
前言
模型训练的精度到不到标准,重新来过
分析
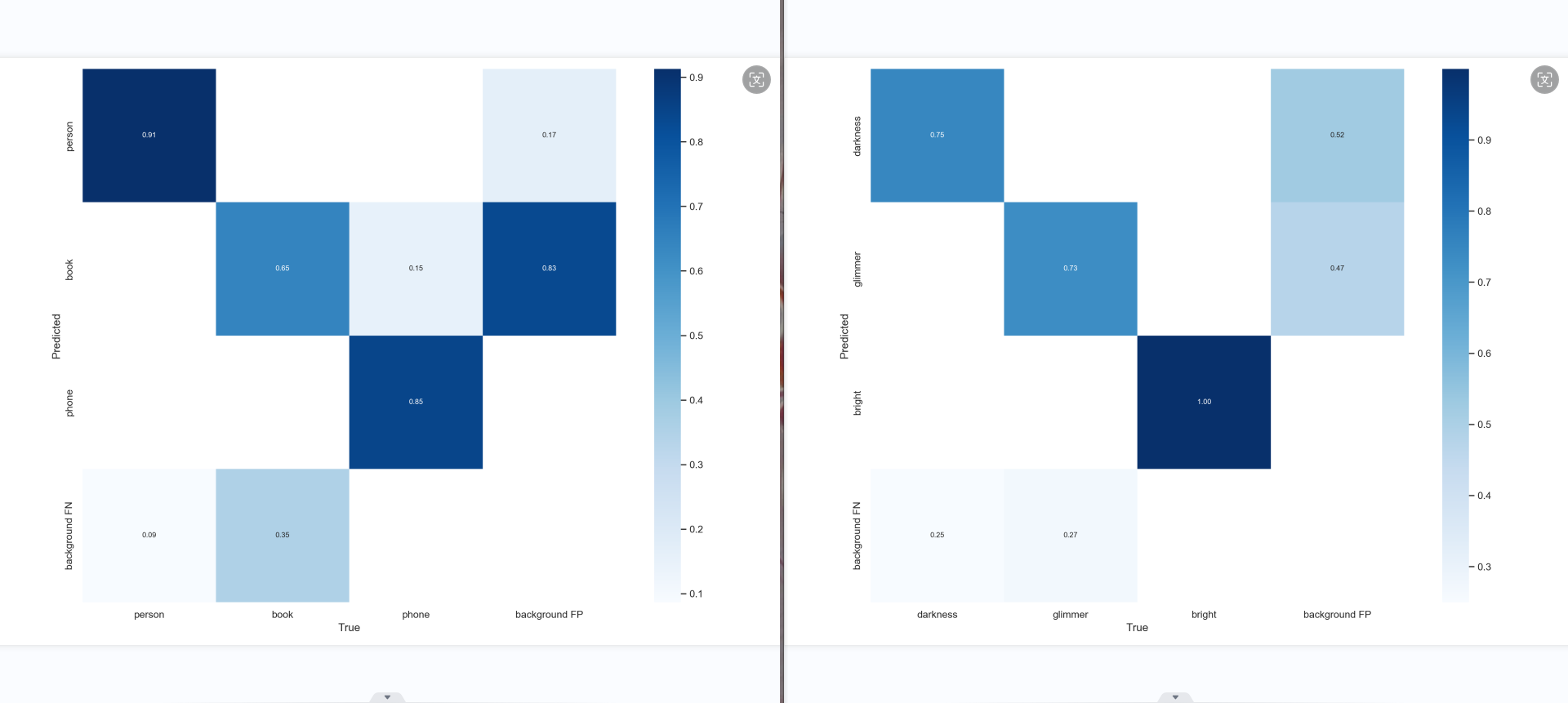
 图中包含“黑暗”、“微光”、“光亮”和“background FP”的类别标签。从图中可以看出,模型在识别“黑暗”和“光亮”方面的性能较好,准确率分别为0.91和0.87。但在识别“微光”的能力较弱,准确率仅为0.36。同时,“background FP”的值也相对较高,表示模型可能将一些背景误分类,其值较高,需要进一步优化。
图中包含“黑暗”、“微光”、“光亮”和“background FP”的类别标签。从图中可以看出,模型在识别“黑暗”和“光亮”方面的性能较好,准确率分别为0.91和0.87。