
前言
模型已制作出能够识别玩手机状态,有两个缺点,部分姿势无法识别,其二是手上拿着方方正正的东西都有可能会识别为玩手机。但就床上而言,方方正正的东西一般都为手机,或是书籍。可能还有杯子。这个问题难以解决,或许可以弄上一个姿势的,凡是摆出玩手机的姿态,并且用这个模型还是别出为玩手机的,那就可以认为是玩手机,也就是说两重检测,一个是目标检测,一个是姿态的检测。但现在勉强可以糊弄毕设,先掠过先。
接下来收集书本的数据集,然后制作模型。再然后将这三个模型放到系统中。最后优化细节。希望一切顺利。
书本数据集的模型收集
关键词:床 看书、沙发 看书、桌子 看书、咖啡厅 看书、草地 看书、宿舍看书
效率过低,或许是因为反爬虫的手段,无法直接用爬虫爬取大量的图片,而且图片质量残次不齐,到最后都得手动分辨,所以一直以来都是手动拖动图片保存,但保存命名一样,所以还得手动重命名,这很浪费时间。
所以打算整一个脚步,用于在保存网络图片时自动重命名为顺序数字,并且能够持续运行监控文件夹变化,那样看到图片然后拖动到文件夹哪里就可以了,应该能节省五分之三的时间。效果非常好,很爽。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
import os
import time
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
# 指定图片保存的目录
image_directory = "D:/git_cangku/data/book/book_data_collect2/train/images"
# 创建一个事件处理器类,用于监控文件夹中的变化
class ImageRenameHandler(FileSystemEventHandler):
def __init__(self, directory):
self.directory = directory
self.last_renamed = self.get_last_image_number()
def get_last_image_number(self):
# 获取目录中的所有文件
files = os.listdir(self.directory)
# 筛选出图片文件
image_files = [f for f in files if f.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp'))]
# 按文件名转换为数字后进行排序
image_numbers = [int(os.path.splitext(f)[0]) for f in image_files if f.split('.')[0].isdigit()]
# 返回最大的数字,如果没有图片则返回0
return max(image_numbers, default=0)
def on_created(self, event):
# 只对文件进行处理
if not event.is_directory:
# 获取文件扩展名
extension = os.path.splitext(event.src_path)[1].lower()
# 检查是否为图片文件
if extension in ('.png', '.jpg', '.jpeg', '.gif', '.bmp'):
# 等待文件写入完成
time.sleep(1)
# 重命名文件
self.rename_file(event.src_path)
def rename_file(self, file_path):
# 定义新的文件名
new_filename = f"{self.last_renamed + 1}{os.path.splitext(file_path)[1]}"
# 重命名文件
os.rename(file_path, os.path.join(self.directory, new_filename))
# 更新最后重命名的编号
self.last_renamed += 1
# 创建事件处理器实例
event_handler = ImageRenameHandler(image_directory)
# 创建观察者对象
observer = Observer()
observer.schedule(event_handler, image_directory, recursive=False)
# 开始监控
observer.start()
print(f"开始监控目录 {image_directory} ...")
try:
# 保持脚本运行
while True:
time.sleep(1)
except KeyboardInterrupt:
# 停止监控
observer.stop()
observer.join()
# 打印成功信息
print(f"目录 {image_directory} 中的图片已成功重命名为顺序数字。")
关键词:床 看书、沙发 看书、桌子 看书、咖啡厅 看书、草地 看书、宿舍看书、河边看书、晨 光 看书、老年人 看书、车 看书、飞机 看书、飞机 读书、车 读书、街边 读书、客厅 读书、卧室 看书、吊床 看书、孕妇 看书 、雨 看书、船 看书、码头 看书、树下 看书、办公室 看书、沙滩 看书、躺椅 看书、酒吧 看书、音乐 看书、火车 看书
手机了2000张,感觉这次的训练难度应该会比手机的难很多,书本的状态有很多,正侧斜,打开合上,书堆等等,可能需要的样本得很多才能训练好。 或许应该分为几个词:读书(单个书本,打开书本读书),书堆(多本书)
所以可以搜寻一下书本的数据集,单单靠自己搞太累了。
2024年4月10日13:06:50
我希望能够打开标准数据集的标签,看看标标签的规范,但失败,重新安装labelme,用标准官方的labelme试试能不能打开
最后还是不能,结果是使用python脚本解析标注数据并在图片上绘制边界框,

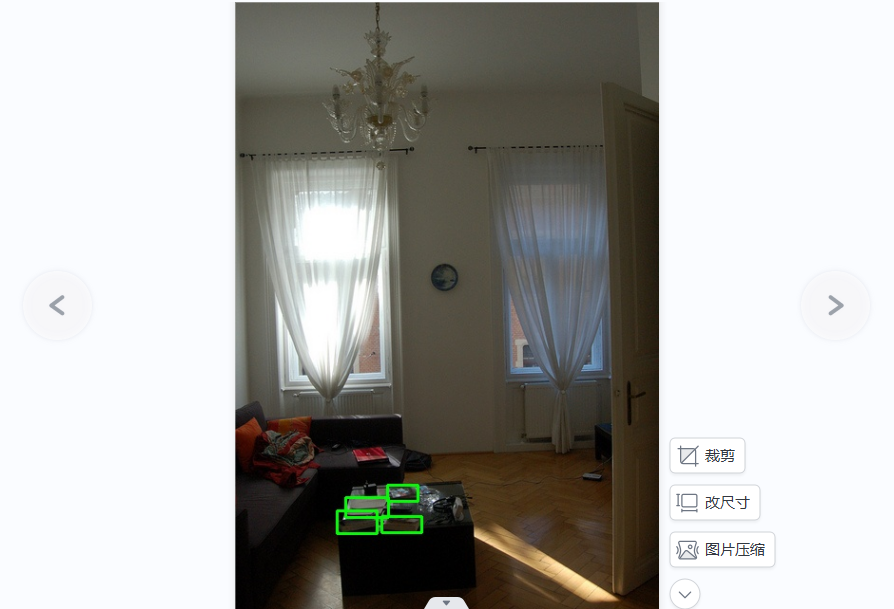


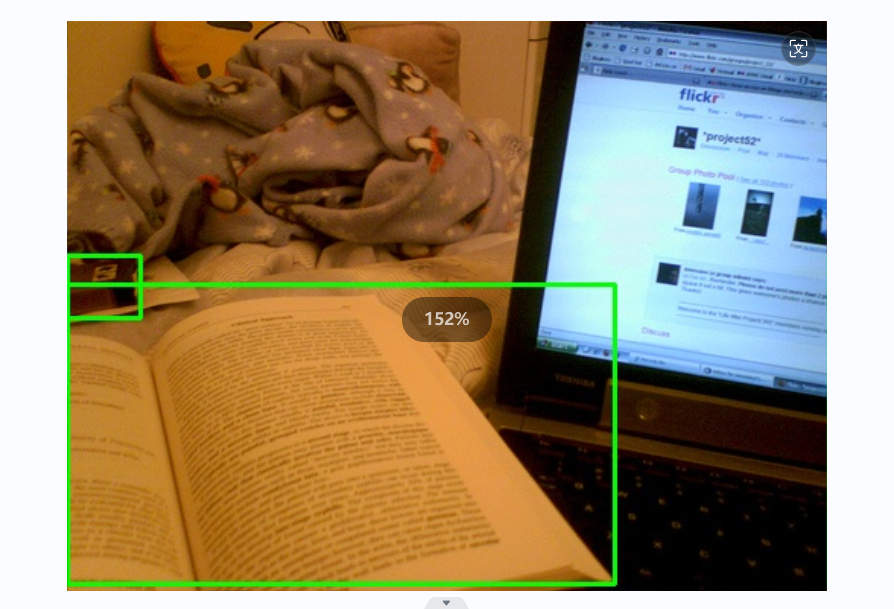

















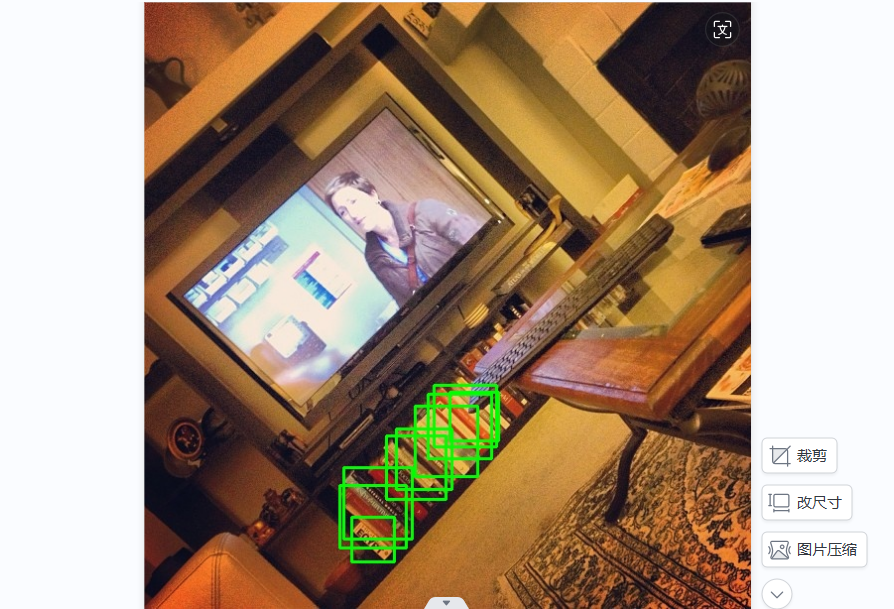
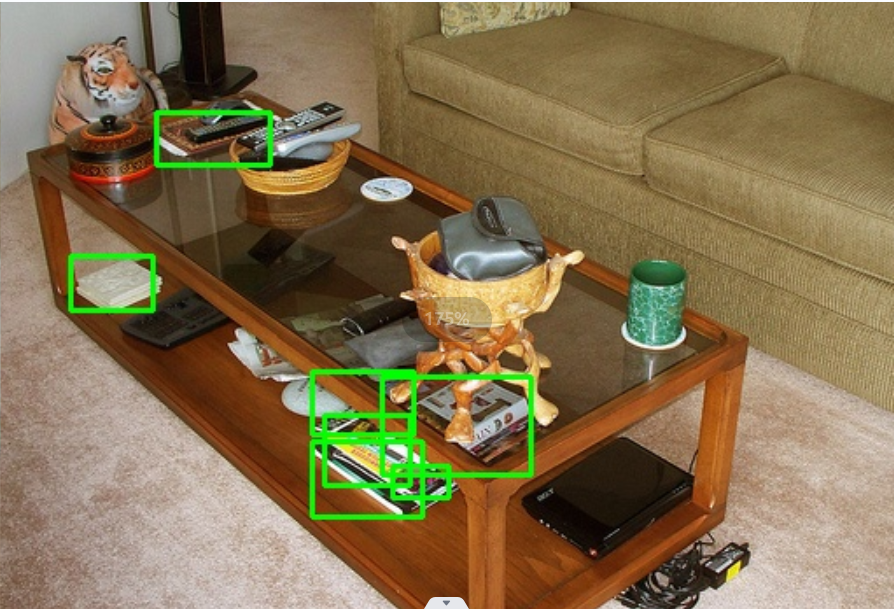



