
return image_equal_clo
#椒盐噪声
def sp_noise(image):
output = np.zeros(image.shape,np.uint8)
prob=rand(0.0005,0.001)
thres = 1 - prob
for i in range(image.shape[0]):
for j in range(image.shape[1]):
rdn = random.random()
if rdn < prob:
output[i][j] = 0
elif rdn > thres:
output[i][j] = 255
else:
output[i][j] = image[i][j]
return output
#色彩抖动
def randomColor(image):
saturation=random.randint(0,1)
brightness=random.randint(0,1)
contrast=random.randint(0,1)
sharpness=random.randint(0,1)
if random.random() < saturation:
random_factor = np.random.randint(0, 31) / 10. # 随机因子
image = ImageEnhance.Color(image).enhance(random_factor) # 调整图像的饱和度
if random.random() < brightness:
random_factor = np.random.randint(10, 21) / 10. # 随机因子
image = ImageEnhance.Brightness(image).enhance(random_factor) # 调整图像的亮度
if random.random() < contrast:
random_factor = np.random.randint(10, 21) / 10. # 随机因1子
image = ImageEnhance.Contrast(image).enhance(random_factor) # 调整图像对比度
if random.random() < sharpness:
random_factor = np.random.randint(0, 31) / 10. # 随机因子
ImageEnhance.Sharpness(image).enhance(random_factor) # 调整图像锐度
return image
def rand(a=0, b=1):
return np.random.rand()*(b-a) + a
def get_data(image,input_shape=[200,200],random=True, jitter=.5,hue=.1, sat=1.5, val=1.5, proc_img=True):
iw, ih = image.size
h, w = input_shape
# 对图像进行缩放并且进行长和宽的扭曲
new_ar = w/h * rand(1-jitter,1+jitter)/rand(1-jitter,1+jitter)
scale = rand(.15,2.5)
if new_ar < 1:
nh = int(scale*h)
nw = int(nh*new_ar)
else:
nw = int(scale*w)
nh = int(nw/new_ar)
image = image.resize((nw,nh), Image.BICUBIC)
# 翻转图像
flip = rand()<.5
if flip:
image = image.transpose(Image.FLIP_LEFT_RIGHT)
#噪声或者虚化,二选一
image = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
a1=np.random.randint(0, 3)
if a1==0:
image=sp_noise(image)
elif a1==1:
image=cv2.GaussianBlur(image, (5, 5), 0)
else:
image=image
#均衡化
index_noise = np.random.randint(0, 10)
print(index_noise)
if index_noise==0:
image = hist(image)
print('hist,done')
elif index_noise==1:
image = clahe(image)
print('clahe,done')
elif index_noise==2:
image = gamma(image)
print('gamma,done')
else:
image=image
image = Image.fromarray(cv2.cvtColor(image,cv2.COLOR_BGR2RGB))
#色彩抖动
image=randomColor(image)
print(image.size)
# 色域扭曲
hue = rand(-hue, hue)
sat = rand(1, sat) if rand()<.5 else 1/rand(1, sat)
val = rand(1, val) if rand()<.5 else 1/rand(1, val)
x = rgb_to_hsv(np.array(image)/255.)
x[..., 0] += hue
x[..., 0][x[..., 0]>1] -= 1
x[..., 0][x[..., 0]<0] += 1
x[..., 1] *= sat
x[..., 2] *= val
x[x>1] = 1
x[x<0] = 0
image_data = hsv_to_rgb(x)
image_data=np.array(image)
return image_data
if __name__ == "__main__":
#图像批量处理
dirs='./class_pic3/407_3/' #原始图像所在的文件夹
dets='./class_pic3/dets/407_3/' #图像增强后存放的文件夹
mylist=os.listdir(dirs)
l=len(mylist) #文件夹图片的数量
for j in range(0,l):
image = cv2.imread(dirs+mylist[j])
img = Image.fromarray(np.uint8(image))
for i in range(0,2): #自定义增强的张数
img_ret=get_data(img)
#imwrite(存入图片路径+图片名称+‘.jpg’,img)
#注意:名称应该是变化的,不然会覆盖原来的图片
cv2.imwrite(dets+'1'+str(j)+'0'+str(i)+'.jpg',img_ret)
print('done')
#单个图像处理
'''
image=cv2.imread("./class_pic3/323/002.jpg")
img = Image.fromarray(np.uint8(image))
for i in range(0,4):
img_ret=get_data(img)
cv2.imwrite('./class_pic3/323'+'02'+str(i)+'.jpg',img_ret)
print('done')
'''
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
一、增加噪声
在图像中增加适量噪声可以增强学习能力。噪声有很多种,常见的有椒盐噪声,高斯噪声等。
1.椒盐噪声:一种随机出现的白点或者黑点,可能是亮的区域有黑色像素或是在暗的区域有白色像素(或是两者皆有)。
2.高斯噪声:概率密度函数服从高斯分布。
二、滤波(模糊)处理
滤波处理主要是让图像变得模糊,提取图像的重要信息。常见的模糊处理有:高斯模糊,中值模糊,均值(椒盐)模糊。
三、旋转
图像的大小不变,可以将图像进行上下旋转,左右旋转等增加数据量,一般根据自己的需求,有些数据旋转之后就不符合原数据的要求了。
四、图像缩放
可以通过改变图像的大小对数据增强,但有可能会引起图像的失真。
五、色彩抖动
色彩抖动是通过随机调整原始图片的饱和度,亮度,对比度来对产生新的图像,增加数据集
六、图像均衡化
图像均衡化
图像均衡化的主要作用如下:
增强图像对比度:
图像均衡化通过拉伸图像的灰度直方图,可以有效地提高图像的对比度,使暗区和亮区的细节更加清晰。 改善亮度分布:
均衡化后,图像的亮度分布会更加均匀,避免出现过暗或过亮的区域,从而提升整体的视觉质量。 突出图像细节:
增强的对比度可以突出图像中的细节和纹理,使物体轮廓和特征更加清晰可见。 提高后续分析的效果:
优化的对比度和亮度有利于后续的图像分割、特征提取等计算机视觉任务,提高算法的鲁棒性。 改善视觉效果:
图像均衡化可以使图像看起来更加生动、清晰,提升人类观察者的视觉体验。 增强跨设备显示一致性:
均衡化后的图像在不同设备上的显示效果会更加一致,避免出现失真或偏色的问题。 你提供的代码中包含了几种常见的图像增强方法:
CLAHE(Contrast Limited Adaptive Histogram Equalization)限制对比度自适应直方图均衡化 Gamma变换 直方图均衡化 这些方法都是从不同角度来提高图像的对比度、亮度分布和细节表现,以改善图像的视觉效果和分析性能。它们可以根据实际需求单独使用或组合使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#限制对比度自适应直方图均衡
def clahe(image):
b, g, r = cv2.split(image)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
b = clahe.apply(b)
g = clahe.apply(g)
r = clahe.apply(r)
image_clahe = cv2.merge([b, g, r])
return image_clahe
#伽马变换
def gamma(image):
fgamma = rand(0,2)
image_gamma = np.uint8(np.power((np.array(image) / 255.0), fgamma) * 255.0)
cv2.normalize(image_gamma, image_gamma, 0, 255, cv2.NORM_MINMAX)
cv2.convertScaleAbs(image_gamma, image_gamma)
return image_gamma
#直方图均衡
def hist(image):
r, g, b = cv2.split(image)
r1 = cv2.equalizeHist(r)
g1 = cv2.equalizeHist(g)
b1 = cv2.equalizeHist(b)
image_equal_clo = cv2.merge([r1, g1, b1])
return image_equal_clo

分析总结
数据增强有很多的方法,我可以从两方面下手,一是色彩的变化,二是提高图像的质量(噪声、滤波..)
目标: 1.色彩变化 2.提高图像质量
- 色彩变化
图像均衡化、像素反转、色彩抖动、色彩增强、rgb颜色增强、hsi颜色增强、减色处理——色彩量化、彩色空间转换(RGB与HSI)、彩色图像直方图均衡化
问题:我训练了一个yolov5-lite模型,但使用于视频检测的时候,却发现很难识别,我怀疑是光线的问题,训练的数据集都是那种很亮的图片,而实际测试的时候,测试的环境近乎在黄昏的环境,就是环境光线比较暗。 我学习了解了一下关于增强数据集的方法,主要集中在色彩变化的方面。 我了解到了图像均衡化、像素反转、色彩抖动、色彩增强、rgb颜色增强、hsi颜色增强、减色处理——色彩量化、彩色空间转换(RGB与HSI)、彩色图像直方图均衡化。方法有很多,我该如何选择?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
回答(gpt3.5):
当面临光线变化问题时,增强数据集中的色彩变化方法是一个很好的选择。您提到的方法包括图像均衡化、像素反转、色彩抖动、色彩增强、RGB颜色增强、HSI颜色增强、减色处理和彩色空间转换等,它们都可以用于改善模型在不同光线条件下的性能。
选择哪种方法取决于您的具体需求和数据集的特点。以下是一些建议:
1. 图像均衡化:这种方法可以增加图像的对比度,使得暗部和亮部的区别更加明显。适用于光线不均匀或过暗的情况。
2. 像素反转:将图像的像素值进行反转,可以使亮部变暗、暗部变亮。适用于光线过亮或过暗的情况。
3. 色彩抖动:通过随机调整图像的饱和度、亮度和对比度等参数,引入一定程度的随机性,增加数据的多样性。适用于光线变化较大的情况。
4. 色彩增强:可以通过调整图像的饱和度、亮度和对比度等参数来增强图像的色彩效果。适用于光线较暗的情况。
5. RGB颜色增强:可以在RGB颜色空间中调整图像的通道值来改变图像的色彩效果。适用于特定场景下的色彩调整。
6. HSI颜色增强:可以在HSI颜色空间中调整图像的色调、饱和度和亮度等参数来改变图像的色彩效果。适用于特定场景下的色彩调整。
7. 减色处理:通过将图像的颜色数量减少到一定程度来简化图像的色彩信息,适用于某些特定任务或特殊效果的需求。
8. 彩色空间转换:可以将图像从RGB颜色空间转换到其他颜色空间(如HSI、Lab等),利用其他颜色通道的信息来增强图像的色彩效果。
9. 彩色图像直方图均衡化:可以通过调整图像的直方图分布来增强图像的对比度和色彩效果。
在选择适当的方法时,建议先使用少量样本进行测试和评估,以确定哪种方法在您的场景中效果最好。同时,可以尝试组合多种方法,以获得更好的结果。
最重要的是,确保在增强数据集时保持标签与图像的一致,以确保训练的模型能够正确地预测目标的位置和类别。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
回答(newbing):
数据增强在训练深度学习模型时非常重要,特别是在数据量有限的情况下。对于你的问题,选择合适的数据增强方法可以帮助提高模型的鲁棒性和泛化能力。以下是一些常用的数据增强方法,你可以根据你的具体情况选择合适的方法:
基础数据增强方法:
几何变换:包括旋转、平移、剪切和错切等。这些操作可以模拟不同角度和位置的目标。
颜色变换:调整亮度、对比度、饱和度和色调。这有助于模型对不同光照条件下的图像更具鲁棒性。
高级数据增强方法:
图像均衡化:用于增加图像的对比度,特别适用于光照不均匀的情况。
像素反转:将图像的像素值进行反转,有助于增加数据集的多样性。
色彩抖动:随机改变图像的颜色,增加数据的多样性。
RGB颜色增强:通过调整RGB通道的值来改变图像的颜色。
HSI颜色增强:在HSI颜色空间中调整亮度、饱和度和色调。
彩色空间转换:将图像从RGB转换为其他颜色空间,如HSV或Lab。
彩色图像直方图均衡化:用于增加图像的对比度,特别适用于光照不均匀的情况。
根据你的实际需求,你可以选择一个或多个方法来增强你的数据集。不同任务和数据集可能需要不同的策略,因此建议你在实验中尝试不同的增强方法,然后根据模型的性能来选择最合适的方法。
newbing说是接入了gpt4.0,但感觉比gpt3.5还笨,不好用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
回答(claude-3-sonnet):
针对您所描述的情况,我建议您可以尝试以下几种数据增强方法:
1. 亮度调整
由于您的训练数据集中的图像都比较亮,而测试环境较暗,因此调整训练数据的亮度非常重要。您可以尝试降低部分图像的亮度,模拟暗光环境。
2. 对比度增强
增加图像对比度也可以模拟暗光环境下目标和背景的差异。您可以尝试直方图均衡化等方法来增强对比度。
3. 高斯噪声