但在识别“微光”的能力较弱,准确率仅为0.36。同时,“background FP”的值也相对较高,表示模型可能将一些背景误分类,其值较高,需要进一步优化。 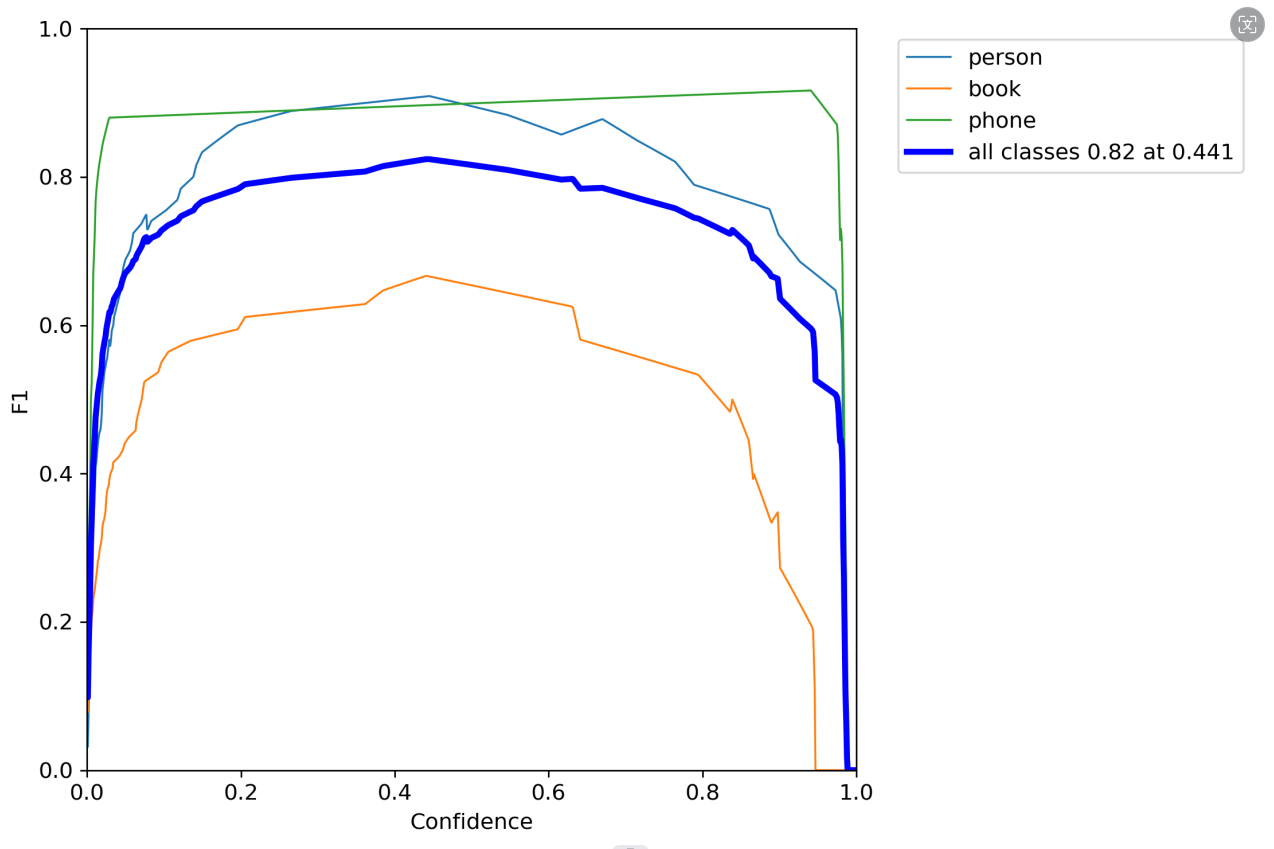 图中包含“黑暗”、“微光”、“光亮”和“background FP”的类别标签。从图中可以看出“黑暗”和“光亮”的识别性能较好,F1得分接近0.8,这意味着模型在这两个类别上的精确度和召回率都相对较高。相比之下,“微光”的识别性能较差,F1得分大约为0.6,表明模型在识别书本时可能会有更多的误判或漏判。