标准标准的数据集并非完美,我认为只是遵从一个规则,就是尽可能多的、多角度的提取“有用信息”,而无用的杂质,则越少越好,重复的可以不标。
接下来按照这个标准将2000张的图片标注,然后学习使用谷歌的额度,训练。
在谷歌的colab上进行训练,按照方法https://blog.csdn.net/djstavaV/article/details/112261905,发现还是不太方便,需要将数据集上传到云端的网盘上,需要大概1个多小时,然后训练的时候需要将云端的数据集资源下载下来,这很费时间。
用电脑训练大概要11.5h,而云端训练则只有3个小时的额度
云端训练淘汰,速度并没有想象中的快得飞起,还是用自己电脑训练比较好。
5000张照片的视频识别结果(标签没改,): 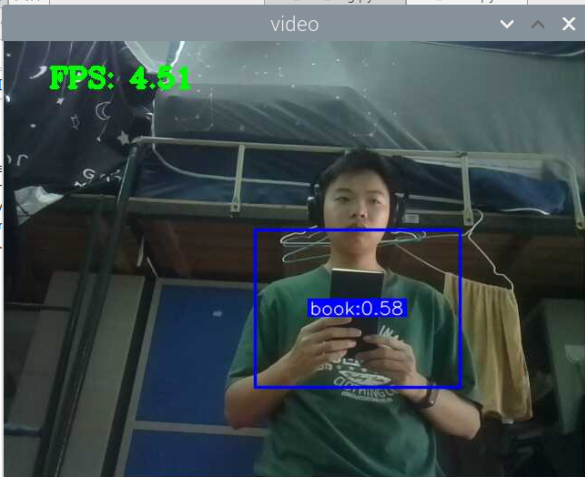
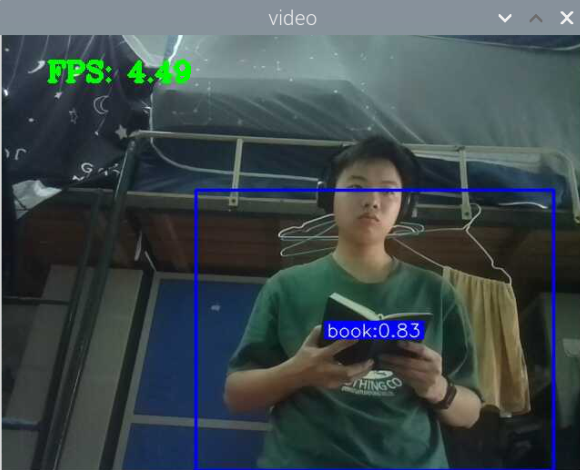
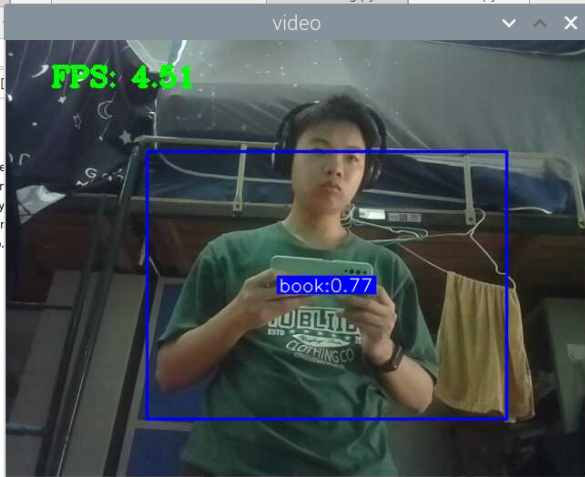
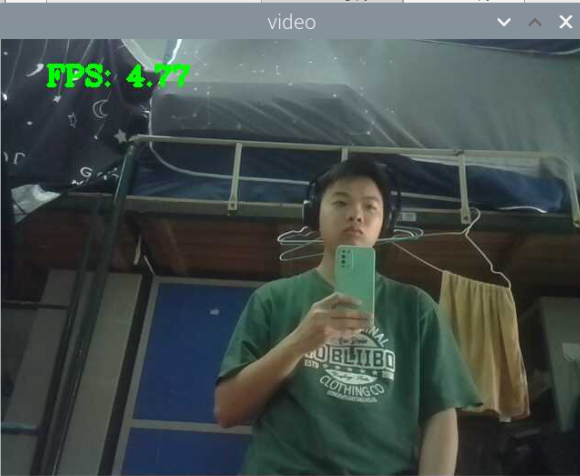
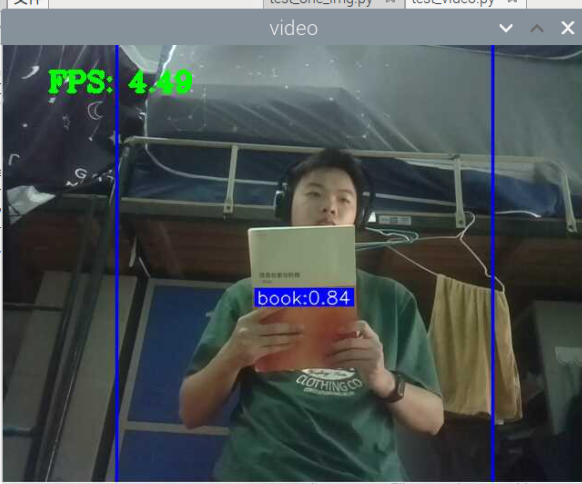



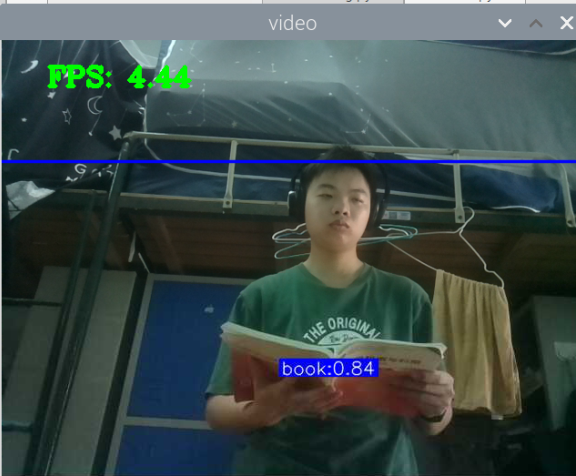
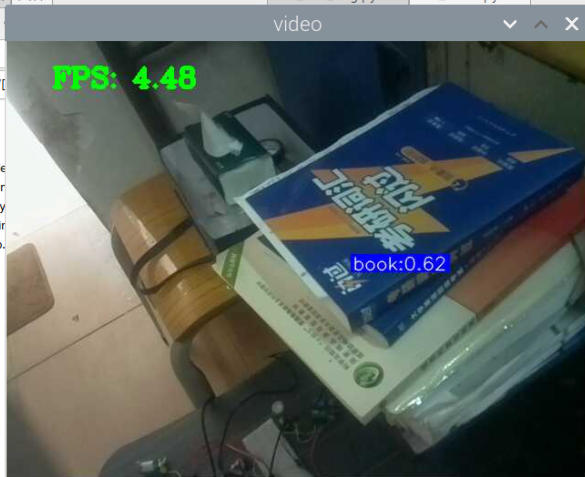

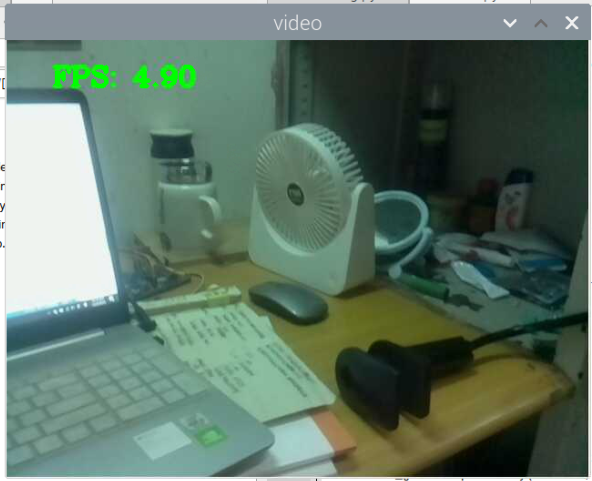
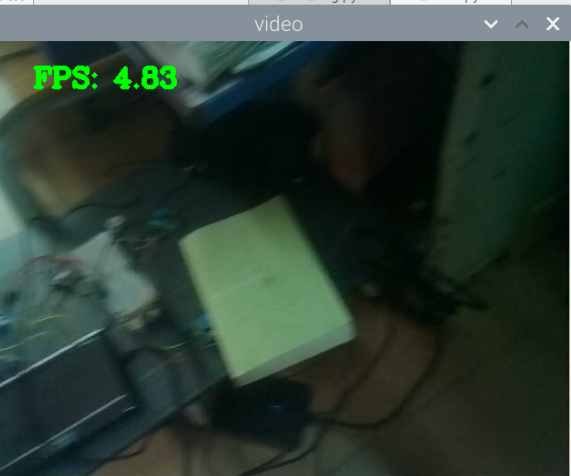
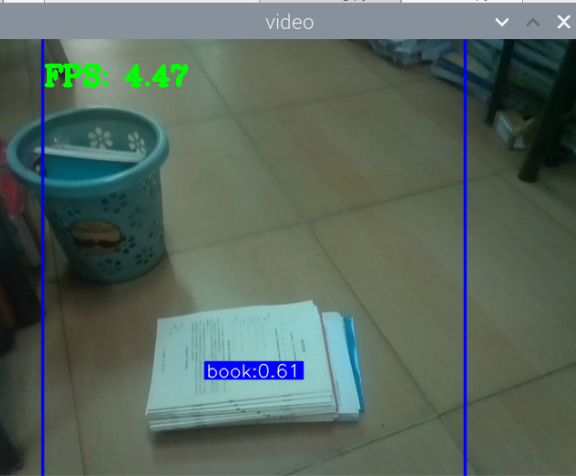
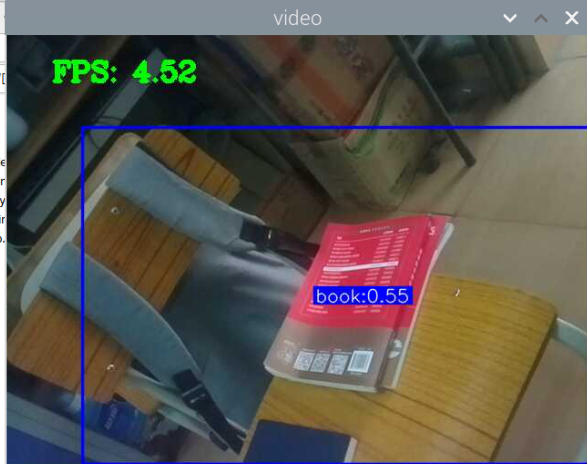