添加高斯噪声可以模拟低光照条件下的图像噪点,有助于提高模型的鲁棒性。
4. 颜色空间转换
将RGB图像转换到HSV或者其他颜色空间,分别对亮度(V)、饱和度(S)等通道做调整,可以模拟不同光照条件。
5. 混合亮暗图像
在训练集中直接混合一些低光照的图像,让模型直接学习在暗环境下的特征。
总的来说,我建议您从调整亮度、对比度入手,结合颜色空间转换和添加噪声的方法,尝试不同的组合寻找最佳的增强策略。同时也可以收集一些真实的暗光环境图像,直接添加到训练集中。
通过恰当的数据增强,相信您的模型在暗光环境下的检测精度会得到显著提升。祝工作顺利!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
回答(claude-3-haiku):
针对你提出的问题,我给出以下建议:
数据集增强策略的选择需要结合实际的问题和模型特点进行选择。在本例中,你提到了训练数据集多为亮环境,而实际测试环境较为阴暗,所以建议着重关注以下几种数据增强方法:
亮度增强(Brightness Adjustment): 随机调整图像亮度,以模拟不同光照条件。这可以帮助模型对不同光照条件更鲁棒。
对比度增强(Contrast Adjustment): 随机调整图像对比度,以更好地适应各种环境光照。
色彩抖动(Color Jittering): 随机调整图像的色彩通道,增加模型对色彩变化的适应能力。
灰度转换(Grayscale Conversion): 将部分训练图像转换为灰度图像,增加模型对黑白场景的鲁棒性。
除了数据增强,你也可以尝试以下技巧:
在训练过程中引入一些暗光环境的图像数据,以增加模型对暗光场景的适应能力。
调整模型参数,如增加网络深度或宽度,以增强模型的特征提取能力。
考虑使用一些专门针对低光环境的目标检测算法,如基于直方图的算法等。
总的来说,数据增强策略的选择需要结合实际问题,多尝试不同方法,并通过实验评估效果,找到最合适的方案。此外,还可以考虑模型结构和参数的调整,以提高模型在暗光环境下的性能。
希望以上建议对你的问题有所帮助。如有其他疑问,欢迎继续交流。
总结:可以先从亮度、对比度、饱和度入手、然后再增加噪声和颜色空间变化
数据增强2
图像均衡化、像素反转、色彩抖动、色彩增强、rgb颜色增强、hsi颜色增强、减色处理——色彩量化、彩色空间转换(RGB与HSI)、彩色图像直方图均衡化。
亮度调整:
- 亮度增强(Brightness Adjustment)
对比度调整:
- 对比度增强(Contrast Adjustment)
饱和度调整:
- RGB颜色增强(提饱和、颜色鲜艳自然、可突出重点区域)
综合:
- 图像均衡化(改善对比亮度、突出细节、改善失真偏色、提高质量)
- 色彩抖动(3、4度调整增加数据集)
- 色彩增强(3度调整、亮度均匀、提质、用于高反差或阴暗图片)
- HSI颜色增强(3、4度调整增加数据集、颜色鲜艳)
- 彩色图像直方图均衡化(改善对比亮度、突出细节、改善失真偏色、提高质量)
- 颜色空间变化:
- 彩色空间转换(分离色彩和亮度,实现精细化调整)
质量:
- 噪声(增强学习能力)
- 滤波(提取重要信息)
噪声增加:
- 像素反转
减色处理:
- 减色处理-色彩量化
尝试1: 对300张数据集进行4度的调整,并进行训练
分析:我已知道了四度调整的代码,但如何应用于YOLOv5-lite之中呢。我应该了解学习这个模型的训练的代码,了解准备数据集、数据集预处理,到训练数据集的这几个过程。然后在数据集预处理中加入调整的代码。
YOLOv5-lite模型的修改
问题:我应该要如何学习YOLOv5-lite,我希望了解,然后尝试着去调整模型,如在加载数据集的时候,调整数据集图片的亮度,饱和度等。我希望做到这些动作,我应该如何去学习
1
很好,学习 YOLOv5-lite 并尝试调整模型是一个非常不错的计划。以下是我的建议:
- 基础知识学习:
- 首先,学习深度学习和计算机视觉的基础知识,包括卷积神经网络、目标检测等概念。这将帮助你更好地理解 YOLOv5-lite 的工作原理。
- 了解 YOLO 系列模型的基本原理和特点,包括它们与R-CNN、SSD等其他目标检测模型的区别。
- YOLOv5-lite 实践:
- 从 YOLOv5-lite 的官方GitHub仓库开始,仔细阅读文档和代码,理解它的输入、输出、训练和推理流程。
- 尝试在常见的数据集(如COCO、Pascal VOC等)上训练和测试 YOLOv5-lite 模型,观察模型的性能。
- 了解如何在自己的数据集上微调 YOLOv5-lite 模型,包括数据集准备、数据增强、训练超参数调整等。
- 调整模型:
- 学习如何修改 YOLOv5-lite 的网络结构,如改变backbone、neck和head等模块。
- 掌握如何调整数据预处理步骤,如改变图像的亮度、饱和度等。这可以通过PyTorch或OpenCV等库实现。
- 尝试不同的数据增强方式,如随机裁剪、翻转、旋转等,观察对模型性能的影响。
- 学习资源:
- 观看 YOLOv5-lite 相关的教程视频,了解其他用户的实践经验。
- 阅读相关论文和技术博客,跟上该领域的最新进展。
- 加入相关的社区或论坛,与其他开发者交流和讨论。
1
总之,学习 YOLOv5-lite 需要循序渐进,从基础知识开始,通过大量实践和尝试来掌握模型的调整技巧。希望这些建议对你有所帮助。如有任何其他问题,欢迎随时询问。
过程: 1.询问gpt修改的文件,了解相关的代码,溯源至使用的地方 2.尝试改变图像亮度和饱和度
询问gpt修改的文件,了解相关的代码,溯源至使用的地方
这是train文件的main里训练的代码,主要是关于是否恢复训练,然后执行train()函数。train()里的create_dataloader()是负责创建数据加载器,并根据参数配置加载相应的数据集。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
# 设置分布式训练相关的环境变量
opt.world_size = int(os.environ['WORLD_SIZE']) if 'WORLD_SIZE' in os.environ else 1
opt.global_rank = int(os.environ['RANK']) if 'RANK' in os.environ else -1
set_logging(opt.global_rank)
if opt.global_rank in [-1, 0]:
check_git_status()
check_requirements()
# 检查是否恢复训练
wandb_run = check_wandb_resume(opt)
if opt.resume and not wandb_run: # 恢复中断的训练
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run()
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
apriori = opt.global_rank, opt.local_rank
with open(Path(ckpt).parent.parent / 'opt.yaml') as f:
opt = argparse.Namespace(**yaml.load(f, Loader=yaml.SafeLoader)) # 从保存的配置中读取
opt.cfg, opt.weights, opt.resume, opt.batch_size, opt.global_rank, opt.local_rank = '', ckpt, True, opt.total_batch_size, *apriori # 重新设置参数
logger.info('Resuming training from %s' % ckpt)
else:
opt.data, opt.cfg, opt.hyp = check_file(opt.data), check_file(opt.cfg), check_file(opt.hyp) # 检查配置文件
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
opt.img_size.extend([opt.img_size[-1]] * (2 - len(opt.img_size))) # 扩展图像尺寸
opt.name = 'evolve' if opt.evolve else opt.name
opt.save_dir = increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok | opt.evolve) # 创建保存路径
# 设置分布式训练
opt.total_batch_size = opt.batch_size
device = select_device(opt.device, batch_size=opt.batch_size)
if opt.local_rank != -1:
assert torch.cuda.device_count() > opt.local_rank
torch.cuda.set_device(opt.local_rank)
device = torch.device('cuda', opt.local_rank)
dist.init_process_group(backend='nccl', init_method='env://') # 初始化分布式训练
assert opt.batch_size % opt.world_size == 0, '--batch-size must be multiple of CUDA device count'
opt.batch_size = opt.total_batch_size // opt.world_size
# 加载超参数
with open(opt.hyp) as f:
hyp = yaml.load(f, Loader=yaml.SafeLoader) # 从配置文件中读取超参数
# 开始训练
logger.info(opt)
if not opt.evolve:
tb_writer = None # 初始化日志记录器
if opt.global_rank in [-1, 0]:
prefix = colorstr('tensorboard: ')
logger.info(f"{prefix}Start with 'tensorboard --logdir {opt.project}', view at http://localhost:6006/")
tb_writer = SummaryWriter(opt.save_dir) # 创建 Tensorboard 记录器
train(hyp, opt, device, tb_writer) # 开始训练
else:
# 进行超参数进化
meta = {...} # 超参数进化的元数据
assert opt.local_rank == -1, 'DDP mode not implemented for --evolve'
opt.notest, opt.nosave = True, True # 只测试和保存最终结果
for _ in range(300): # 进化 300 代
if Path('evolve.txt').exists(): # 如果 evolve.txt 存在, 读取最佳结果并突变
# 选择父代
parent = 'single' # 父代选择方式: 'single' or 'weighted'
x = np.loadtxt('evolve.txt', ndmin=2)
n = min(5, len(x)) # 考虑之前的 n 个最佳结果
x = x[np.argsort(-fitness(x))][:n] # 选择前 n 个最佳结果
w = fitness(x) - fitness(x).min() # 计算权重
if parent == 'single':
x = x[random.choices(range(n), weights=w)[0]] # 加权随机选择
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # 加权组合
# 突变
mp, s = 0.8, 0.2 # 突变概率和标准差
hyp = mutate_hyperparameters(hyp, meta, mp, s) # 突变超参数
# 训练并记录结果
results = train(hyp.copy(), opt, device)
print_mutation(hyp.copy(), results, yaml_file, opt.bucket)
# 绘制进化结果
plot_evolution(yaml_file)
print(f'Hyperparameter evolution complete. Best results saved as: {yaml_file}\n'
f'Command to train a new model with these hyperparameters: $ python train.py --hyp {yaml_file}')
上面这段代码是train里面的训练的代码,主要完成以下功能:
- 设置分布式训练的环境变量和日志记录。
- 检查是否需要恢复之前的训练,如果是,则从检查点继续训练。
- 准备训练所需的配置文件和数据集。
- 设置分布式训练的相关参数。
- 加载超参数配置文件。
- 如果不进行超参数进化,则开始训练模型,并使用 Tensorboard 记录训练过程。
- 如果进行超参数进化,则使用遗传算法的方式不断突变超参数,并训练模型,记录结果。最终输出最佳超参数配置。
问题:尝试着去调整模型,如在加载数据集的时候,调整数据集图片的亮度,饱和度等。我希望做到这些动作,我应该从哪部分的代码那里入手,然后我又该怎么做
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
要在加载数据集时调整图像的亮度、饱和度等属性,你需要从 YOLOv5-lite 的数据预处理部分入手。具体来说,可以从以下几个步骤着手:
1. **找到数据增强的代码位置**
- 在 YOLOv5-lite 的代码中,数据增强相关的代码主要位于 `utils/datasets.py` 文件中。
2. **定位图像预处理的代码**
- 在 `utils/datasets.py` 文件中,找到 `LoadImagesAndLabels` 类,它负责加载图像和标注数据。
- 在这个类的 `__getitem__` 方法中,可以看到图像预处理的相关代码,比如像素归一化、随机翻转等。
3. **添加亮度和饱和度调整的代码**
- 在 `__getitem__` 方法中,找到合适的位置添加调整亮度和饱和度的代码。
- 可以使用 OpenCV 或 Pillow 等库提供的函数来实现这些图像变换,例如:
```python
import cv2
import numpy as np
# 调整图像亮度
image = cv2.convertScaleAbs(image, alpha=1.1, beta=10)
# 调整图像饱和度
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
hsv[:, :, 1] = hsv[:, :, 1] * 1.2
image = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
```
4. **测试并观察模型性能**
- 在训练脚本 `train.py` 中,使用添加了亮度和饱和度调整的数据集进行训练。
- 观察模型在验证集上的性能指标,如 mAP、F1 score 等,并与原模型进行对比,评估调整的效果。
5. **根据结果进行进一步优化**
- 如果模型性能有提升,可以尝试调整亮度和饱和度的幅度,找到最佳的数据增强参数。