所有类别的最大F1值为0.82,当置信度为0.441时达到这一峰值。这表明,提高模型的整体性能可能需要对书本类别的识别能力进行改进。
图中包含“黑暗”、“微光”、“光亮”和“background FP”的类别标签。从图中可以看出“黑暗”和“光亮”的识别性能较好,F1得分接近0.8,这意味着模型在这两个类别上的精确度和召回率都相对较高。相比之下,“微光”的识别性能较差,F1得分大约为0.6,表明模型在识别书本时可能会有更多的误判或漏判。所有类别的最大F1值为0.82,当置信度为0.441时达到这一峰值。这表明,提高模型的整体性能可能需要对书本类别的识别能力进行改进。 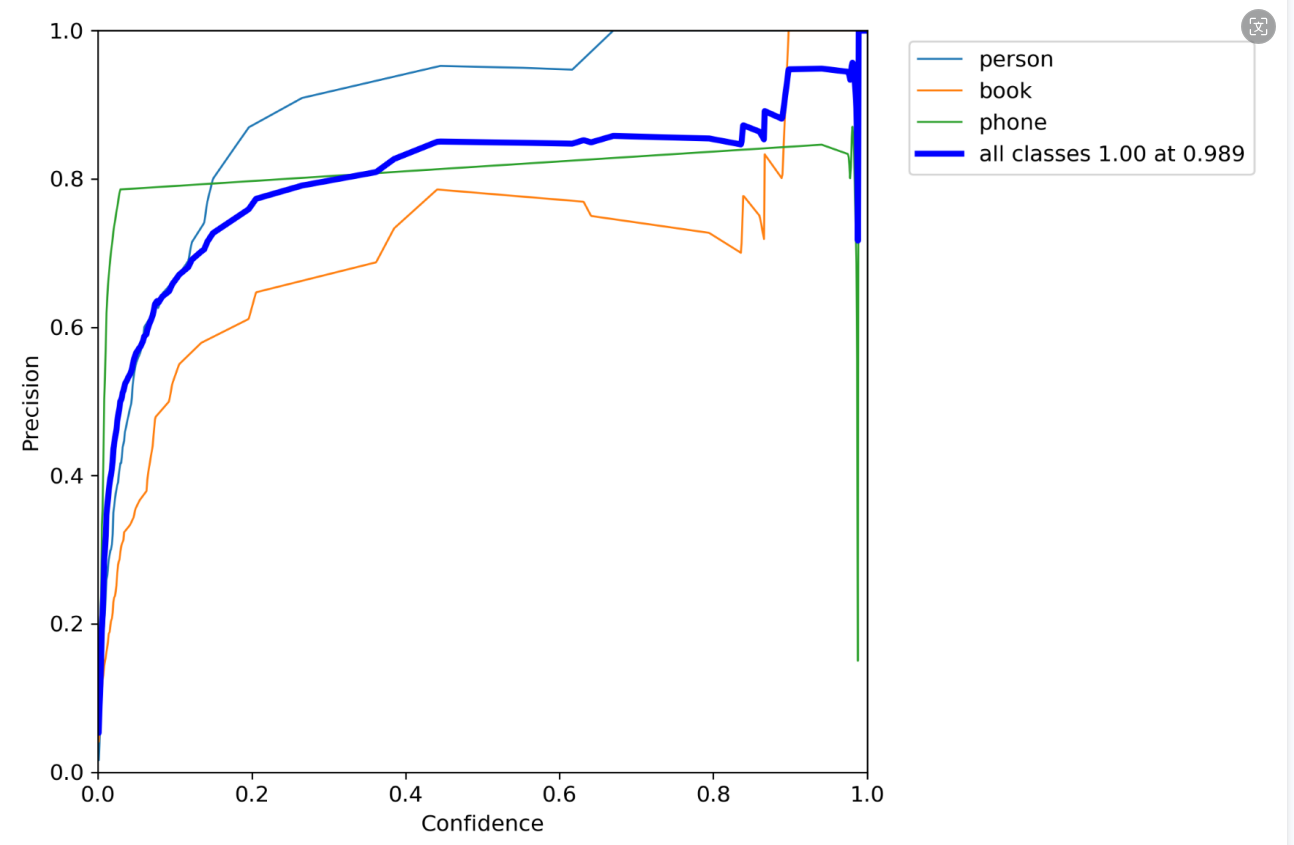