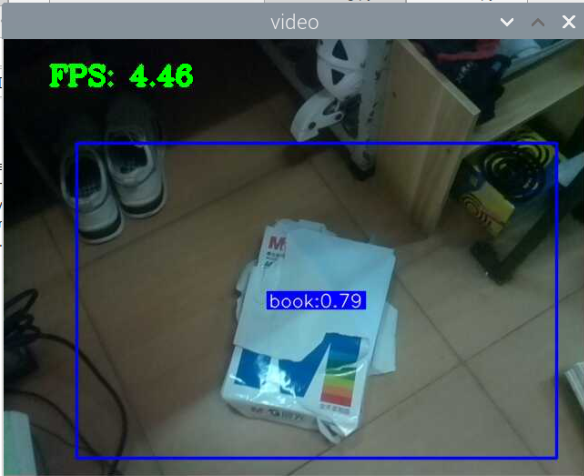
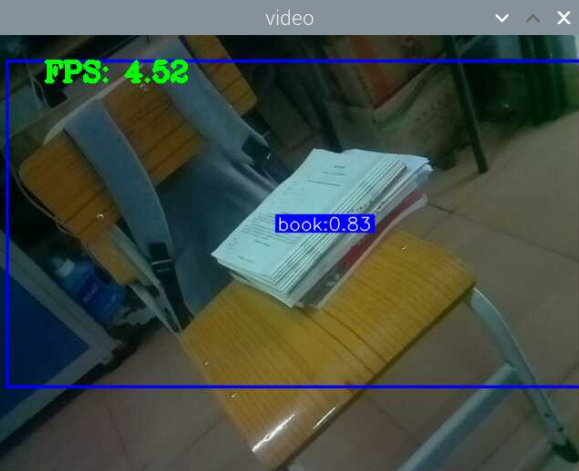
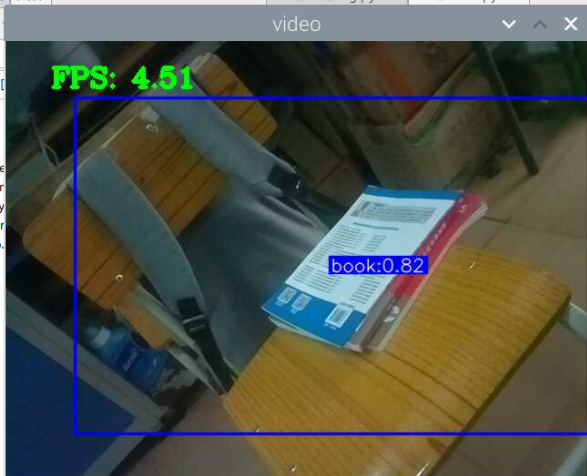

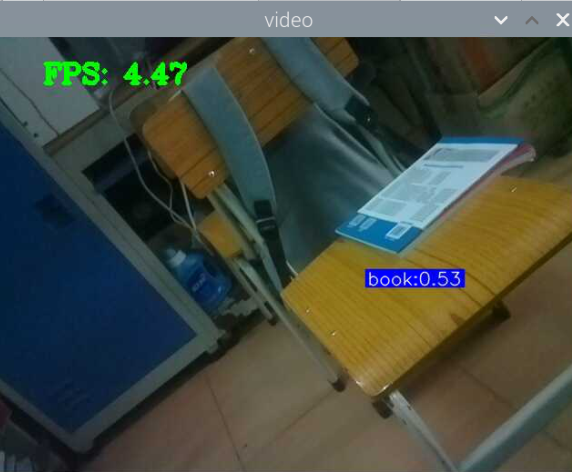
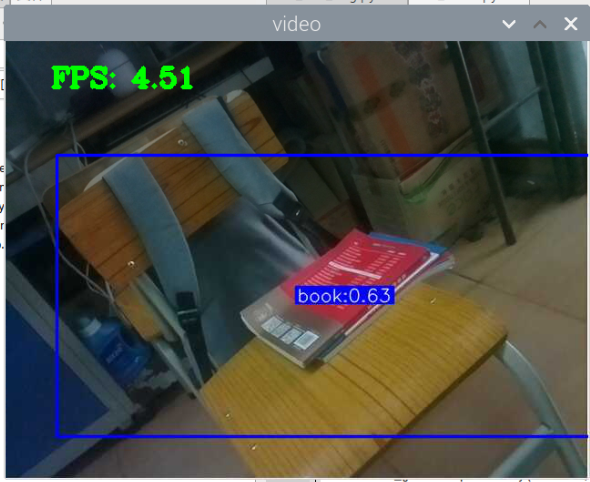
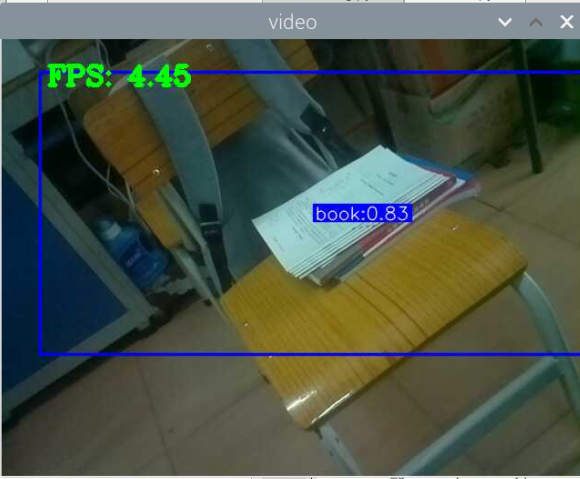
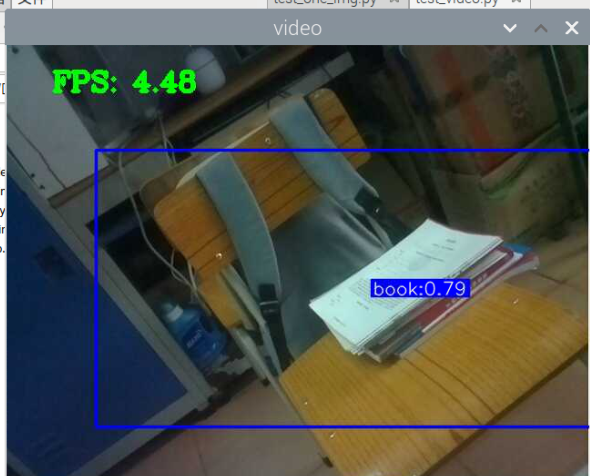
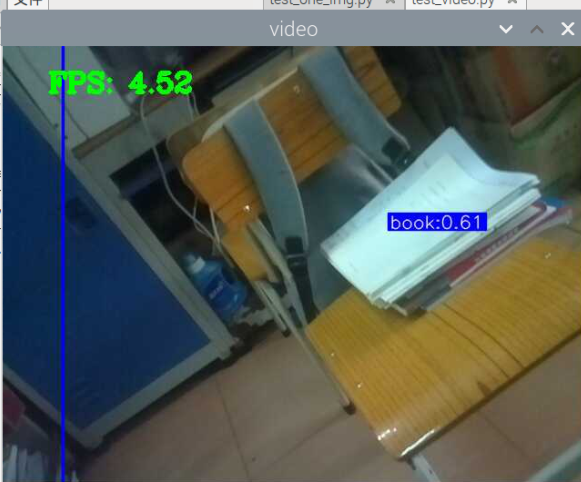
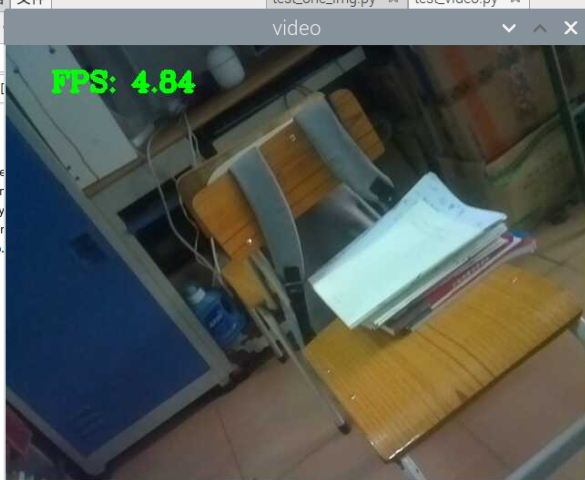
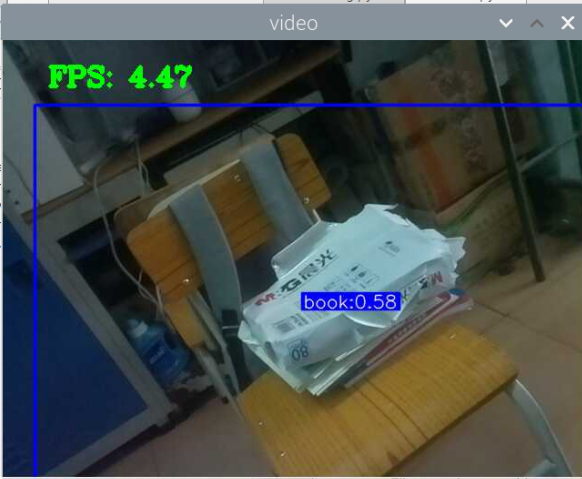
图片识别结果: 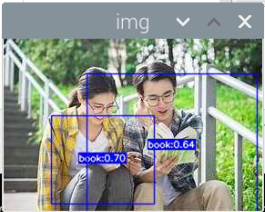
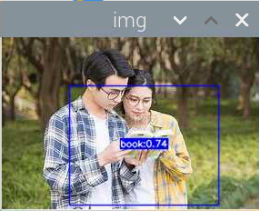
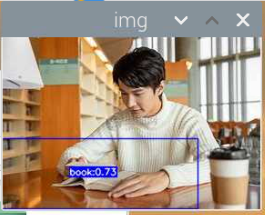