- 如果模型性能下降,可以回到之前的版本,或者尝试其他形式的数据增强,如随机裁剪、旋转等。
总的来说,通过修改 `utils/datasets.py` 文件中的数据预处理代码,你可以轻松地在加载数据集时调整图像的亮度和饱和度。在实践中,需要反复测试,找到最佳的数据增强策略,以提高 YOLOv5-lite 模型的性能。如有任何其他问题,欢迎继续询问。
在utils/datasets.py文件中找到LoadImagesAndLabels 类,阅读函数
问题: class LoadImagesAndLabels(Dataset): # for training/testing def init(self, path, img_size=640, batch_size=16, augment=False, hyp=None, rect=False, image_weights=False, cache_images=False, single_cls=False, stride=32, pad= ……….return torch.stack(img4, 0), torch.cat(label4, 0), path4, shapes4 给我一些注释,知道这个类每个模块的作用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这个类是一个用于加载图片和标签的PyTorch数据集类,通常用于目标检测任务的训练和测试。它支持多种数据增强方法,包括mosaic拼接、MixUp等,以及正常的图像处理操作,如缩放、裁剪和颜色空间的变换。以下是一些关键部分的解释:LoadImagesAndLabels
初始化(__init__):
path: 数据集的路径,可以是包含图像的目录,或者是包含图像列表的文本文件。
img_size: 输入图像的大小。
batch_size: 批量大小,用于计算某些操作,如矩形训练。
augment: 是否应用数据增强。
hyp: 超参数字典,控制数据增强的各个方面。
rect: 是否使用矩形训练,这可以加速训练并节省内存,特别是当使用非正方形的输入时。
cache_images: 是否将图像缓存到内存中,以加速训练。
其他参数控制各种数据加载和处理选项。
cache_labels:
这个方法用于预处理和缓存数据集的标签和图像尺寸信息。这有助于加速后续的数据加载过程,因为不需要每次访问数据集时都重新计算这些信息。
__len__:
返回数据集中的图像数量。
__getitem__:
根据给定的索引加载和返回一张图像及其对应的标签。这包括选择图像处理和数据增强的方法,如mosaic、MixUp或简单的尺寸调整和裁剪。
整体来看,这个类提供了一个灵活的框架,用于加载和处理用于目标检测任务的图像数据,支持多种增强方法来提高模型的泛化能力。通过在训练过程中使用这种类型的数据加载和增强,可以帮助提高模型对于各种尺寸、形状和外观变化的目标的识别能力。
getitem 方法,它的主要功能是根据给定的索引加载和返回一张图像及其对应的标签。具体步骤如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
index = self.indices[index]:根据给定的索引获取对应的图像索引。
mosaic = self.mosaic and random.random() < hyp['mosaic']:根据预设的概率决定是否使用 Mosaic 数据增强技术。Mosaic 是一种将多张图像拼接成一张图像的技术,用于增加数据的多样性。
如果 mosaic 为真,执行以下操作:
调用 load_mosaic 函数加载 Mosaic 图像。
根据预设的概率决定是否使用 MixUp 数据增强技术,MixUp 是一种将两张图像按比例混合的技术,用于增加数据的多样性。
将加载的图像进行 Letterbox 处理,使其符合模型的输入尺寸要求。
如果 mosaic 为假,执行以下操作:
调用 load_image 函数加载单张图像。
将加载的图像进行 Letterbox 处理,使其符合模型的输入尺寸要求。
如果 self.augment 为真(开启数据增强),执行以下操作:
在图像空间进行随机透视变换。
在色彩空间进行随机 HSV 色彩增强。
应用 CutOut 数据增强技术。
如果 self.augment 为真,执行以下操作:
根据预设的概率决定是否对图像进行上下翻转。
根据预设的概率决定是否对图像进行左右翻转。
将标签数据转换成 PyTorch 张量形式。
将图像转换成 PyTorch 张量形式,并进行通道顺序转换和维度变换。
返回图像、标签、图像文件路径和形状信息。
self.augment 为真,由self.augment = augment,意味着是否开启数据增强,取决于LoadImagesAndLabels的第五个函数,意味着取决于create_dataloader的第七个参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
def create_dataloader(path, imgsz, batch_size, stride, opt, hyp=None, augment=False, cache=False, pad=0.0, rect=False,
rank=-1, world_size=1, workers=8, image_weights=False, quad=False, prefix=''):
# Make sure only the first process in DDP process the dataset first, and the following others can use the cache
with torch_distributed_zero_first(rank):
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
augment=augment, # augment images
hyp=hyp, # augmentation hyperparameters
rect=rect, # rectangular training
cache_images=cache,
single_cls=opt.single_cls,
stride=int(stride),
pad=pad,
image_weights=image_weights,
prefix=prefix)
batch_size = min(batch_size, len(dataset))
nw = min([os.cpu_count() // world_size, batch_size if batch_size > 1 else 0, workers]) # number of workers
sampler = torch.utils.data.distributed.DistributedSampler(dataset) if rank != -1 else None
loader = torch.utils.data.DataLoader if image_weights else InfiniteDataLoader
# Use torch.utils.data.DataLoader() if dataset.properties will update during training else InfiniteDataLoader()
dataloader = loader(dataset,
batch_size=batch_size,
num_workers=nw,
sampler=sampler,
pin_memory=True,
collate_fn=LoadImag.....```
```py
def create_dataloader(path, imgsz, batch_size, stride, opt, hyp=None, augment=False, cache=False, pad=0.0, rect=False,
rank=-1, world_size=1, workers=8, image_weights=False, quad=False, prefix=''):```
path: 数据集的路径。
imgsz: 输入图像的尺寸。
batch_size: 每个批次的图像数量。
stride: 模型中特征提取部分的步长。
opt: 一组包含不同训练选项的参数。
hyp: 训练时使用的超参数。
augment: 是否对图像进行增强。
cache: 是否缓存图像以加快训练速度。
pad: 在图像周围添加的填充量,用于保持比例。
rect: 是否使用矩形训练,这可以在某些情况下提高效率。
rank: 用于分布式训练,表示当前进程的排名。
world_size: 分布式训练中的总进程数。
workers: 加载数据时使用的进程数。
image_weights: 是否根据图像的难易程度调整其在批次中的采样概率。
quad: 是否使用四分法对图像进行加载,这是一种特定的加载方式,用于加速。
prefix: 在加载数据时可能会用到的前缀,用于打印日志信息。
```py
with torch_distributed_zero_first(rank):
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
augment=augment, # augment images
hyp=hyp, # augmentation hyperparameters
rect=rect, # rectangular training
cache_images=cache,
single_cls=opt.single_cls,
stride=int(stride),
pad=pad,
image_weights=image_weights,
prefix=prefix)
这一部分代码创建了一个数据集实例。它使用了 LoadImagesAndLabels 类,该类负责加载图像和标签,同时根据指定的参数执行数据预处理和增强。使用 torch_distributed_zero_first 是为了确保在分布式训练中,只有第一个进程先处理数据集,其余进程等待,以便所有进程共享相同的数据状态。
create_dataloader函数在test文件和train文件中被调用,在train文件的190行和200行。阅读这附近的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
def train(hyp, opt, device, tb_writer=None):
....
....
# Image sizes 图像尺寸
gs = max(int(model.stride.max()), 32) # 网格大小(最大步长)
nl = model.model[-1].nl # 检测层的数量(用于缩放hyp['obj'])
imgsz, imgsz_test = [check_img_size(x, gs) for x in opt.img_size] # 分别为训练和测试图像大小,验证imgsz是gs的倍数
# DP mode\\数据并行模式
#如果使用CUDA,且没有进行分布式训练(rank == -1),并且有多于一个的CUDA设备可用,
# 那么使用DataParallel来进行数据并行处理,以加速训练。
if cuda and rank == -1 and torch.cuda.device_count() > 1:
model = torch.nn.DataParallel(model)
# SyncBatchNorm\\同步批量归一化
#在使用CUDA且进行分布式训练时,如果启用了同步批量归一化(sync_bn),
# 则对模型应用此设置,以确保批量归一化在多个设备上同步进行。
if opt.sync_bn and cuda and rank != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
logger.info('Using SyncBatchNorm()')
# Trainloader\\训练数据加载器
#创建训练数据加载器,这里根据提供的参数加载训练数据集。
# 包括数据增强、是否缓存图像、是否使用矩形训练等选项。
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,
hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect, rank=rank,
world_size=opt.world_size, workers=opt.workers,
image_weights=opt.image_weights, quad=opt.quad, prefix=colorstr('train: '))
mlc = np.concatenate(dataset.labels, 0)[:, 0].max() # max label class
nb = len(dataloader) # number of batches
assert mlc < nc, 'Label class %g exceeds nc=%g in %s. Possible class labels are 0-%g' % (mlc, nc, opt.data, nc - 1)
# Process 0\\测试数据加载器
#在非分布式训练或主节点上,创建测试数据加载器。测试加载器的批次大小是训练的两倍,
# 可能是因为测试时不需要进行反向传播,因此可以加载更多的数据。
if rank in [-1, 0]:
testloader = create_dataloader(test_path, imgsz_test, batch_size * 2, gs, opt, # testloader
hyp=hyp, cache=opt.cache_images and not opt.notest, rect=True, rank=-1,
world_size=opt.world_size, workers=opt.workers,
pad=0.5, prefix=colorstr('val: '))[0]
if not opt.resume:
labels = np.concatenate(dataset.labels, 0)
c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots:
plot_labels(labels, names, save_dir, loggers)
if tb_writer:
tb_writer.add_histogram('classes', c, 0)
# Anchors
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
model.half().float() # pre-reduce anchor precision
# DDP mode\\分布式数据并行(DDP)模式
#在使用CUDA且进行分布式训练时,设置模型为分布式数据并行模式。find_unused_parameters参数
# 用于处理模型中可能未使用的参数,特别是当模型包含如MultiheadAttention这样的复杂层时。
if cuda and rank != -1:
model = DDP(model, device_ids=[opt.local_rank], output_device=opt.local_rank,
# nn.MultiheadAttention incompatibility with DDP https://github.com/pytorch/pytorch/issues/26698
find_unused_parameters=any(isinstance(layer, nn.MultiheadAttention) for layer in model.modules()))
...
...