,从P-R曲线图像可以看出,“黑暗”类别的识别性能相当好,精确度在大多数置信度水平上都保持在0.8以上,这表明模型对于“黑暗”的检测非常可靠。“微光”类别的识别性能也不错,但是在某些置信度水平上略低于人物类别,可能需要进一步优化以提高精确度。“光亮”类别的识别性能较差,即使在高置信度下,其精确度也明显低于其他两个类别,这可能意味着模型在识别“光亮”方面需要显著改进。
 ,根据PR_curve.png图像,“黑暗”类别的准确率最高,大约为0.910 ,这表明模型在识别人物方面表现出色。“光亮”类别的准确率为0.861,也显示出了不错的识别能力。相比之下,“微光”类别的准确率只有0.523,这是三个类别中最低的,表明模型在识别书籍方面可能需要进一步的优化。所有类别综合起来的平均准确率(mAP@0.5)为0.765,这是一个中等水平的结果。
,根据PR_curve.png图像,“黑暗”类别的准确率最高,大约为0.910 ,这表明模型在识别人物方面表现出色。“光亮”类别的准确率为0.861,也显示出了不错的识别能力。相比之下,“微光”类别的准确率只有0.523,这是三个类别中最低的,表明模型在识别书籍方面可能需要进一步的优化。所有类别综合起来的平均准确率(mAP@0.5)为0.765,这是一个中等水平的结果。
总结:黑暗和光明比较容易识别,但微光的不够。特征不够敏感明显。