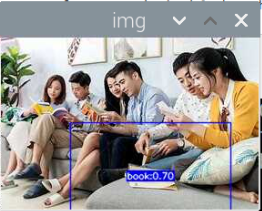
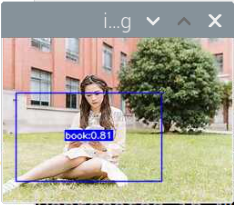

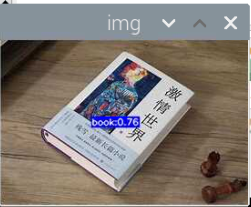
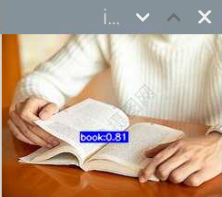

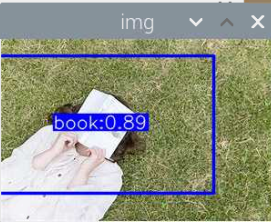
评分:6.5/10
总结:书本识别正身识别效果较好,不论书是正面拿还是平着拿,识别都较为满意,而书本的侧身识别很差,偶尔能够识别出来,可以说除了正身持书外的其他姿势,识别效果都比较差。除了持书的识别外,还测试了书本的识别,对于单本书的识别效果很差,对于有一点厚度的书堆效果比较好,而过后和过薄效果都变差了,对于有遮挡的书,识别不好。
分析:应该分为三种标签,一种是book,一种是read_book,一种是books。也就是一种是手持书本,一种是书本,一种是书堆。对于手持书本,应该要尽可能的找更多姿势的数据集,对于书本,应该也要找更多位置大小遮挡的数据集。所以需要将过去的数据集再分一些类,重新标注标签,然后在添加新的 。 此外,对于识别出来后,框框大小不一很奇怪的问题,应该是书堆,书,手持书这三个框框大小不一的影响。
尝试: 1.将数据集再分类 2.丰富数据集 3.训练模型
cao ,labelme居然有点问题,居然没有保存,浪费我时间。
将数据集弄好后,训练,睡觉,发现昨天停电,电脑关机。要恢复训练。
1
2
3
4
5
6
要继续从上次中断的训练继续进行,你可以使用last.pt文件作为权重来恢复训练。这个文件代表训练过程中最后一次保存的模型状态。使用这个权重文件,你可以继续训练,而不需要从头开始。 这里是如何使用last.pt文件继续训练的示例命令:
python train.py --weights C:\Users\123\Desktop\yolo\YOLOv5-Lite-master\runs\train\exp\weights\last.pt --resume
这里的关键参数包括:
--weights 指定要加载的预训练权重文件路径。
--resume 指示训练脚本从上次中断的地方继续训练。
确保你的命令行工具当前路径或者在命令中指定的路径正确指向你的项目目录,否则可能会因为找不到相应的文件或脚本而运行失败。
结果:效果比第一次的还差,我将book的标签分为了3个,变得更麻烦了。或许我应该直接增加book的数据集就好了。还有一个问题就是会吧玩手机当成看书
当你使用YOLOv5-lite或任何其他对象检测模型时,遇到模型之间的混淆识别问题,是因为模型在辨识不同类别时可能存在一定的重叠或模糊性。以下是几个策略,可以帮助改善你面临的问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
1. 数据增强和优化
更多数据: 确保你的训练数据集足够大且多样化,涵盖各种场景和背景。尤其是增加模型混淆的情况(例如,当你拿着手机而被错误识别为看书时的场景),确保这些场景在训练数据中有良好的代表性。
质量审查: 对训练数据进行审查,确保标签的准确性。错误的标注会直接影响模型的性能。
数据增强: 通过数据增强(如旋转、缩放、裁剪和颜色调整)来增加数据的多样性,这有助于模型学习到更鲁棒的特征。
2. 模型架构和训练调整
尝试不同的模型架构: 除了YOLOv5-lite,可以试验其他模型架构,看是否有改善。
超参数调整: 调整学习率、批大小、训练轮数等超参数,找到最优的训练策略。
特征融合技术: 探索不同的特征提取和融合技术,以增强模型对不同物体特征的区分能力。
3. 后处理策略
置信度阈值调整: 调整模型的置信度阈值,以减少误检。通过提高阈值,模型只有在更加确信的情况下才会做出判断。
非最大抑制(NMS): 调整NMS参数,以减少重叠检测框,从而减少误判。
4. 联合使用两个模型
决策融合: 如果你有两个专门的模型,一个用于检测玩手机,另一个用于检测看书,可以尝试联合使用这两个模型的输出来做最终的决策。例如,如果两个模型都给出了高置信度的预测,可以设置规则优先考虑其中一个(根据情况来定)。
模型集成: 通过集成学习方法,结合多个模型的预测结果来提高整体的准确率和鲁棒性。
5. 进行误差分析
详细分析: 对模型进行误差分析,找出哪些类型的实例最容易被误判。这有助于指导如何收集更多的、能够解决特定问题的训练数据。
通过以上的一些策略,你可以逐步优化和提升模型在特定任务上的表现。始终记得,机器学习和模型优化是一个迭代和逐渐改进的过程。
关键词:床 看书、沙发 看书、桌子 看书、咖啡厅 看书、草地 看书、宿舍看书、河边看书、晨 光 看书、老年人 看书、车 看书、飞机 看书、飞机 读书、车 读书、街边 读书、客厅 读书、卧室 看书、吊床 看书、孕妇 看书 、雨 看书、船 看书、码头 看书、树下 看书、办公室 看书、沙滩 看书、躺椅 看书、酒吧 看书、音乐 看书、火车 看书、教室 写试卷、自习室 练习册、咖啡 练习册、报刊 书店、屋顶 看书、眼镜 看书、落叶看书、篝火看书、光 影 书、走路看书
太麻烦了,还是再尝试找找有没有现成的数据集。
找了一轮,没找到,但发现了半自动的标注方法,可以先训练一个初步的模型,然后用这个模型进行标注,再然后手动调整。所以首先我需要找到足够多的合适的图片,大概要4000张。
尝试: 1.增加4000张数据集 2.优化数据集,将容易当成手机的数据集优化删除 3.标注数据集 4.了解数据增强(gpt)
将这些关键词翻译成英文然后再手机数据集
结果: 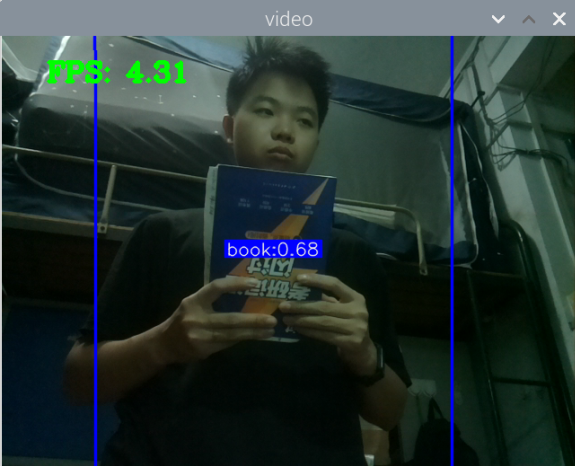
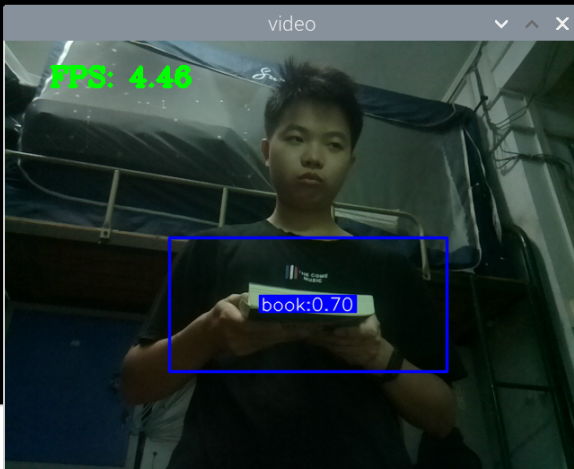
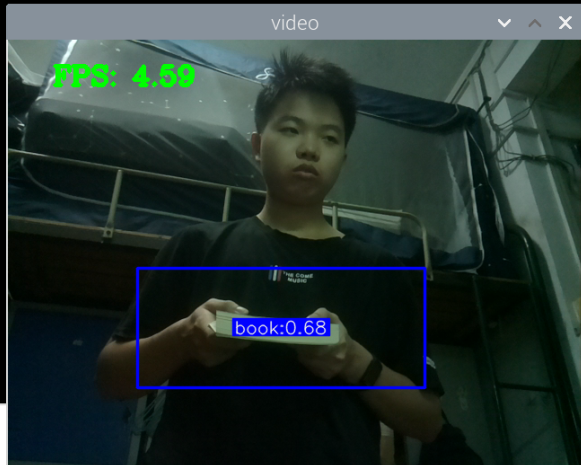
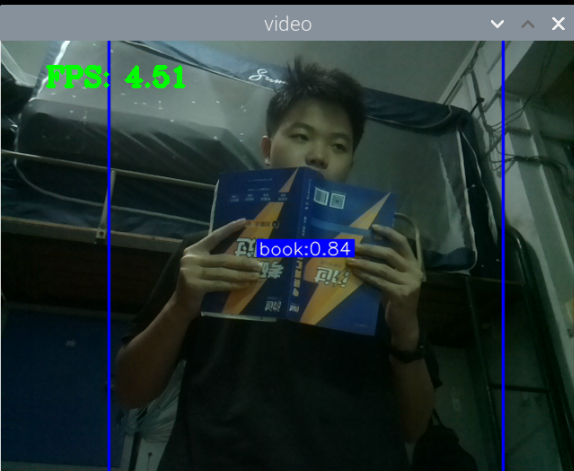