问题:能够口头话的解释一下训练时,数据加载的部分吗?我希望将加载的数据集进行亮度对比度调整,是不是得修改这个函数create_dataloader(train_path, imgsz, batch_size, gs, opt, hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect, rank=rank, world_size=opt.world_size, workers=opt.workers, image_weights=opt.image_weights, quad=opt.quad, prefix=colorstr(‘train: ‘))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
当训练神经网络时,数据加载是一个重要的步骤,它涉及从存储设备中加载训练数据并准备送入模型进行训练。在上述代码中,create_dataloader函数负责创建数据加载器,并根据参数配置加载相应的数据集。下面是对其功能的口头解释:
路径和参数:create_dataloader函数接受多个参数,包括训练数据的路径(train_path)、图像尺寸(imgsz)、批次大小(batch_size)、步长(gs)、优化器选项(opt)、超参数(hyp)等。这些参数用于配置数据加载器的行为和处理。
数据增强:augment=True参数表示进行数据增强,这在训练神经网络时通常是必要的。数据增强技术可以通过对原始图像进行变换和扭曲来增加训练数据的多样性,从而提高模型的泛化能力。
缓存:cache=opt.cache_images参数表示是否缓存图像数据。缓存图像数据可以加快训练速度,特别是对于大型数据集。但需要注意的是,缓存可能会占用大量内存,因此在内存受限的情况下需要谨慎使用。
矩形训练:rect=opt.rect参数表示是否使用矩形训练。矩形训练可以在不同尺寸的图像上进行训练,而不会将它们调整为相同的尺寸。这对于一些场景下的目标检测任务可能是有益的。
分布式训练:rank=rank, world_size=opt.world_size参数用于分布式训练时确定当前进程的排名和总进程数量。这是为了在分布式环境中正确地分配数据和模型参数。
数据权重:image_weights=opt.image_weights参数表示是否使用数据权重。在某些情况下,数据集中的样本可能具有不同的重要性,使用数据权重可以平衡样本的贡献,从而提高模型的性能。
其他参数:还有一些其他参数,如quad、prefix等,用于进一步配置数据加载器的行为。
如果你想要在数据加载过程中进行亮度和对比度的调整,你需要修改create_dataloader函数的实现。你可以在其中添加图像增强的代码,例如使用OpenCV或PIL库来调整图像的亮度和对比度。通过这种方式,你可以在数据加载过程中实现你所需的图像预处理操作。
尝试改变图像4度
1.尝试和清楚将图片的4度修改成什么样子,需要的相关的代码 2.将代码放入项目中
色彩抖动代码调整 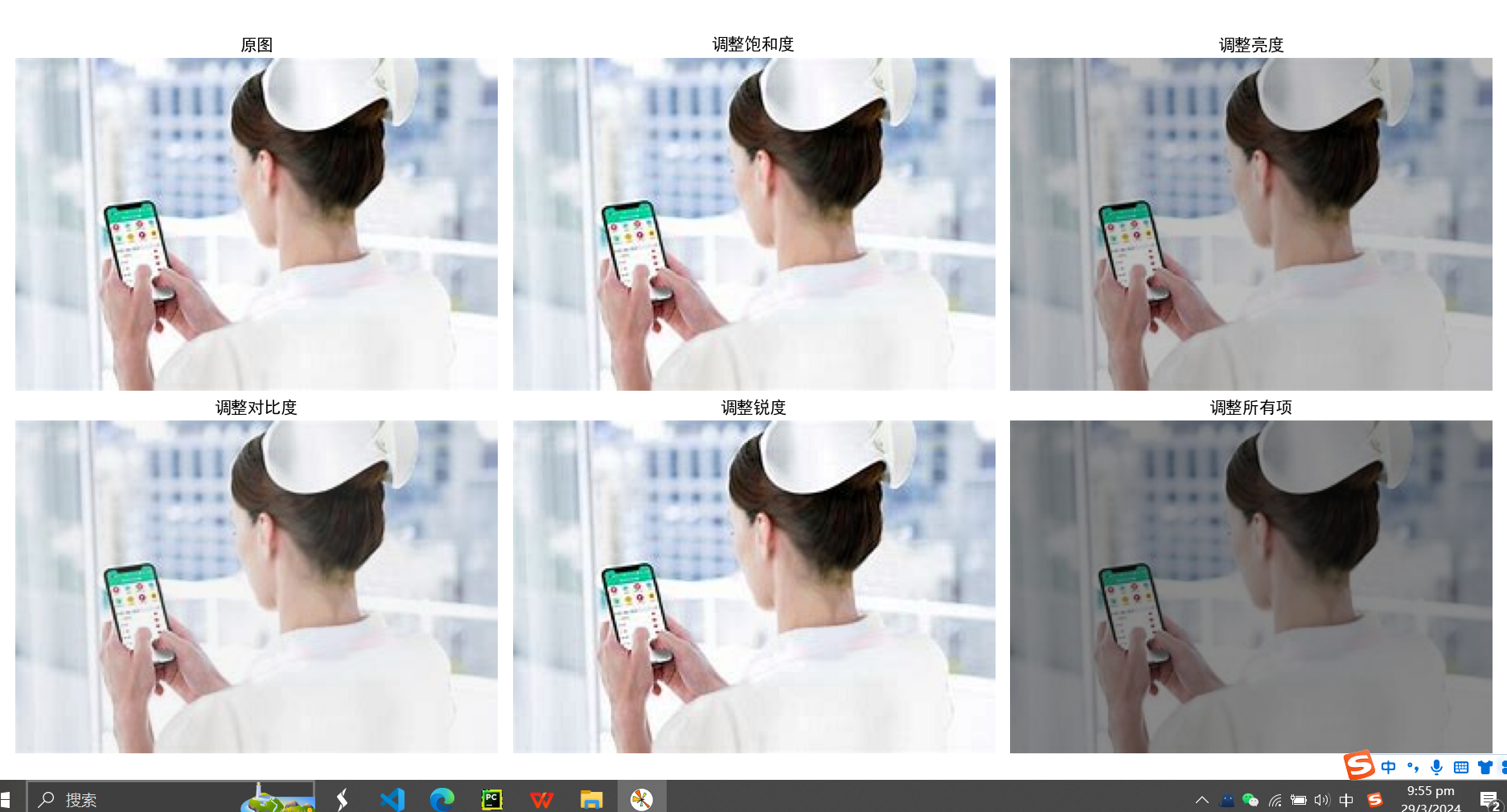
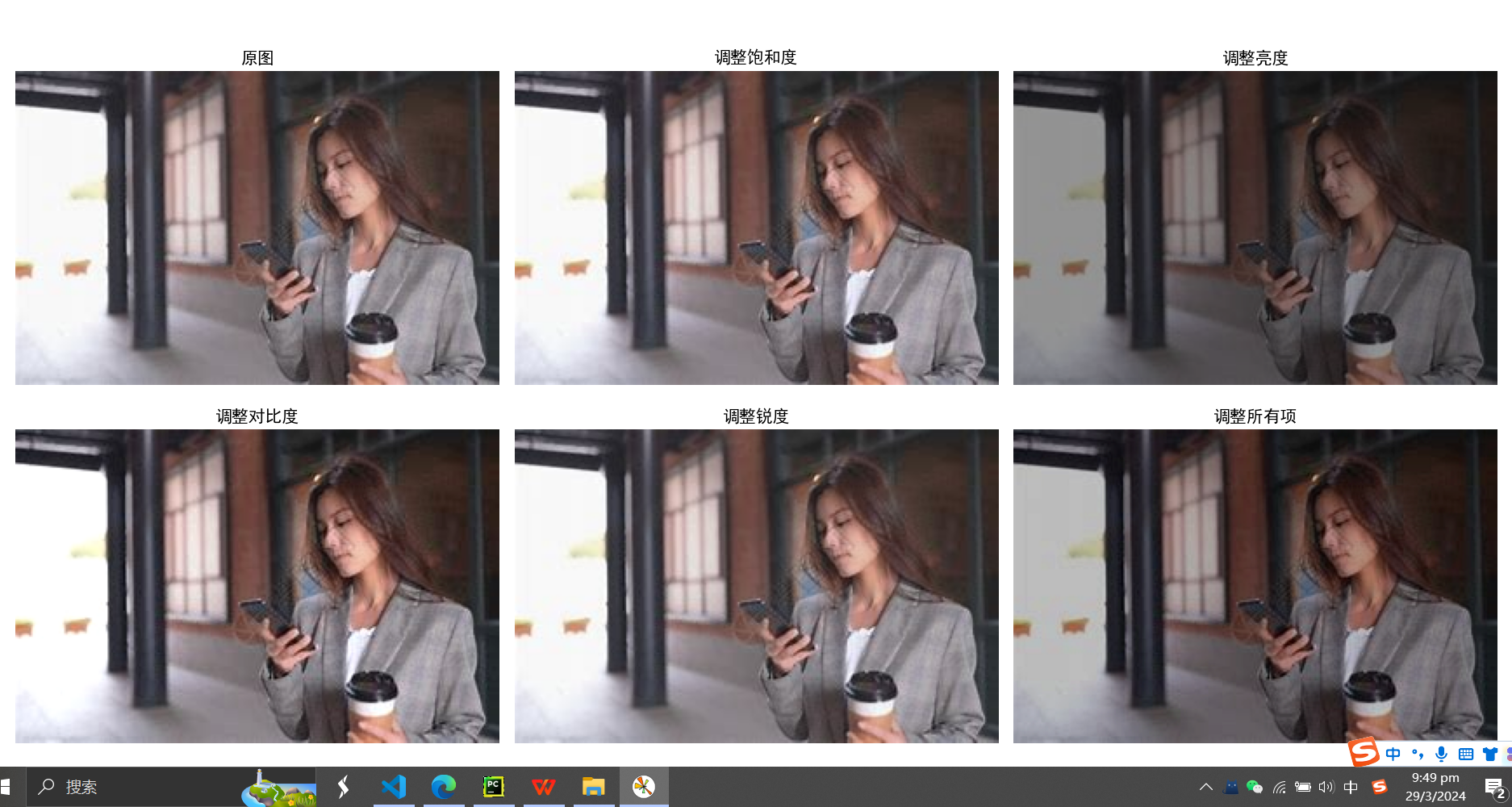
色彩增强调整



彩色图像直方图均衡化 

目测排名:色彩增强》彩色图像直方图均衡化》色彩抖动代码调整
色彩增强:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
if self.augment:
# Augment imagespace
if not mosaic:
img, labels = random_perspective(img, labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])
# Augment colorspace
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
img = zmIceColor(img, ratio=4, radius=3) / 255.0 * 255
# Apply cutouts
# if random.random() < 0.9:
# labels = cutout(img, labels)
nL = len(labels) # number of labels
if nL:
labels[:, 1:5] = xyxy2xywh(labels[:, 1:5]) # convert xyxy to xywh
labels[:, [2, 4]] /= img.shape[0] # normalized height 0-1
labels[:, [1, 3]] /= img.shape[1] # normalized width 0-1
# 如果 self.augment 为真,执行以下操作:
# 根据预设的概率决定是否对图像进行上下翻转。
# 根据预设的概率决定是否对图像进行左右翻转。
if self.augment:
# flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img)
if nL:
labels[:, 2] = 1 - labels[:, 2]
# flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img)
if nL:
labels[:, 1] = 1 - labels[:, 1]
labels_out = torch.zeros((nL, 6))
if nL:
labels_out[:, 1:] = torch.from_numpy(labels)
# Convert,将标签数据转换成 PyTorch 张量形式。
# 将图像转换成 PyTorch 张量形式,并进行通道顺序转换和维度变换
# 返回图像、标签、图像文件路径和形状信息。
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
return torch.from_numpy(img), labels_out, self.img_files[index], shapes
....