微光这个标签的出现缘由是因为有光线,能看清楚东西,可以玩手机看书,但会损伤视力健康。
而光明则是不会损伤视力健康。所以微光的界定范围应该是小于黑暗,并且小于整体图片的二分之一。
环境状态模型
发现黑暗、微光容易与背景相混淆。
部分的黑暗被归纳进了背景当中,所谓背景,就是不明亮的环境,这包括了没有被标注到的黑暗,较弱的微光。
若是黑暗黑嘚不够纯粹,微光特征不够明显,标注的时候没有完全的囊括,就会自动归类与背景,减小了精确性。
所以数据集,黑暗要足够的黑,微光标准的点要足够的的亮,且界限分明,不那么容易归类到背景当中。
定义:
黑:黑暗(纯粹)
光亮:明亮(多) + 亮(多) + 微亮(少)
微光:明亮(要多) + 亮(要多) + 微亮(要少)+ 微暗(少)+暗(少)
背景:黑暗(要少) + 微暗(要多)+微微亮(要多),这样黑暗才不那么容易被认为为背景
三个标签:
光亮:明亮(多) + 亮(多) + 微亮(少) 微光:明亮(要多) + 亮(要多) + 微亮(要少) 背景:纯暗(要多)+ 黑暗(要多)+ 微暗(要多)+ 微亮(要多)
训练除了3个成果,第二次的比较成果
修正第二次的数据集,方向: 黑暗数据集:纯黑,黑,微暗(少) 背景:微亮(多)、微暗(多)、灰 微光:明亮、亮、微亮(少)
书本手机模型
模型1
模型2
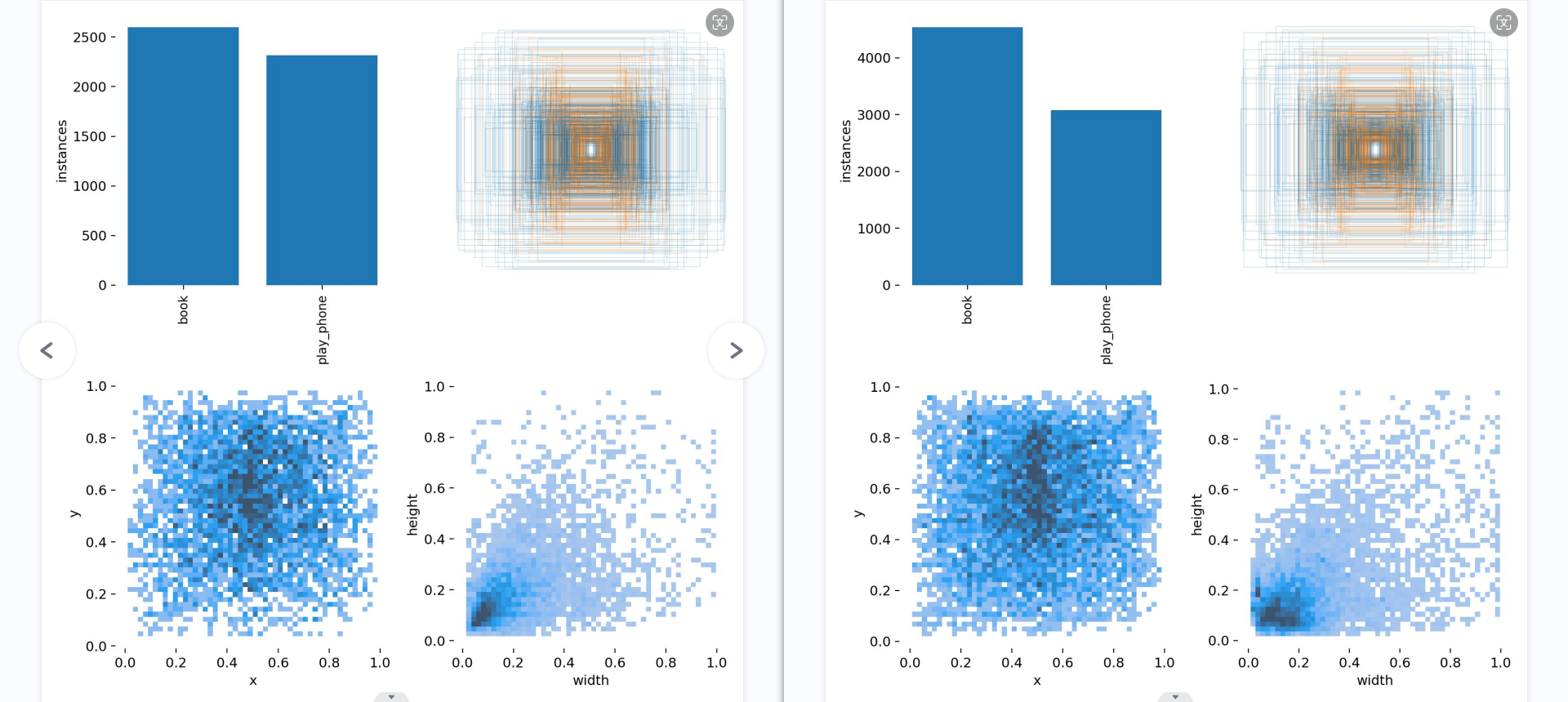