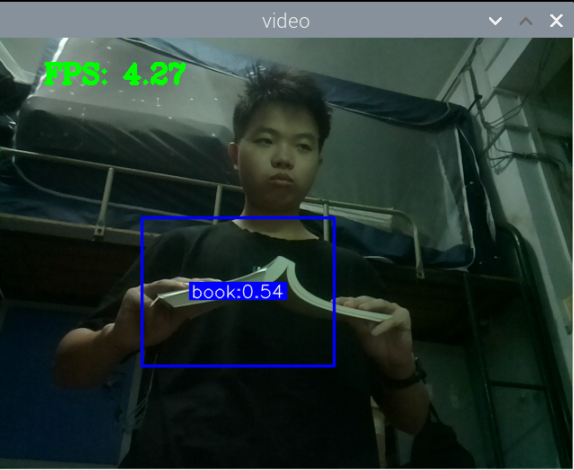
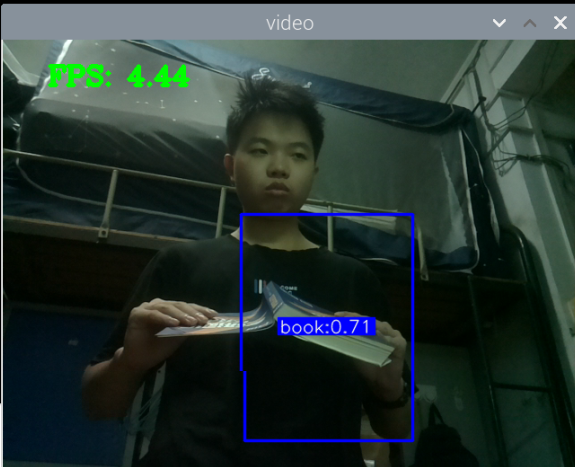
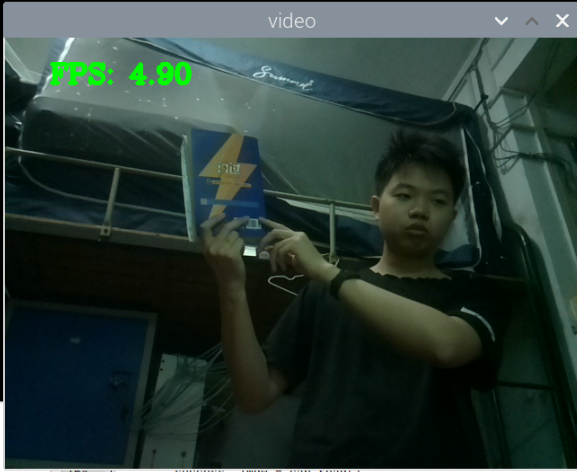

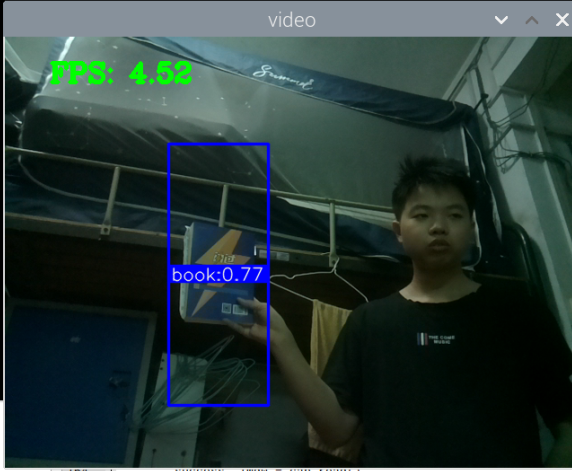
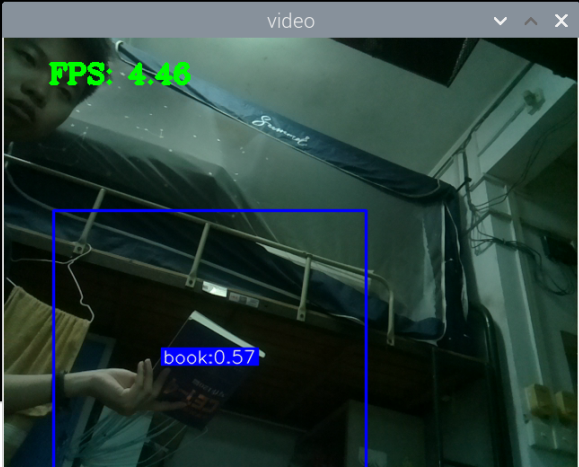

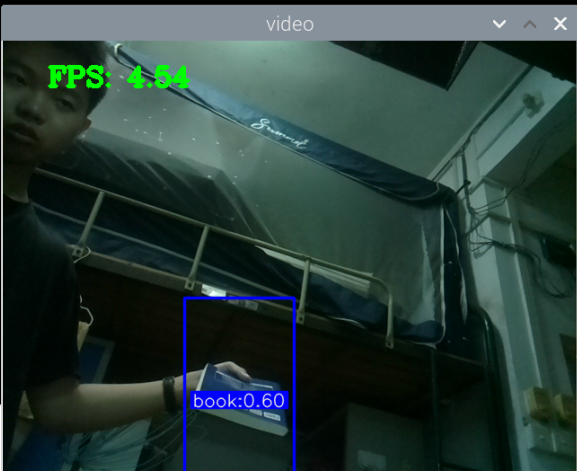
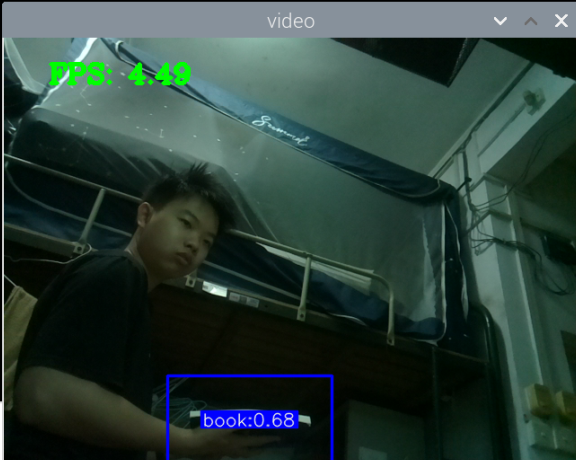
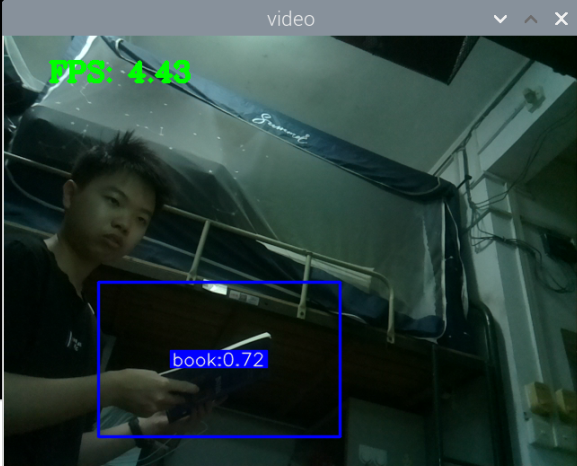
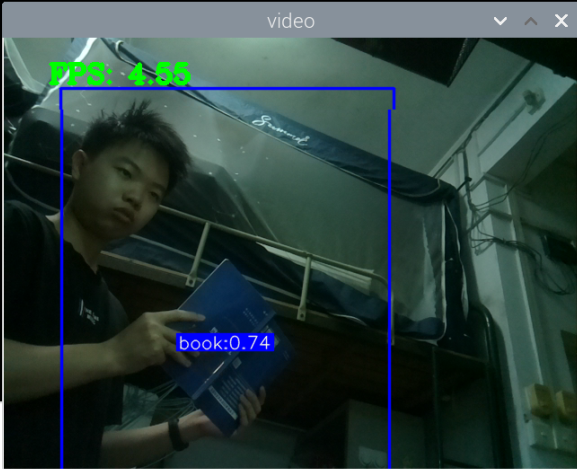
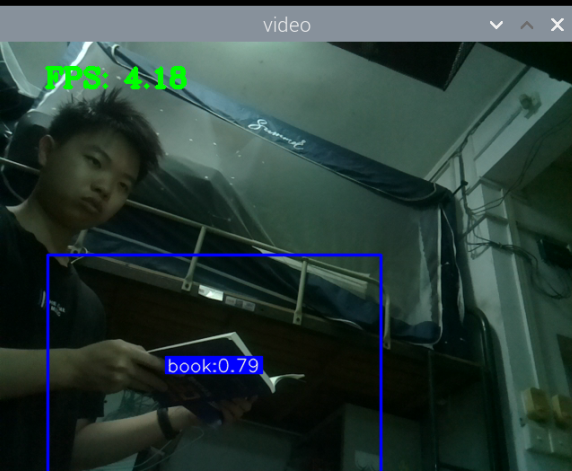
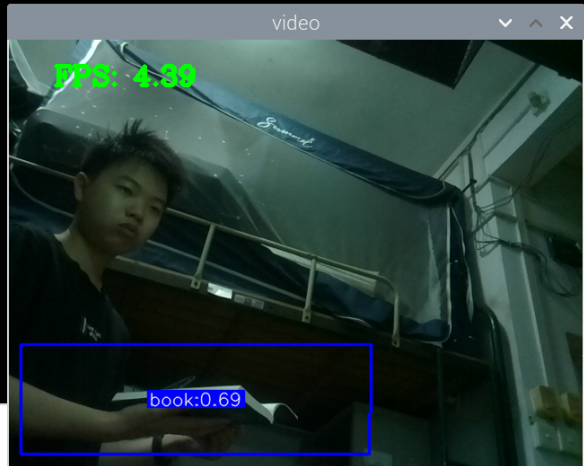
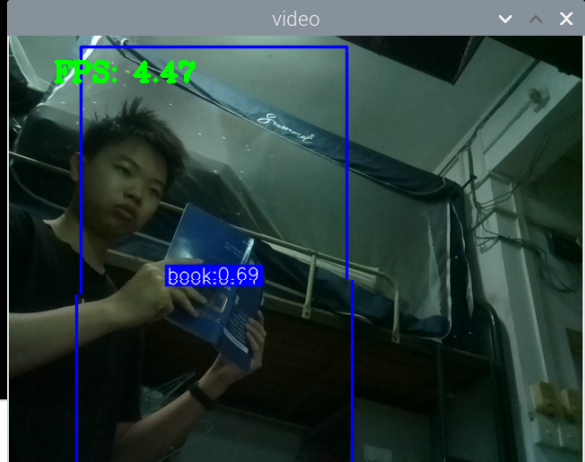
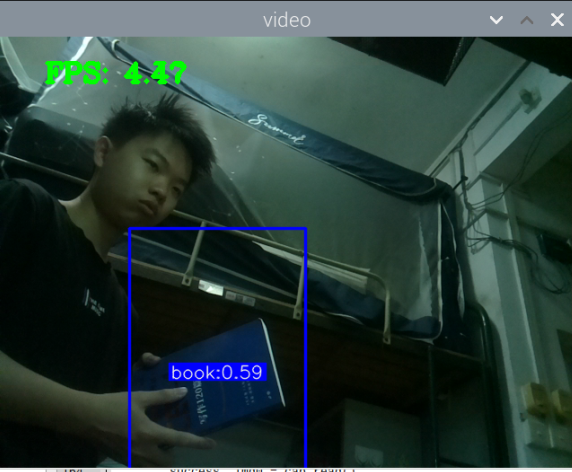
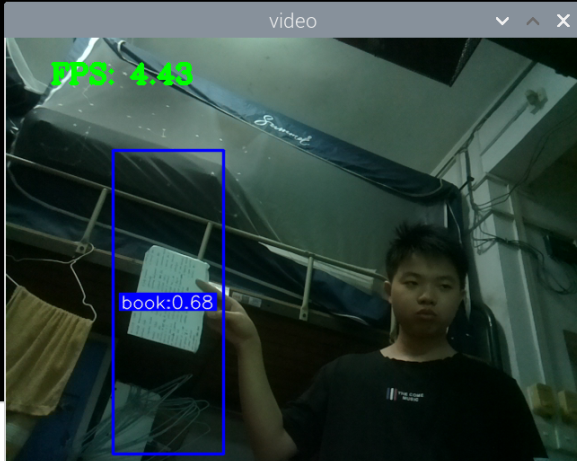