#自己添加的函数-----------------------------------------------------
def stretchImage(data, s=0.005, bins=2000): # 线性拉伸,去掉最大最小0.5%的像素值,然后线性拉伸至[0,1]
ht = np.histogram(data, bins);
d = np.cumsum(ht[0]) / float(data.size)
lmin = 0;
lmax = bins - 1
while lmin < bins:
if d[lmin] >= s:
break
lmin += 1
while lmax >= 0:
if d[lmax] <= 1 - s:
break
lmax -= 1
return np.clip((data - ht[1][lmin]) / (ht[1][lmax] - ht[1][lmin]), 0, 1)
def getPara(radius=5): # 根据半径计算权重参数矩阵
global g_para
m = g_para.get(radius, None)
if m is not None:
return m
size = radius * 2 + 1
m = np.zeros((size, size))
for h in range(-radius, radius + 1):
for w in range(-radius, radius + 1):
if h == 0 and w == 0:
continue
m[radius + h, radius + w] = 1.0 / math.sqrt(h ** 2 + w ** 2)
m /= m.sum()
g_para[radius] = m
return m
def zmIce(I, ratio=4, radius=300): # 常规的ACE实现
para = getPara(radius)
height, width = I.shape
zh, zw = [0] * radius + [x for x in range(height)] + [height - 1] * radius, [0] * radius + [x for x in range(width)] + [width - 1] * radius
Z = I[np.ix_(zh, zw)]
res = np.zeros(I.shape)
for h in range(radius * 2 + 1):
for w in range(radius * 2 + 1):
if para[h][w] == 0:
continue
res += (para[h][w] * np.clip((I - Z[h:h + height, w:w + width]) * ratio, -1, 1))
return res
def zmIceFast(I, ratio, radius): # 单通道ACE快速增强实现
height, width = I.shape[:2]
if min(height, width) <= 2:
return np.zeros(I.shape) + 0.5
Rs = cv2.resize(I, ((width + 1) // 2, (height + 1) // 2))
Rf = zmIceFast(Rs, ratio, radius) # 递归调用
Rf = cv2.resize(Rf, (width, height))
Rs = cv2.resize(Rs, (width, height))
return Rf + zmIce(I, ratio, radius) - zmIce(Rs, ratio, radius)
def zmIceColor(I, ratio=4, radius=3): # rgb三通道分别增强,ratio是对比度增强因子,radius是卷积模板半径
res = np.zeros(I.shape)
for k in range(3):
res[:, :, k] = stretchImage(zmIceFast(I[:, :, k], ratio, radius))
return res
加入相应的代码后,训练时间翻了3倍,一开始pgu训练时间为12s左右的,但总是忽的卡顿一下,像是在切换,切成cpu,然后又gpu,再cpu的感觉,就很不连贯,结果时间翻了3倍。或许可以新开一个py处理文件,将要训练的文件处理了先,然后在送到项目那里进行训练,而不是合二为一,这样子比较省时间。
部署测试结果:
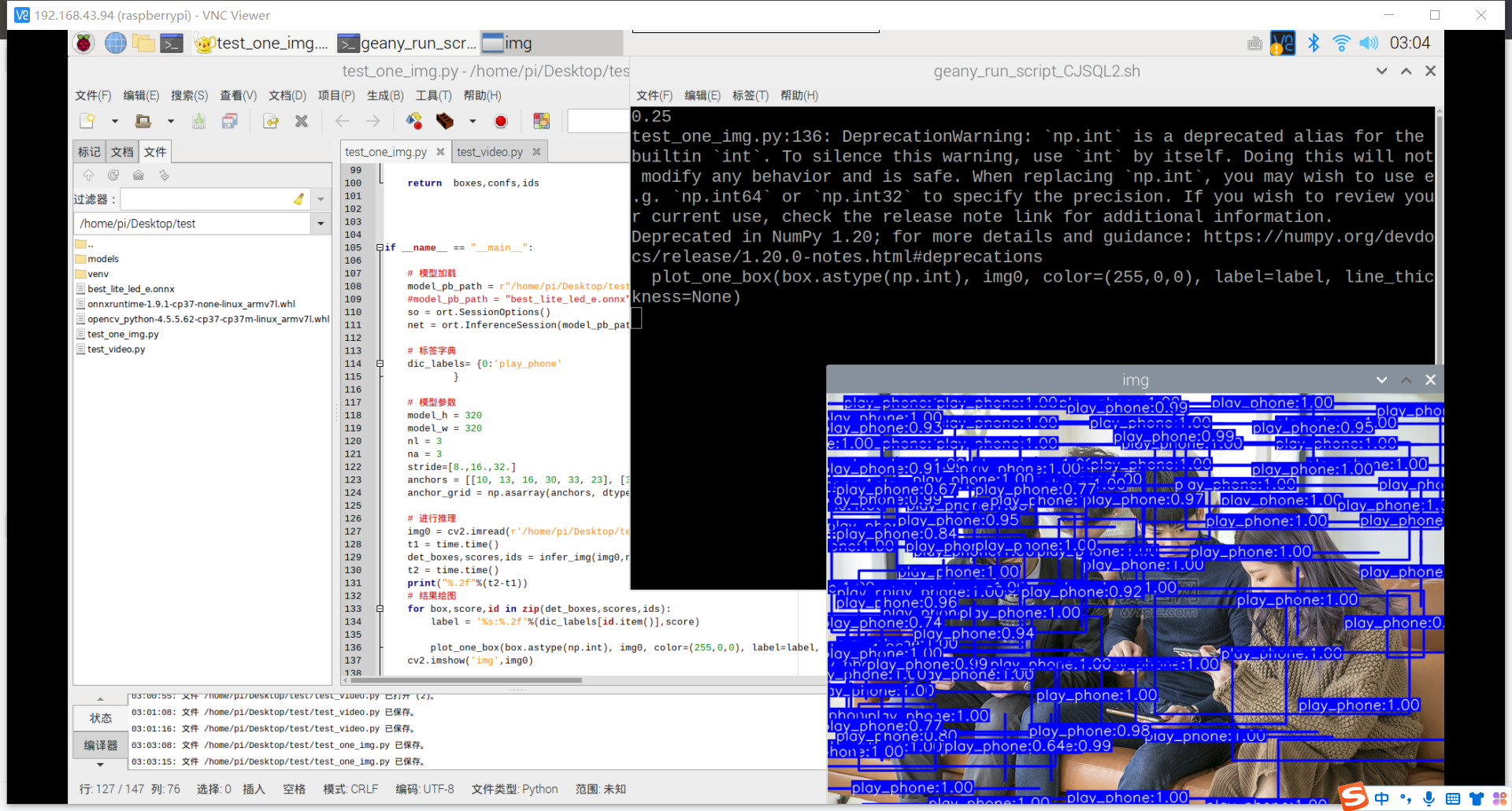
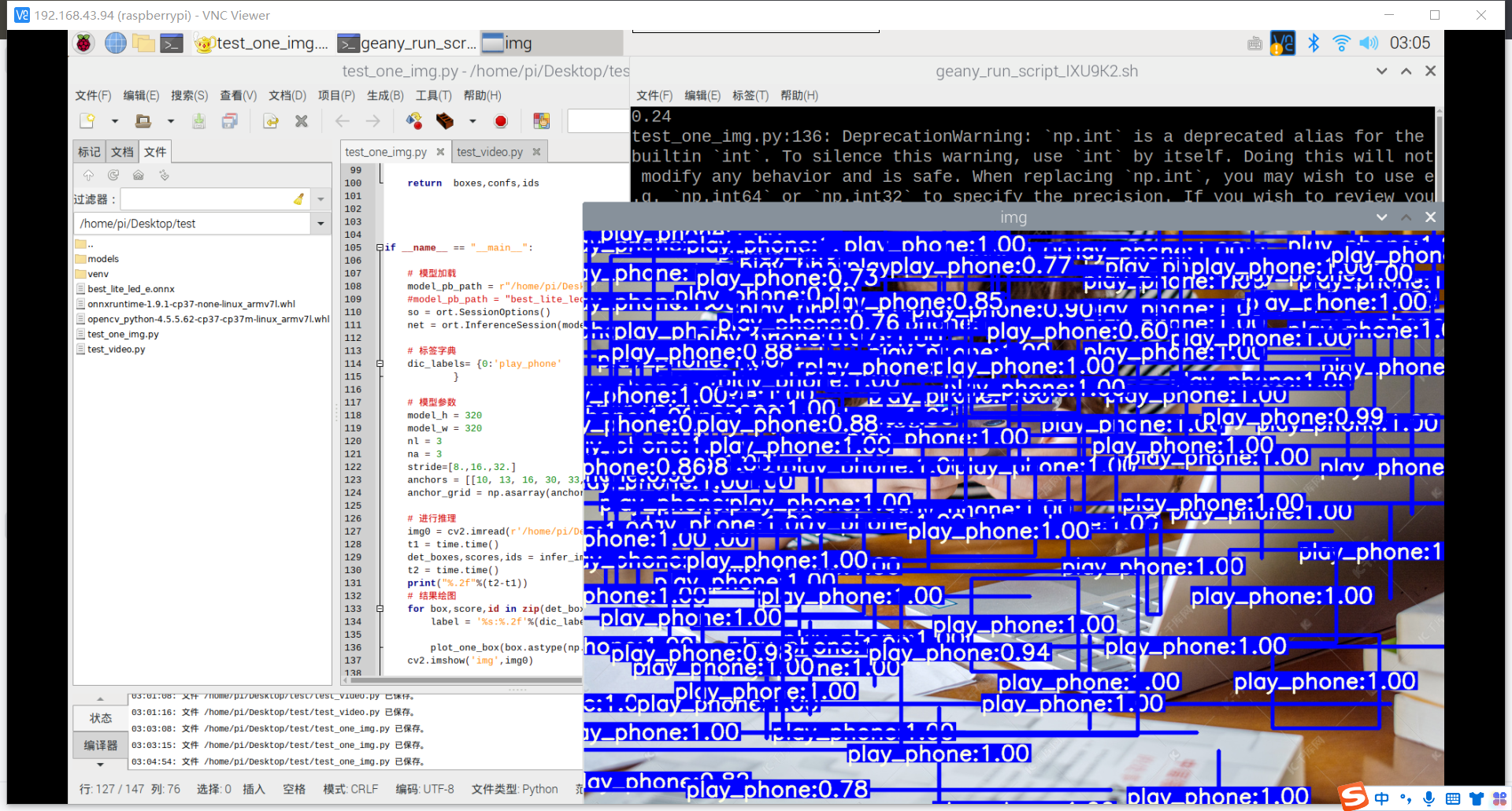
妥妥的失败了,但好歹能用。下次尝试将训练步骤分为2部分进行,继续使用色彩增强的方法,再进行一次。
分成两步后,速度确实恢复预期那么快了。大概从3.7h变为0.9h
部署:
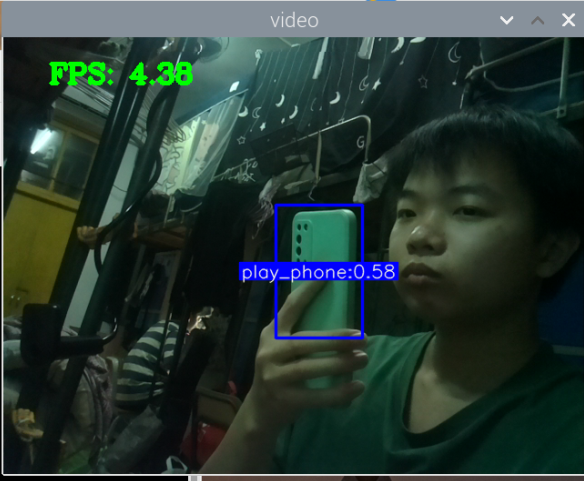
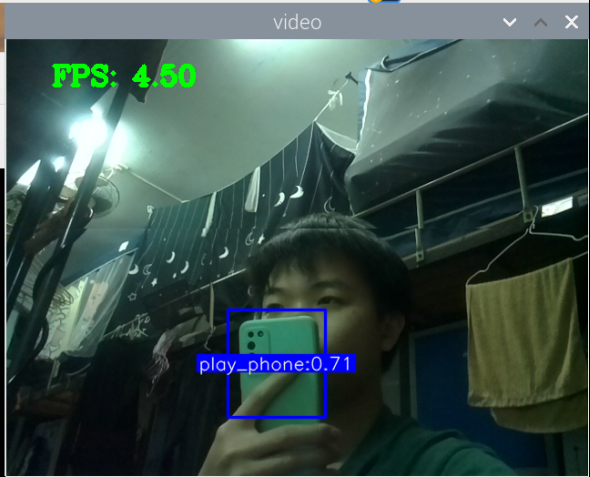







结果:精度有了很大的提升,针对一些标准的图片,可以很好的识别,针对实时的视频检测,从完全无法识别,变为了偶尔可以识别,这里可以通过增加数据集来提升精度。可以打分为1.3(1为仅仅只能识别标准图片,难以识别显示情况图片)
彩色图像直方图均衡化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import os
import cv2
import numpy as np
def hisEqulColor(img):
ycrcb = cv2.cvtColor(img, cv2.COLOR_BGR2YCR_CB)
channels = cv2.split(ycrcb)
cv2.equalizeHist(channels[0], channels[0])
ycrcb = cv2.merge(channels)
cv2.cvtColor(ycrcb, cv2.COLOR_YCR_CB2BGR, img)
return img
def decrease_brightness(img, factor):
ycrcb = cv2.cvtColor(img, cv2.COLOR_BGR2YCR_CB)
channels = list(cv2.split(ycrcb))
channels[0] = np.clip(channels[0] * factor, 0, 255).astype(np.uint8)
ycrcb = cv2.merge(channels)
cv2.cvtColor(ycrcb, cv2.COLOR_YCR_CB2BGR, img)
return img
def process_image(image_path, brightness_factor):
im = cv2.imread(image_path)
eq_with_decreased_brightness = decrease_brightness(hisEqulColor(im), brightness_factor)
cv2.imwrite(image_path, eq_with_decreased_brightness)
# 获取指定路径下的所有图片文件
image_folder_path = r'C:\Users\123\Desktop\yolo\data_collect\valid\images'
image_files = [f for f in os.listdir(image_folder_path) if os.path.isfile(os.path.join(image_folder_path, f))]
# 亮度降低因子
brightness_factor = 0.8 # 调整这个因子以控制亮度的降低程度
# 遍历每张图片进行处理
for image_file in image_files:
image_path = os.path.join(image_folder_path, image_file)
process_image(image_path, brightness_factor)
print("Image processing completed.")