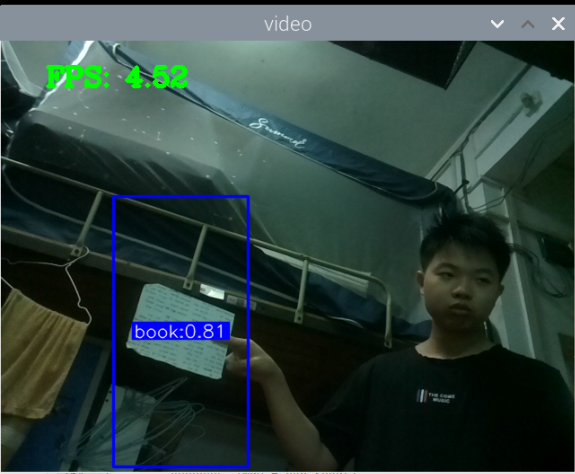
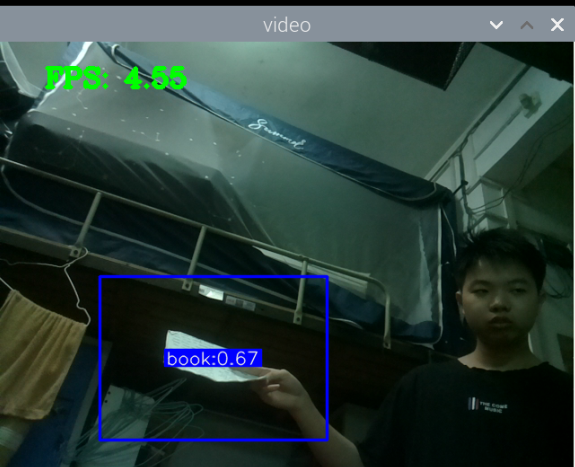
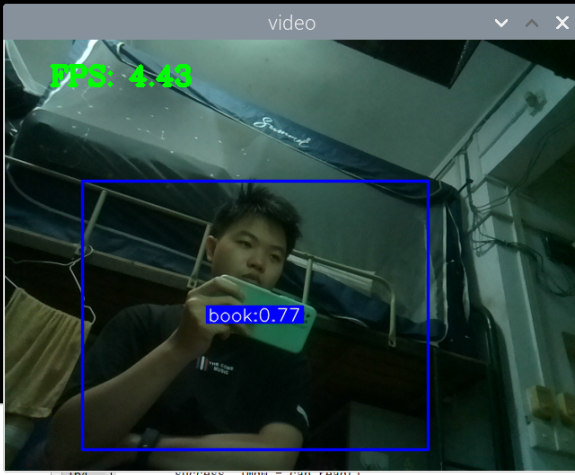
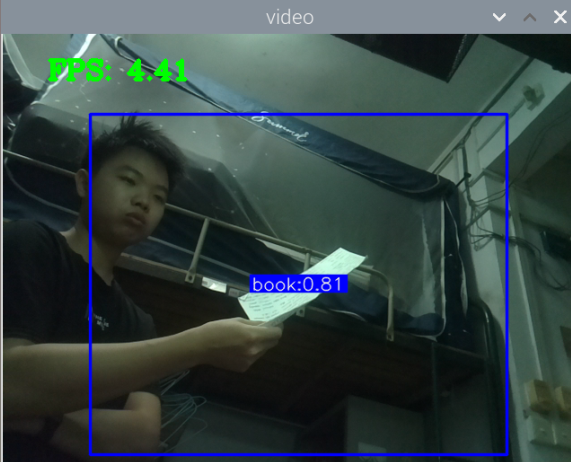
最初版本的测试: 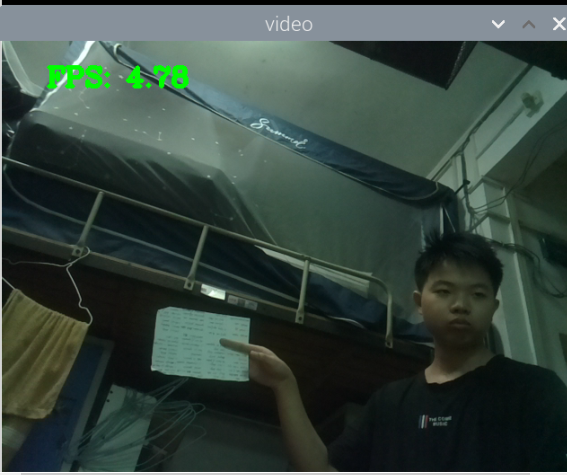
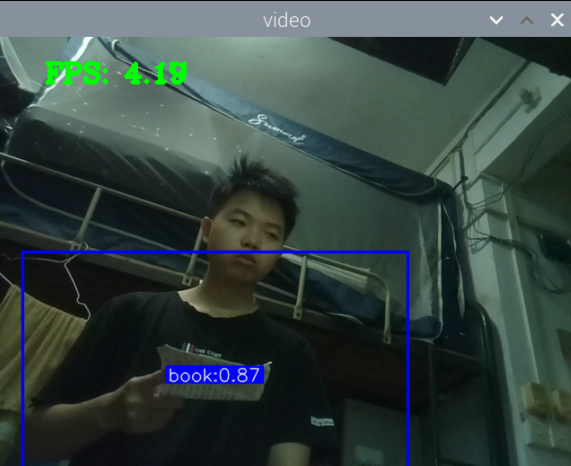

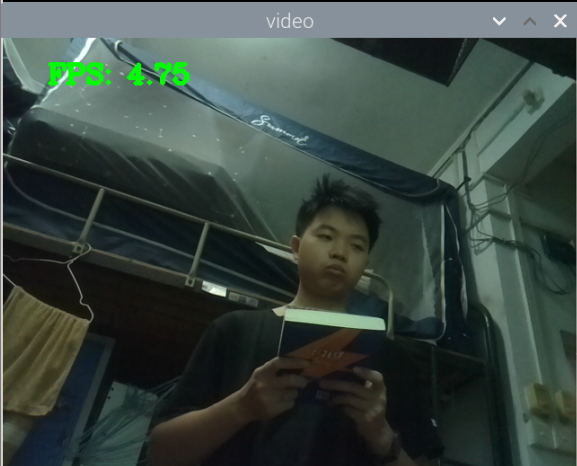
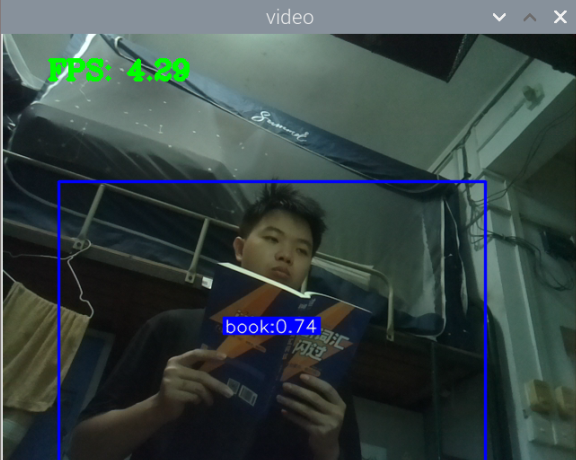
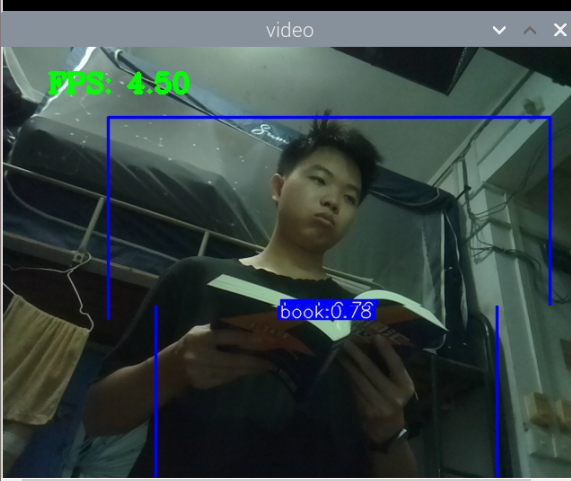
测手机的模型: 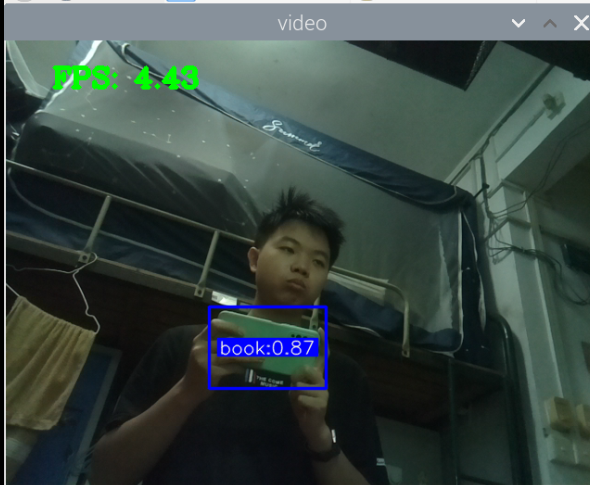
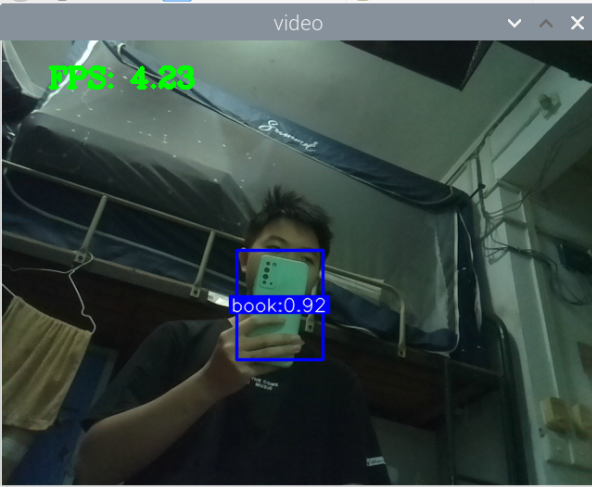
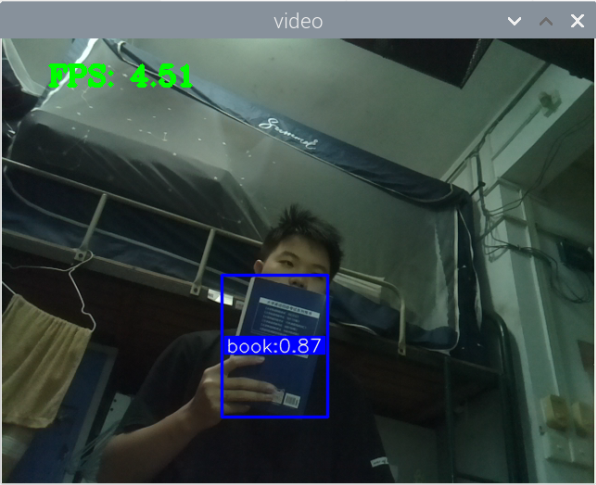
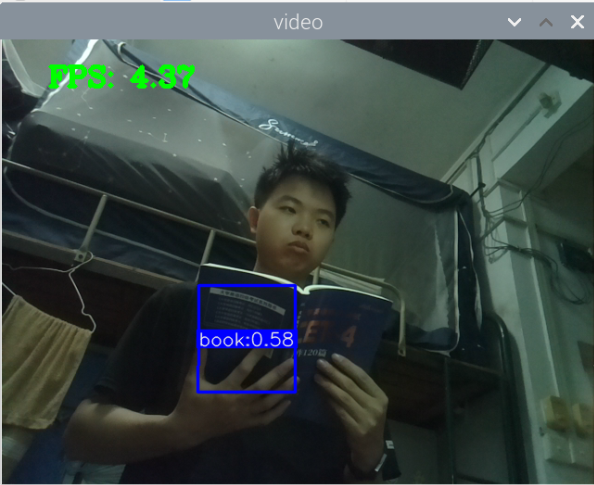
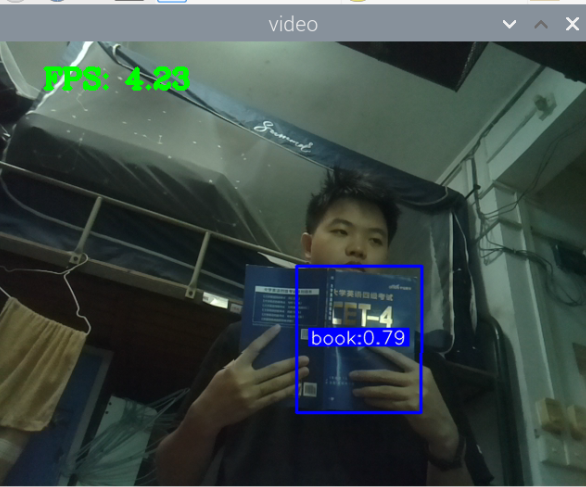
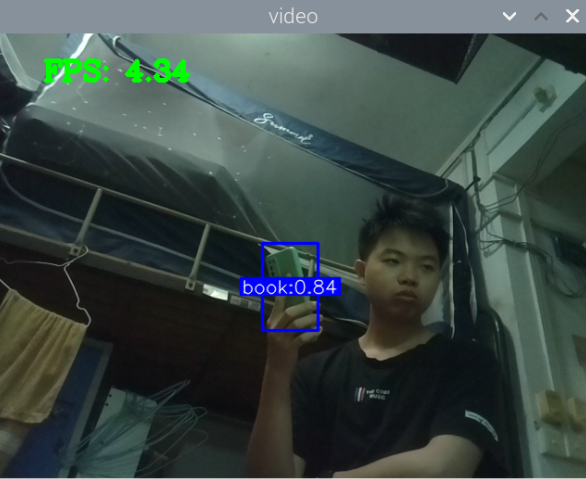
总结:新书本数据集得到的模型3还行,就是侧身拿书的时候测不了,感觉可以增加一些这方面的数据集就可以了,此外,数据集中还喂很多的单独识别书的图片,但却没有识别出来书本,这很奇怪。
此外,最大的问题就是,如何区分书本和收集这两种状态,看手机和看书总是会混淆。正身玩手机可以很好的识别出来,置信很容易达到90以上,而其他的动作也可以识别,也能达到80.但若是那书本看书的话,有些时候也会被识别为玩手机,置信大概在80-90之间,但看书某些动作,也是会被识别为玩手机。这个问题最关键。
性能分析
来观察模型的性能:
results.txt: 这个文本文件包含了训练过程中的详细统计数据,包括精确率、召回率和mAP等指标。 confusion_matrix.png: 混淆矩阵图可以帮助您了解模型在不同类别上的表现。 F1_curve.png: F1曲线图展示了模型在不同置信度阈值下的F1分数。 P_curve.png: P曲线图表示模型的精确率随着不同阈值的变化。 PR_curve.png: 精确率-召回率曲线图展示了模型在不同阈值下的精确率和召回率。
result.txt文件是YOLOv5-lite训练过程中生成的文本文件,包含了详细的统计数据,用于评估模型的性能和进展。该文件的内容如下所示:
每一行表示一个训练批次的结果,其中包含了各种指标的数值。以下是每个字段的含义:
- 第一列:训练批次的编号。
- 第二列:GPU使用量(以G为单位)。
- 第三列:损失值(loss)的平均值。
- 第四列:坐标损失(xy loss)的平均值。
- 第五列:宽高损失(wh loss)的平均值。
- 第六列:对象置信度损失(object confidence loss)的平均值。
- 第七列:无对象置信度损失(no-object confidence loss)的平均值。
- 第八列:类别损失(class loss)的平均值。
- 第九列:当前学习率。
- 第十列:当前精确率(precision)。
- 第十一列:当前召回率(recall)。
- 第十二列:当前的平均精确率(average precision)。
- 第十三列:最佳平均精确率(best average precision)。
- 第十四列:训练时间(以秒为单位)。
损失值(loss):损失值的平均值显示了模型在每个训练批次中的训练误差。较低的损失值通常表示模型的学习效果较好。
精确率(precision)和召回率(recall):这些指标表示模型在检测任务中的准确性和覆盖率。较高的精确率意味着模型能够准确地检测目标,而较高的召回率表示模型能够找到更多的目标。
平均精确率(average precision):平均精确率是在不同阈值下计算的精确率的平均值,通常用于评估目标检测算法的性能。较高的平均精确率表示模型在各个阈值下都能保持较好的准确性。
通过分析result.txt文件,您可以了解模型在每个训练批次中的性能表现,包括损失值、精确率、召回率和平均精确率等指标的变化情况。这些统计数据可以帮助您评估模型的训练效果,并进行进一步的优化和调整。
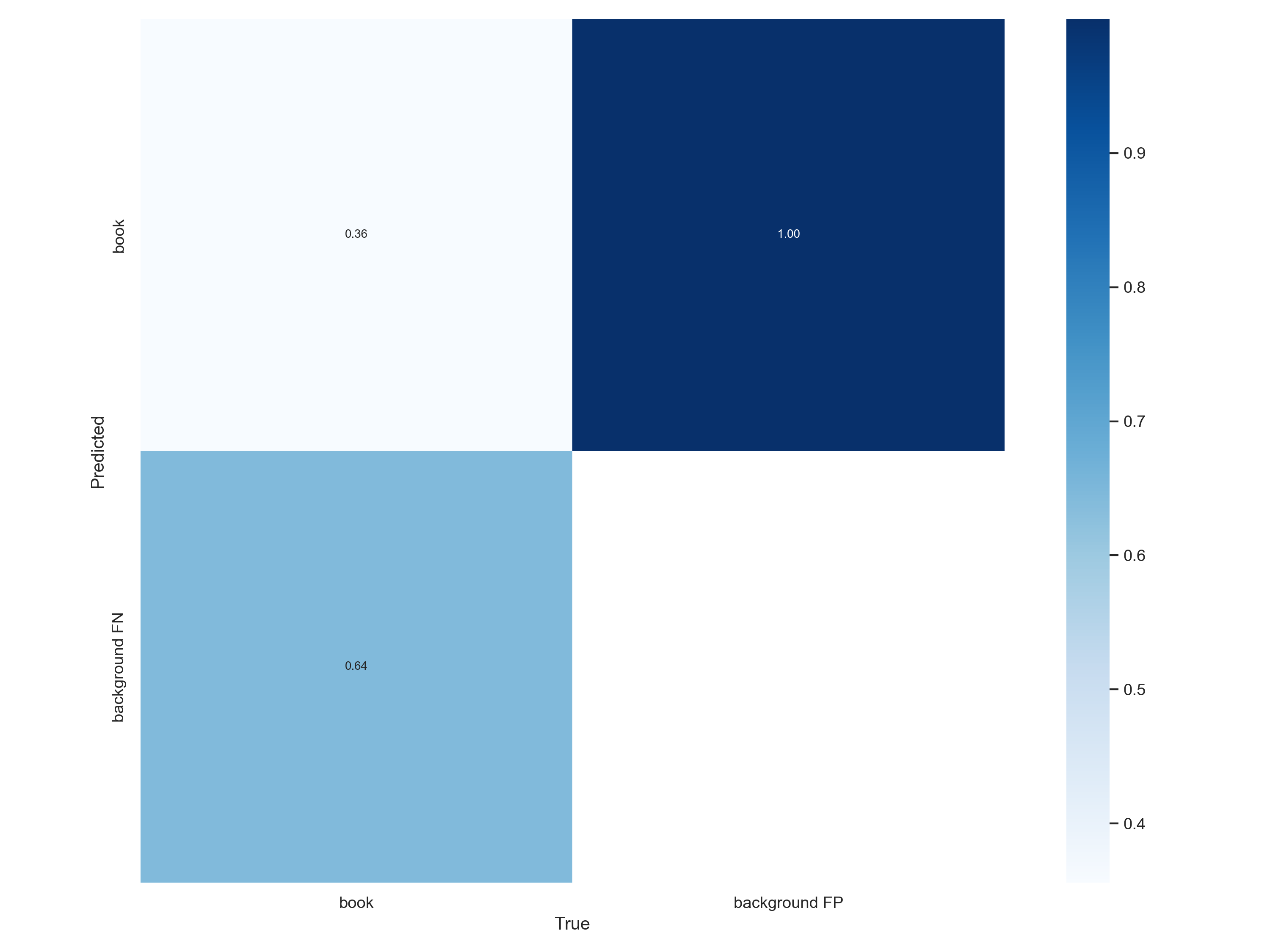
confusion_matrix分析