完成图片的预处理,然后训练模型,耗时0.9h
部署: 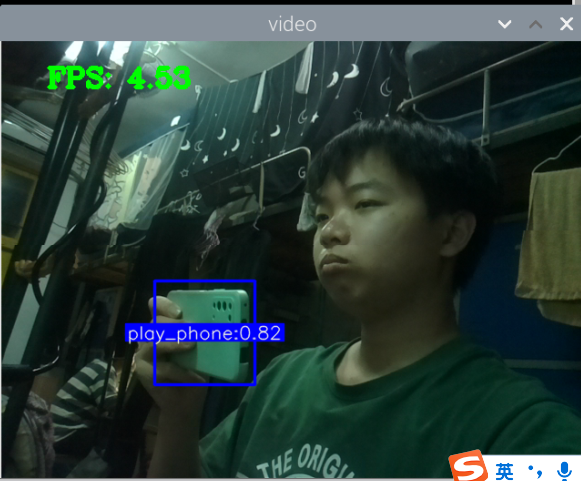
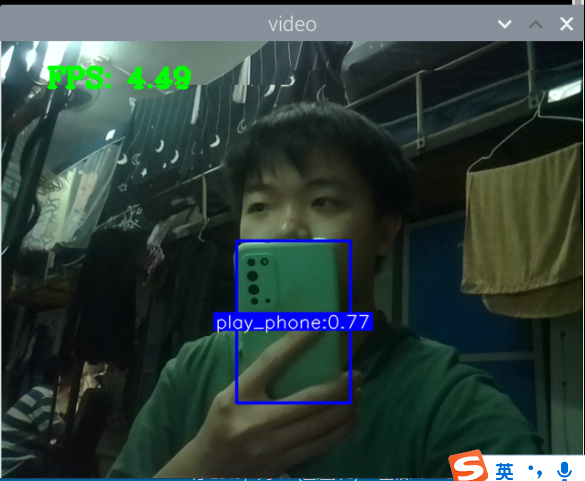
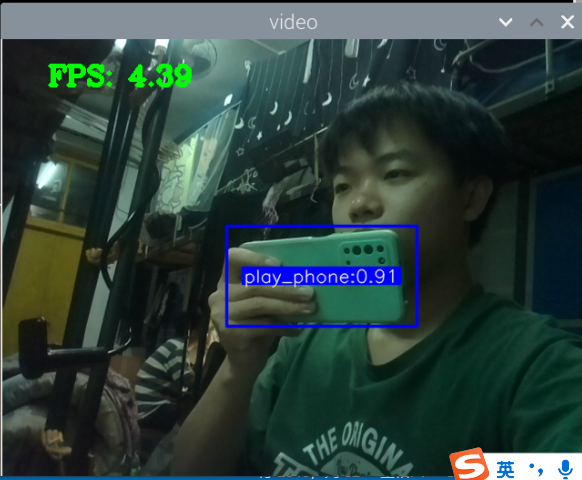
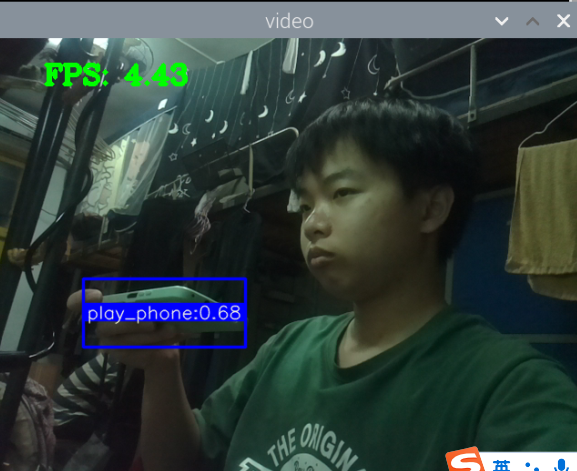
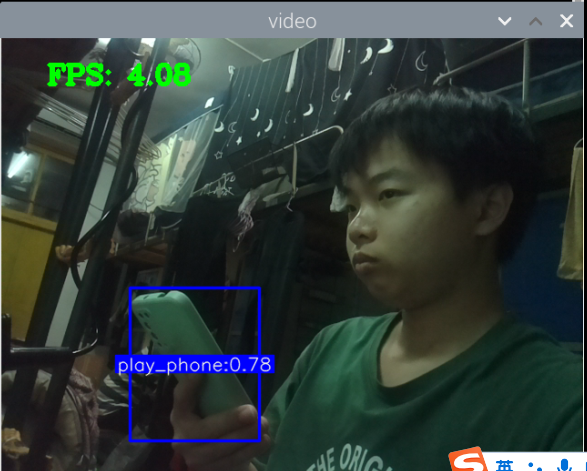






结果:目测标准图片的准确度有所下降,而实时的视频检测比色彩增强的稍微精准一点。综合评分:1.3
色彩抖动:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import os
import numpy as np
from PIL import Image, ImageEnhance
import cv2
import random
def randomColor(image, saturation=1, brightness=1, contrast=1, sharpness=1):
if random.random() < saturation:
random_factor = np.random.uniform(0.8, 1.2)
image = ImageEnhance.Color(image).enhance(random_factor)
if random.random() < brightness:
random_factor = np.random.uniform(0.5, 0.8)
image = ImageEnhance.Brightness(image).enhance(random_factor)
if random.random() < contrast:
random_factor = np.random.uniform(0.8, 1.2)
image = ImageEnhance.Contrast(image).enhance(random_factor)
if random.random() < sharpness:
random_factor = np.random.uniform(0.8, 1.2)
image = ImageEnhance.Sharpness(image).enhance(random_factor)
return image
def process_and_save_image(image_path):
img = cv2.imread(image_path)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 转换颜色空间为RGB
pil_image = Image.fromarray(img_rgb)
processed_image = randomColor(pil_image)
processed_image_rgb = np.array(processed_image)
cv2_img = cv2.cvtColor(processed_image_rgb, cv2.COLOR_RGB2BGR)
cv2.imwrite(image_path, cv2_img)
image_folder_path = r'C:\Users\123\Desktop\yolo\data_collect\valid\images'
image_files = [f for f in os.listdir(image_folder_path) if os.path.isfile(os.path.join(image_folder_path, f))]
for image_file in image_files:
image_path = os.path.join(image_folder_path, image_file)
process_and_save_image(image_path)
print("All images have been processed and saved.")
训练部署,结果: 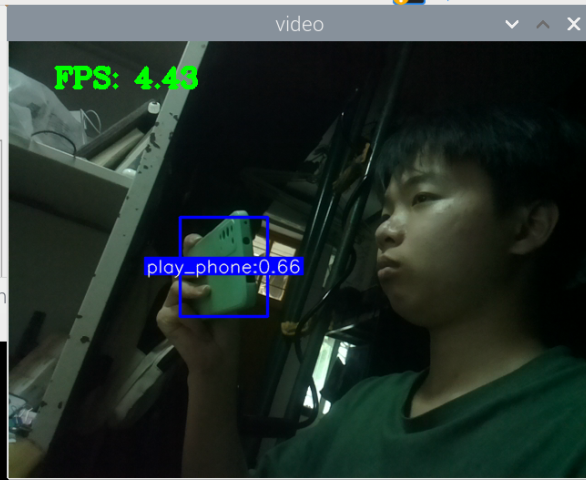
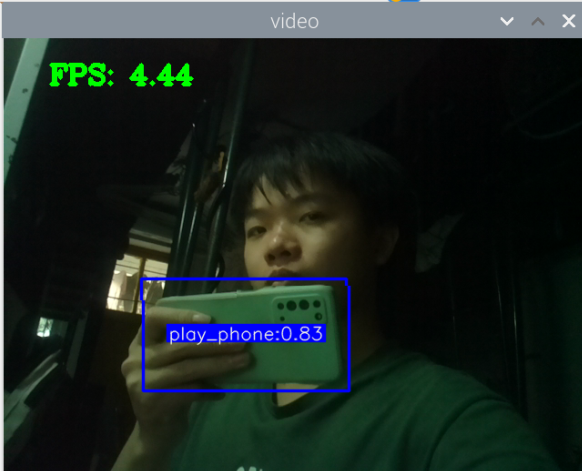


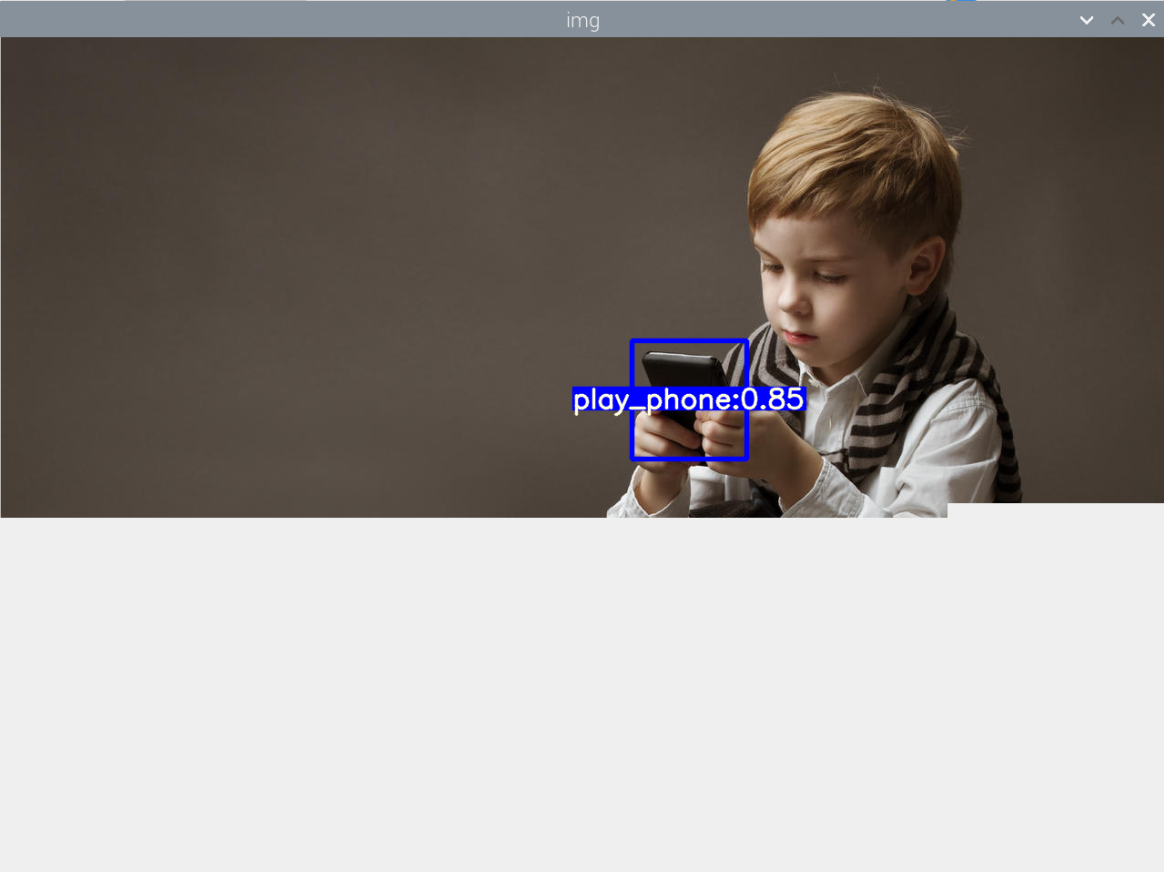
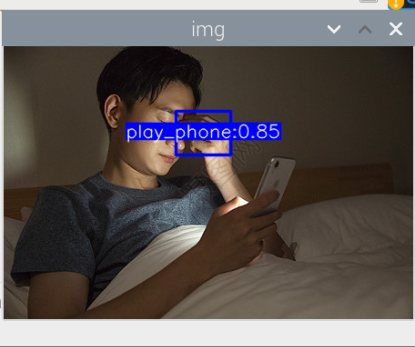

结果:标准图片识别较差,实时视频识别差了一点,评分12.