F1_curve分析
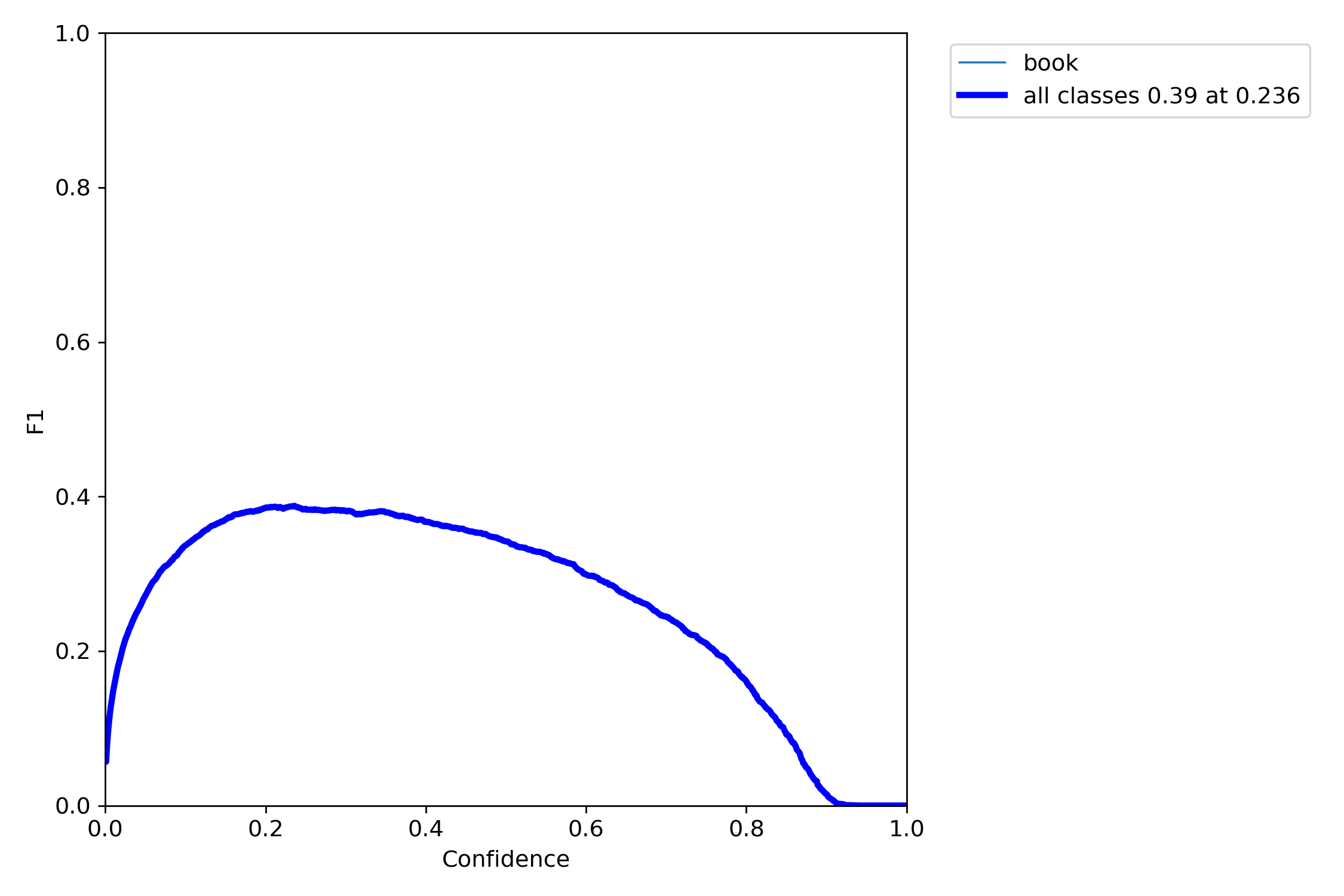
根据您上传的图像,它显示了一个F1分数与置信度的关系图,这有助于我们理解模型在识别“书本”时的效率和准确性。在图中,F1分数在置信度约为0.236时达到峰值,大约为0.39,这表明了在特定的分类任务中,精确度和召回率之间的最佳平衡点。
F1分数是精确率和召回率的调和平均数,是评估分类模型性能的重要指标。理想情况下,我们希望F1分数尽可能高,因为这意味着模型在保持较高召回率的同时,也具有较高的精确率。在您的模型中,最佳的F1分数出现在置信度为0.236时,这可能是您在进行模型调优时需要考虑的一个重要阈值。
P_curve分析
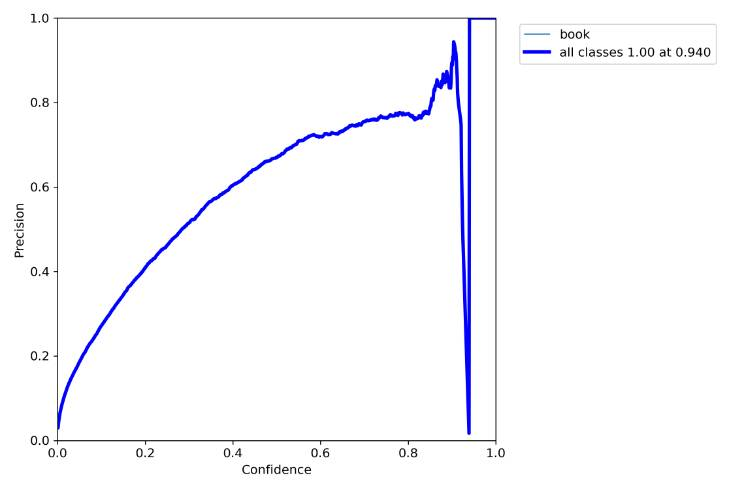
根据您上传的精确率-召回率曲线图,我们可以分析模型在识别“书本”类别时的性能。这个曲线图展示了在不同置信度阈值下,模型的精确率和召回率的关系。
在曲线图中,我们可以看到:
精确率(Precision): 模型预测为“书本”且实际上也是“书本”的比例。 召回率(Recall): 模型正确识别出的“书本”占所有实际“书本”的比例。 理想情况下,我们希望模型的精确率和召回率都很高,但在实际应用中,通常需要在两者之间找到一个平衡点。这个平衡点可以通过调整模型的置信度阈值来实现。
曲线图上的每一点都代表了一个特定的置信度阈值下的精确率和召回率。通常,我们会寻找曲线最靠近右上角的点,因为这意味着在该阈值下,模型达到了较高的精确率和召回率。
PR_curve分析
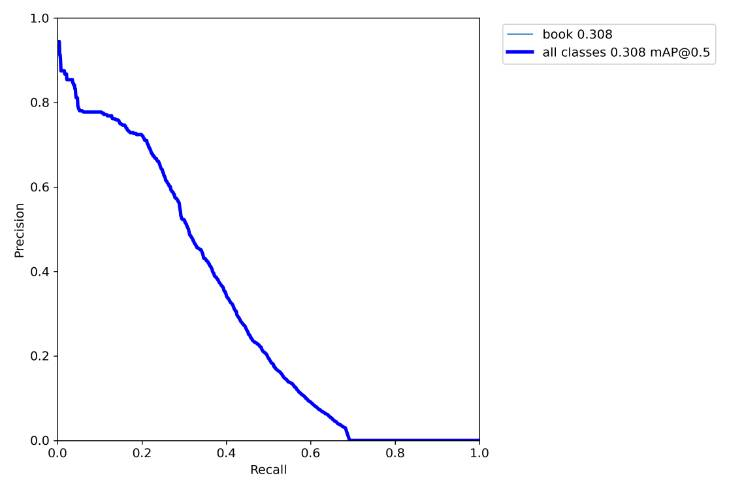
根据您上传的精确率-召回率曲线图,这张图表展示了一个对象检测模型在识别“书本”类别时的性能,其中平均精度均值(mAP)为0.308,在IoU=0.5的情况下。
这个曲线图显示了模型在对象检测方面的中等表现,特别是在识别书本时,提供了模型有效性和改进空间的洞察。在理想情况下,我们希望精确率和召回率曲线都能接近图表的右上角,这意味着模型在保持高召回率的同时也具有高精确率。
在您的模型中,mAP值为0.308表明模型在识别书本时具有一定的准确性,但仍有提升空间。IoU(交并比)值为0.5是评估对象检测模型性能的一个常用标准,mAP值越高,模型的性能通常被认为越好。