目测第二个和第一个都不错,但具体的话还需要进行大模型的训练,再次之前,还得学习一下如何判断一个模型是否优秀,接着将以此为一句对数据增强进行进一步的改进
数据增强3
https://blog.csdn.net/flyfish1986/article/details/120704968 https://blog.csdn.net/qq_39696563/article/details/125651010 https://zhuanlan.zhihu.com/p/677564907
前言:
你的模型架构足够好了。总而言之,不要试图和一屋子的博士比聪明。相反,在尝试改进模型之前,请确保数据的质量是一流的。

其实不论模型好与不好,想要更进一步,就应该聚焦于怎么做,而不是为什么先,聚焦于数据集,影响因素,而非模型。所以可以先不管这些性能的评估指标,先看看怎么提高先。分为:数据集方面和训练设置方面
数据集方面:
每个类的图像:每个类最好 >=1500 张图像 (图像个数)、每个类的实例:推荐每个类≥10000个实例(标记对象)(每个类里面的东西的个数)
图像的多样性:必须能代表所部署的环境。对于现实世界的用例,我们推荐不同时间、不同季节、不同天气、不同光照、不同角度、不同来源(在线抓取、本地收集、不同相机)的图像
标注的一致性:不能遗漏任何一个实例的标注
标注的精度:边框的紧密性、背景图像占总图像数量的0-10%(加入一些只包含街道、建筑物而没有任何交通标志的图像)
标注遮挡物:不能只标注图像中完整的目标,被遮挡的目标,只要人眼能看清是啥的都应该被标注,并且矩形框只需要包含看得见的部分即可。
标注小目标:只要人眼能分清是啥的小目标
不框规则:图像模糊不清的不框,太暗和曝光过度的不框,不符合项目特殊规则的不框。
边界检查:确保框坐标不在图像边界上,防止载入数据或者数据扩展过程出现越界报错。
宽高比 极端不是好样本。


分析;按照这些规则来看,上网上找的手机的数据集还是很合适的,几乎满足了所有规则,还将人物切分出来,去除多余的环境影响。或许标注都是应该如此
我应该先尝试着学习正确使用这个数据集,再然后再添加一些合适的数据集下去,这个网上找的玩手机的大多都是站着玩手机的情况,有些许是坐着的,学会训练并且比较好的时候,再加入一些躺着的,坐着的数据集。
下载得到的数据集文件里又三大文件:phone、recognize_phonedata、test_images_a
其中recognize_phonedata有两个文件,0_recognize_phone和1_recognize_nophone,其中0_recognize_phone里面包含了8390张手握手机、被截取出来的图片。而1_recognize_nophone里包含了8293张部分区域、没有包含手机的图片。
test_images_a文件里面包含了4089张测试图片,有的有手机,有的没手机。
最后一个文件夹phone里包含:0_phone和1_no_phone,0_phone包含了train和labels,后者就只有没有手机的图片
问题:我记得yolov5模型的训练,是要有train和valid两个文件夹的,这两个里面都有images和labels,train放的是训练集,valid放的是验证集,那测试集图片应该放在项日的哪里呢,是不是项日在训练出模型后机会自动测试验证一下验证集的图片。
1
2
3
4
5
6
7
8
9
10
11
12
在YOLOv5的训练流程中,通常会有两个主要的文件夹用于训练和验证(即valid)过程,分别是train和valid。每个文件夹里都应该包含两个子文件夹:images和labels。images文件夹存放图片文件,而labels文件夹存放对应的标注文件。
训练集(train):用于训练模型,模型会在这些数据上学习如何识别目标。
验证集(valid):用于验证训练过程中模型的性能,帮助调整模型参数,避免模型过拟合。
测试集的使用:对于测试集,其用途主要是在模型训练完成后评估模型在未见过数据上的性能。在YOLOv5的官方实践中,并没有指定一个固定的文件夹结构来存放测试集,因为测试通常是独立于训练/验证过程进行的。你可以将测试集的图片放在任意位置,只要在进行测试时指明路径即可。
如果你想在测试集上评估模型,需要在训练完成后手动进行。这可以通过运行detect.py脚本并指定你的模型权重和测试图片的路径来完成。例如:
python detect.py --weights runs/train/exp/weights/best.pt --img 640 --conf 0.25 --source /path/to/your/test/images
在这里,--weights指定了模型权重文件,--img指定了输入图片的大小,--conf指定了置信度阈值,而--source则指定了测试图片的路径。
问题:如果希望在训练的时候加上一些背景图像,也就是没有玩手机目标的背景图像,我应该加载哪里,是在train的images里面吗,若是在这里,那它对应的labels怎么办
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
如果你希望在训练过程中加入一些没有目标(本例中是没有玩手机的人)的背景图像,这是一个很好的想法,因为它可以帮助模型学习区分背景和目标,从而提高模型在复杂环境下的鲁棒性和准确性。
如何加入背景图像
放置背景图像:确实,你应该将这些背景图像放在train文件夹的images子文件夹中,就像你对待其他有目标的训练图像一样。
处理对应的标签:对于这些背景图像,它们的“标签”文件应该存在于train文件夹的labels子文件夹中,但与有目标的图像标签不同,这些背景图像的标签文件应该是空的。这意味着,对于每个背景图像,都有一个对应的标签文件,但该文件不包含任何目标的标记信息。
示例
假设你有一个背景图像命名为background_001.jpg,你应该:
将background_001.jpg放入train/images文件夹。
创建一个对应的空标签文件background_001.txt,放入train/labels文件夹。
注意事项
平衡数据:在加入背景图像时,要注意数据的平衡性。加入太多背景图像可能会导致模型对实际目标的检测能力下降,因为模型可能会“学习”到目标很少出现的偏见。合理地平衡有目标的图像与无目标的背景图像之间的比例是很重要的。
多样性:确保背景图像的多样性,覆盖模型预期操作环境的各种情况,这有助于提高模型的泛化能力。
通过这种方式加入背景图像并合理调整训练集的组成,可以有效地提升模型对于复杂背景下目标的识别能力,进而提高整体的检测性能。
将收集的1000张图片(彩色图像直方图均衡化)和标准的8700张还有99张背景图片拿去训练, md,不知道怎么回事,突然间就关机了,就像上次那样,突然间就停机了,都已经训练了7个小时了。
问题:我跑9000张图片数据集的yolov5-lite模型的时候,突然间,电脑就像是熄火停机了,然后我按回车键发现电脑正在重新开机,这害我模型训练到一半就停了。上一次我也遇到过,就跑着跑着,程序就没了,现在想来应该也是重新开机了。这是什么原因
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
这种情况可能是由于电脑出现了系统崩溃或者硬件故障导致的。造成电脑重新启动的原因可能有很多,包括但不限于:
过热: 长时间运行大型计算任务,特别是涉及大量数据处理的深度学习任务,可能导致电脑过热而触发了保护机制,导致自动关机或重启。
电源问题: 电源供应不稳定或者电源适配器故障可能导致电脑突然关机或重新启动。
内存不足: 如果你的电脑内存不足以处理大规模的数据集,运行深度学习模型时可能会导致系统崩溃或重新启动。
软件问题: 某些软件或驱动程序的冲突或错误可能导致系统崩溃。
硬件故障: 电脑的硬件部件出现故障,比如CPU、内存、硬盘等,可能会导致系统不稳定或崩溃。
针对这个问题,你可以尝试以下方法来解决:
检查硬件: 确保你的电脑硬件状态良好,包括内存、CPU、散热器等。清理电脑内部灰尘,确保良好的散热,可以减少过热导致的问题。
监控系统状态: 使用系统监控工具来监测电脑的温度、内存使用情况等,确保在运行大型任务时不会超过系统承受范围。
更新驱动程序和软件: 确保你的操作系统、驱动程序和相关软件都是最新版本,以减少可能的软件冲突或错误。
降低负载: 如果可能的话,尝试减少运行其他任务的负载,专注于模型训练任务,以减少系统崩溃的可能性。
检查电源: 如果怀疑是电源问题导致的系统重启,可以尝试更换电源适配器或者检查电源供应是否稳定。
还好之前读了一下代码,知道有恢复训练的可能,不然又得重来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
在PyCharm中运行 `train.py` 脚本并设置 `--resume` 参数的步骤如下:
1. 打开PyCharm,创建一个新的Python项目或打开现有的项目。
2. 找到 `train.py` 文件,右击并选择 `Run 'train.py'`。
3. 在运行配置窗口中,点击 `Edit Configurations` 按钮。
4. 在配置窗口中,找到 `train.py` 的运行配置,并在 `Parameters` 字段中添加 `--resume` 参数:
```
--resume
```
5. 点击 `OK` 保存配置。
6. 现在,当你再次运行 `train.py` 时,它将使用 `--resume` 参数继续之前的训练。
如果你不确定检查点文件的具体路径,你可以不填写任何值,只添加 `--resume`。这样脚本会尝试从最近的检查点文件恢复训练。
如果你知道检查点文件的路径,可以在 `--resume` 后面添加文件路径,例如:
```
--resume path/to/checkpoint.pth
```
确保在PyCharm的运行配置窗口中正确设置了 `--resume` 参数,然后运行 `train.py` 即可继续之前的训练。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
Resuming training from .\runs\train\exp\weights\last.pt
YOLOv5 2024-2-2 torch 2.1.0+cu121 CUDA:0 (NVIDIA GeForce MX330, 2047.875MB)
Namespace(weights='.\\runs\\train\\exp\\weights\\last.pt', cfg='', data='data/mydata.yaml', hyp='data/hyp.scratch.yaml', epochs=300, batch_size=16, img_size=[320, 320], rect=False, resume=True, nosave=False, notest=False, noautoanchor=False, evolve=False, bucket='', cache_images=False, image_weights=False, device='0', multi_scale=False, single_cls=False, adam=False, sync_bn=False, local_rank=-1, workers=8, project='runs/train', entity=None, name='exp', exist_ok=False, quad=False, linear_lr=False, label_smoothing=0.0, upload_dataset=False, bbox_interval=-1, save_period=-1, artifact_alias='latest', world_size=1, global_rank=-1, save_dir='runs\\train\\exp', total_batch_size=16)
tensorboard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
hyperparameters: lr0=0.001, lrf=0.2, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=0.2, mixup=0.0
wandb: Install Weights & Biases for YOLOv5 logging with 'pip install wandb' (recommended)
正在从 .\runs\train\exp\weights\last.pt 恢复训练
YOLOv5 2024-2-2 torch 2.1.0+cu121 CUDA:0 (NVIDIA GeForce MX330, 2047.875MB)
参数设置如下:
- 权重文件路径: '.\\runs\\train\\exp\\weights\\last.pt'
- 模型配置文件路径: ''
- 数据集配置文件路径: 'data/mydata.yaml'
- 超参数文件路径: 'data/hyp.scratch.yaml'
- 总训练轮数: 300
- 批量大小: 16
- 图像尺寸: [320, 320]
- 是否使用矩形训练: 否
- 是否恢复之前的训练: 是
- 是否仅保存最终检查点: 否
- 是否仅在最后一个 epoch 进行测试: 否
- 是否禁用自动锚框检查: 否
- 是否进行超参数进化: 否
- 云存储桶路径: ''
- 是否缓存图像以加快训练速度: 否
- 是否使用图像权重: 否
- 设备选择: '0' (指定为 CUDA 设备 0)
- 是否启用多尺度训练: 否
- 是否将多类别数据视为单类别数据进行训练: 否
- 是否使用 Adam 优化器: 否
- 是否使用同步批量归一化: 否
- 当前本地进程排名: -1
- 数据加载器最大工作进程数: 8
- 项目名称: 'runs/train'
- 实体名称: None
- 训练名称: 'exp'
- 是否允许存在相同项目名称: 否
- 是否使用四进程数据加载器: 否
- 是否使用线性学习率调整: 否
- 标签平滑度: 0.0
- 是否上传数据集: 否
- 边界框图像记录间隔: -1
- 模型保存周期: -1
- 数据集工件别名: 'latest'
- 分布式训练进程数: 1
- 全局排名: -1
- 检查点保存目录: 'runs\\train\\exp'
初始超参数设置如下:
- 初始学习率: 0.001
- 最终 OneCycleLR 学习率: 0.2
- 动量: 0.937
- 权重衰减: 0.0005
- 渐变增强的训练轮数: 3.0
- 渐变增强的动量: 0.8
- 渐变增强的偏置学习率: 0.1
- 框损失增益: 0.05
- 分类损失增益: 0.5
- 分类 BCELoss 正权重: 1.0
- 目标损失增益: 1.0
- 目标 BCELoss 正权重: 1.0
- IoU 训练阈值: 0.2
- 锚框倍数阈值: 4.0
- 焦点损失 gamma: 0.0
- 图像 HSV-Hue 增强: 0.015
- 图像 HSV-Saturation 增强: 0.7
- 图像 HSV-Value 增强: 0.4
- 图像旋转角度: 0.0
- 图像平移范围: 0.1
- 图像缩放范围: 0.5
- 图像剪切范围: 0.0
- 图像透视变换范围: 0.0
- 图像上下翻转概率: 0.0
- 图像左右翻转概率: 0.5
- 图像拼接概率: 0.2
- 图像混合概率: 0.0
提示:安装 Weights & Biases 以记录 YOLOv5 的日志信息,请执行 'pip install wandb'。
是否缓存图像以加快训练速度: 否,这里似乎还可以加速训练。这个训练完后,可以考虑一下使用谷歌的额度来训练了。
视频结果:
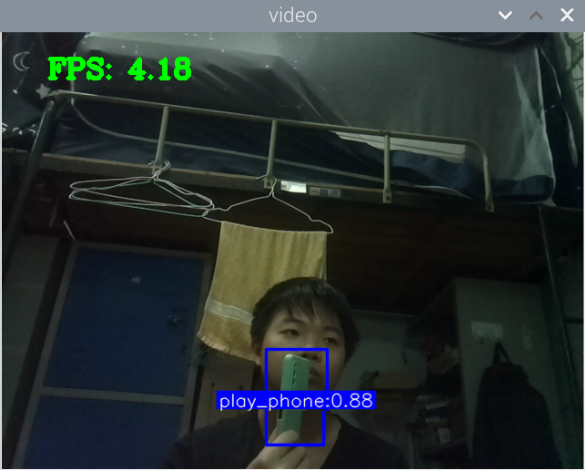
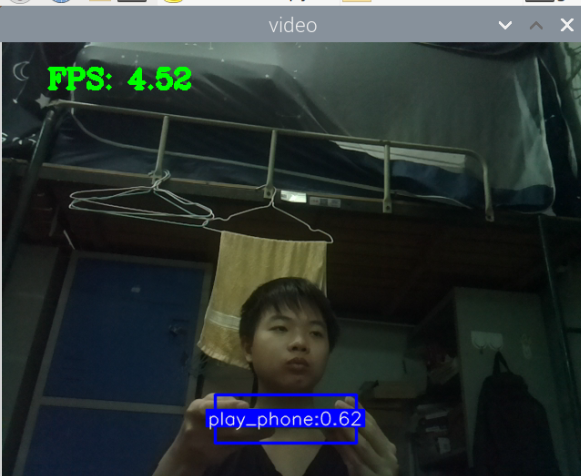

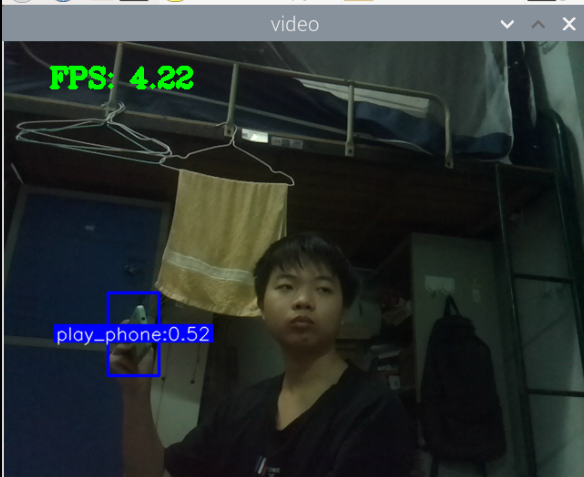


…(标准的有一种没有测出来,后面现实拍摄的图片测出来了一张) 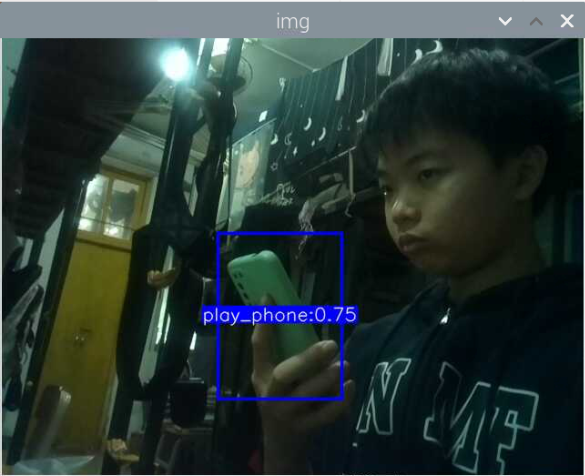
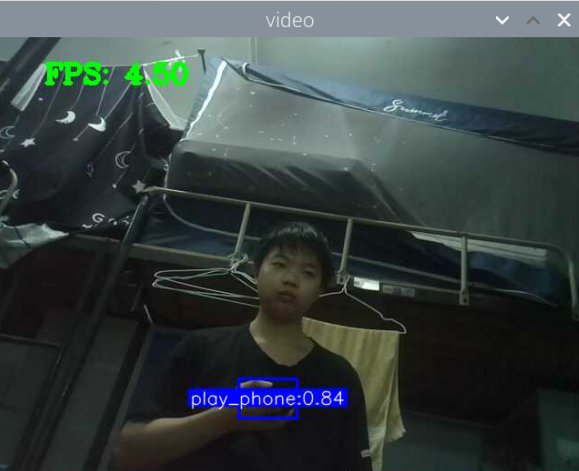
结果:标准图片没有测出1张,现实拍摄图片测出1张,视频检测效果有所提升效果,综合评分14.3分。
图片的检测一如既往,而视频也是,但两者都有所提升,视频竖着正面拿手机可以识别,但竖着侧面的话就难以识别,但好在横着拿手机,也就是打王者的拿手机姿势,就很容易识别出来,不论是正的还是侧的。基本的拿手机的姿势都可以识别,但有时也会识别不出来,说不出原因。
当我两根手指拿手机的时候,发现难以识别,原来识别的更多是手掌“握着”手机,接下来我可以增加特定动作的数据集,来弥补不足,还要增加不同手势“握”手机的数据集。
现在训练耗费时间很长,差不多18个小时,在解决数据集问题的同时,可以考虑一下学习如何使用谷歌的额度。
数据集关键词:床上玩手机、椅子上玩手机、地铁玩手机、教室玩手机、旅游玩手机、飞机玩手机、在饭店玩手机、吃饭时玩手机、酒吧玩手机、办公室玩手机、厕所玩手机、医院玩手机、宿舍玩手机、咖啡玩手机、自行车玩手机、工地玩手机、老人玩手机、孩子玩手机、上班玩手机、走路玩手机、街上玩手机、模特玩手机、
数据集关键词:侧身玩手机、拿手机拍照的人、自拍的人、对镜自拍 女、对镜自拍 女男、对镜自拍 情侣、健身自拍、瑜伽自拍、跑步自拍、草坪自拍、深林自拍、公园自拍、旅游自拍、景点自拍、爬山自拍、游乐园自拍、上班自拍、海 自拍、沙滩自拍、卧室 自拍、阳台自拍、厨房 自拍、
收集了2000多张,训练数据集上万,训练得到的模型效果很好,放在了/home/pi/Desktop/test/models/zhuangtai5,但仍然有两个问题: 1.少部分部分姿势拿手机仍然无法识别
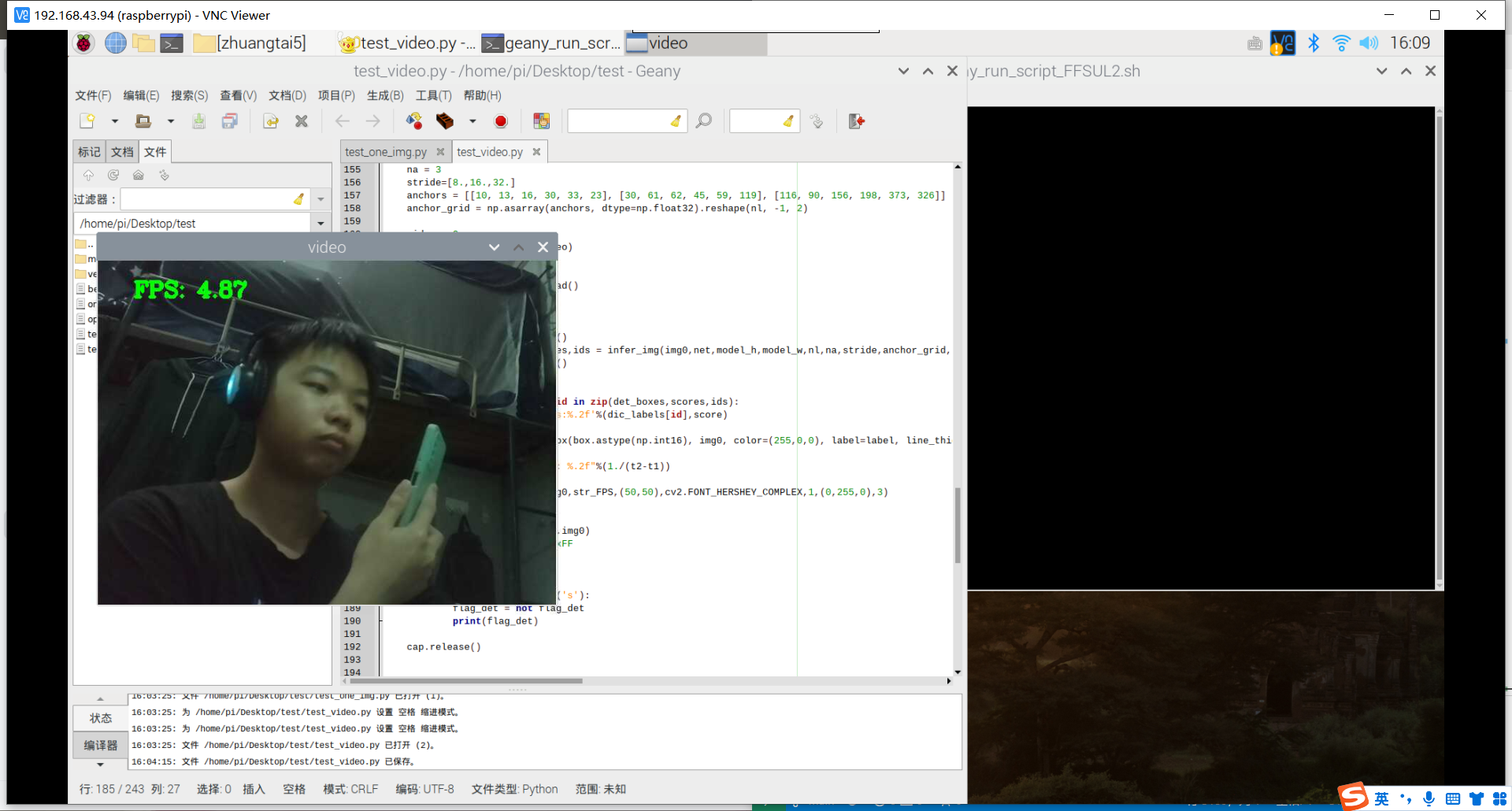
2.能够识别手中拿的“手机”模样的状态,不清楚别是怎么解决的
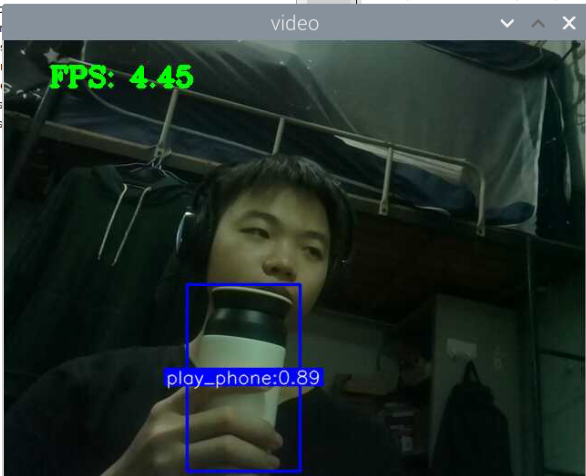
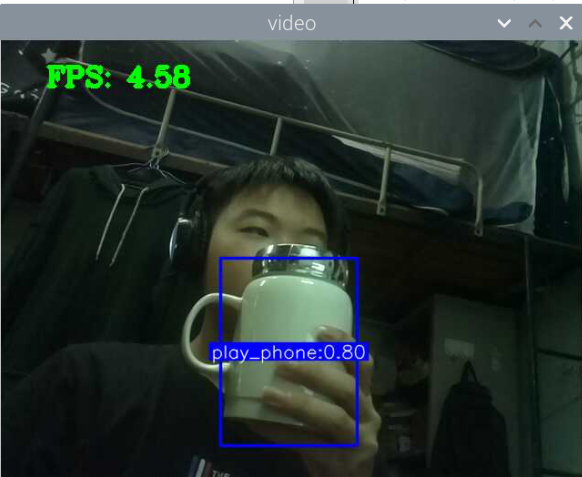
勉强过关了,可以应付一下毕设了。后续再解决这两个问题。