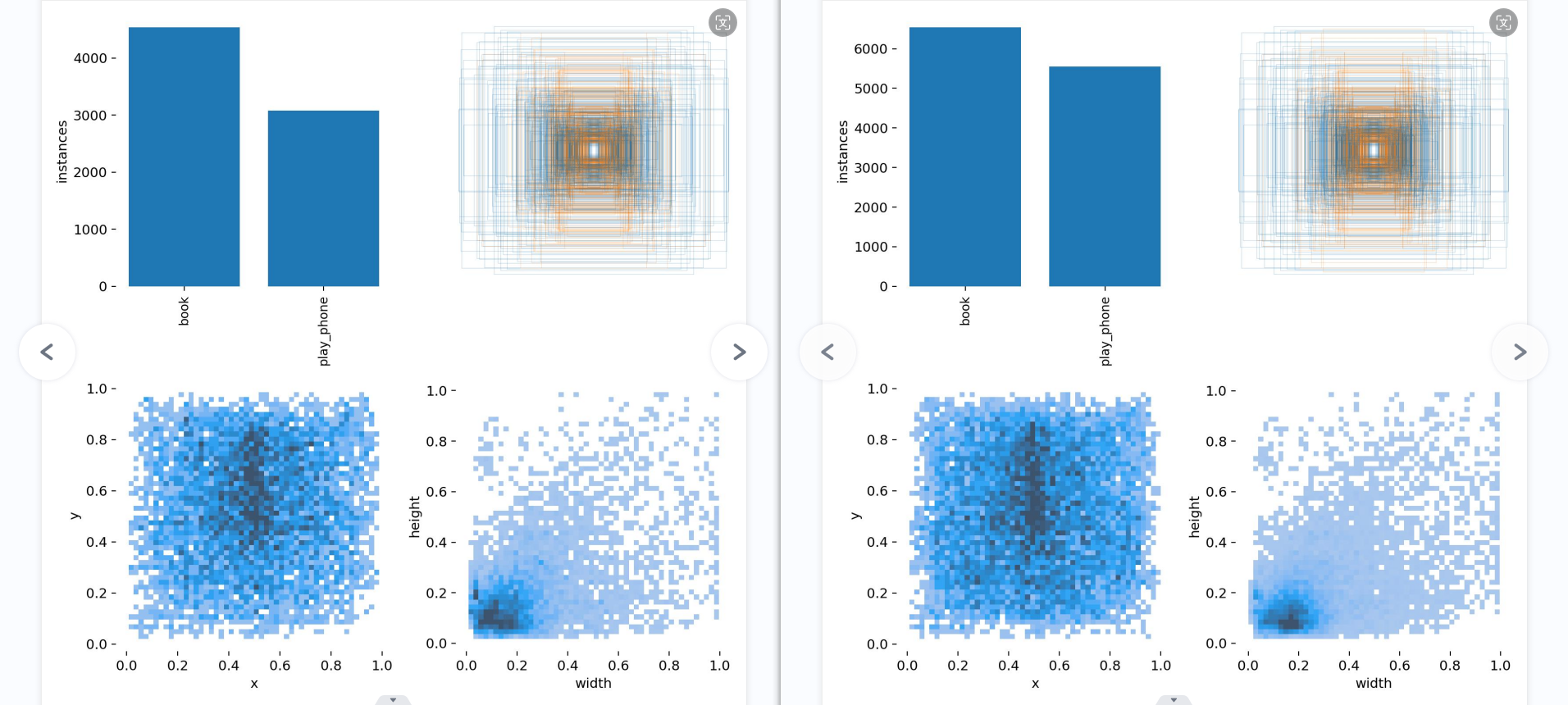
这些图表显示了用于检测”书本”和”使用手机”两个类别的YOLOv5-lite模型的性能。让我逐一分析每个图表:
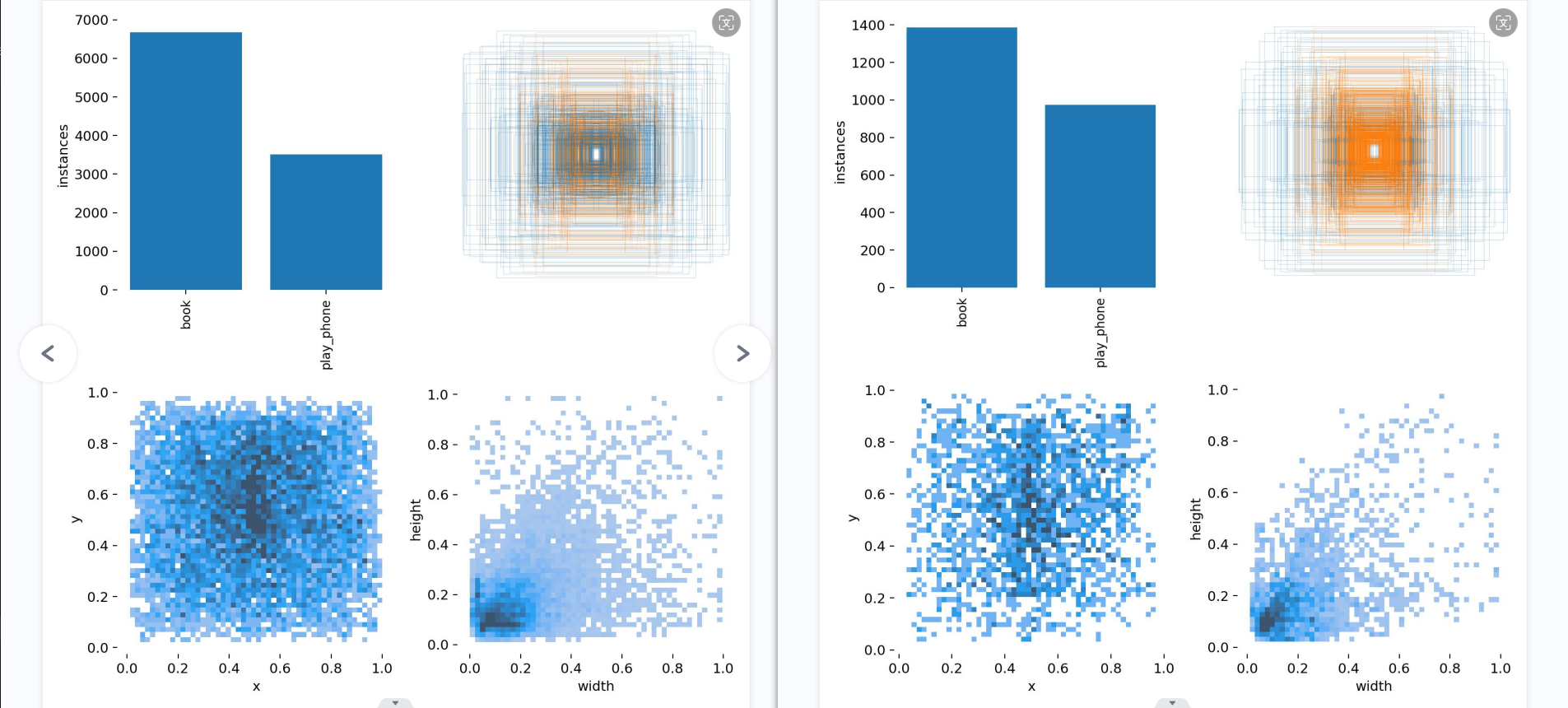
第一张图显示了每个类别的预测得分分布。”书本”类别的大部分得分集中在较高的0.56左右,而”使用手机”类别大部分得分集中在较高的0.81左右。但也有一小部分低分数实例。
1
2
3
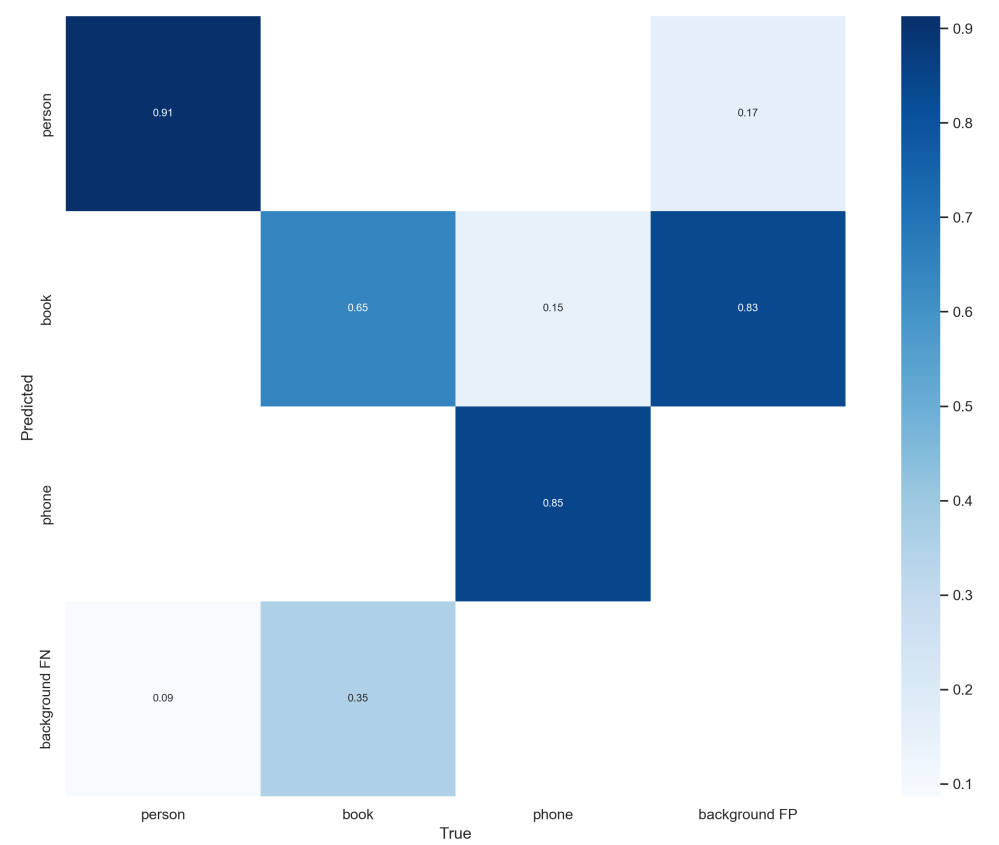
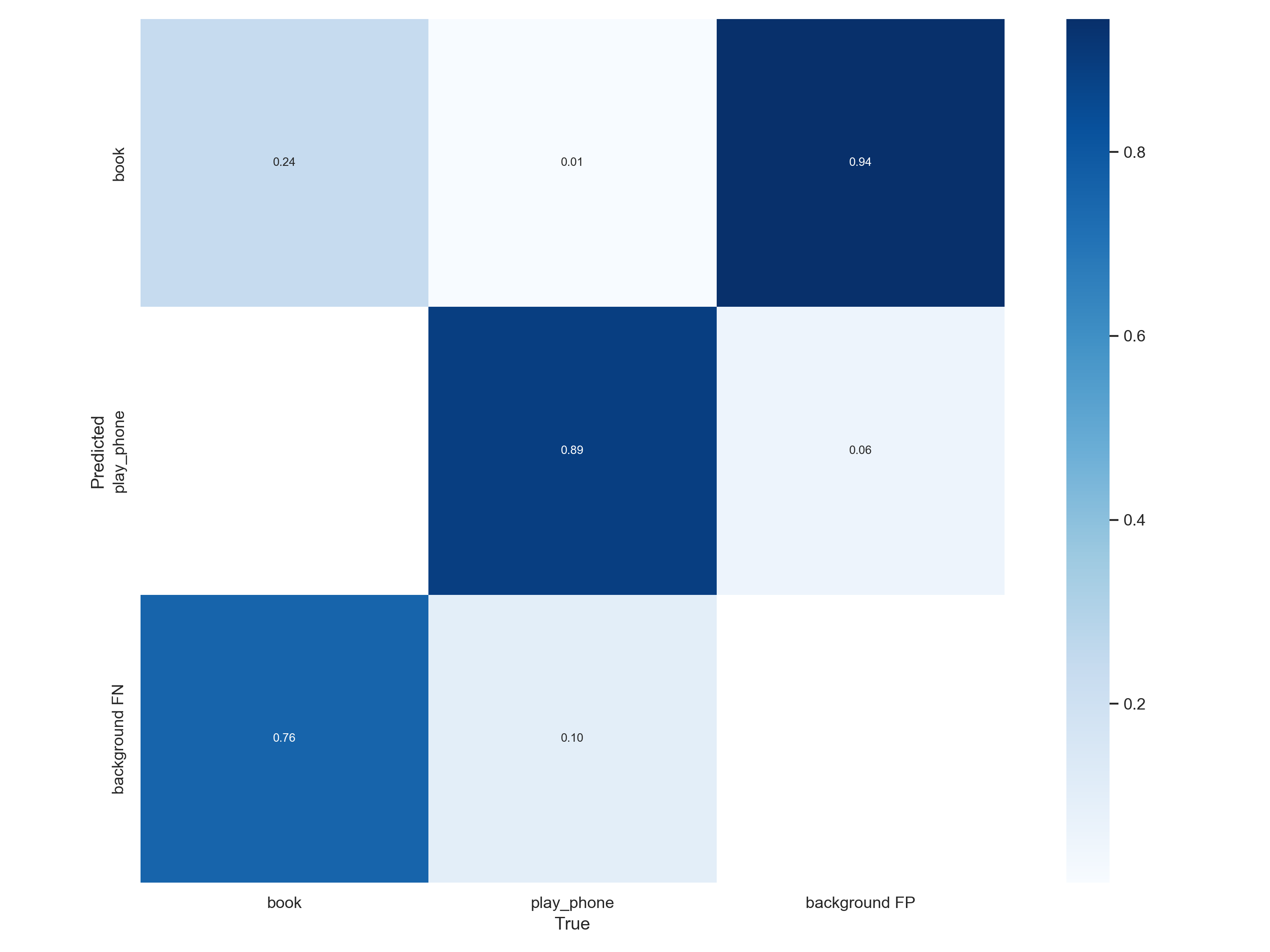
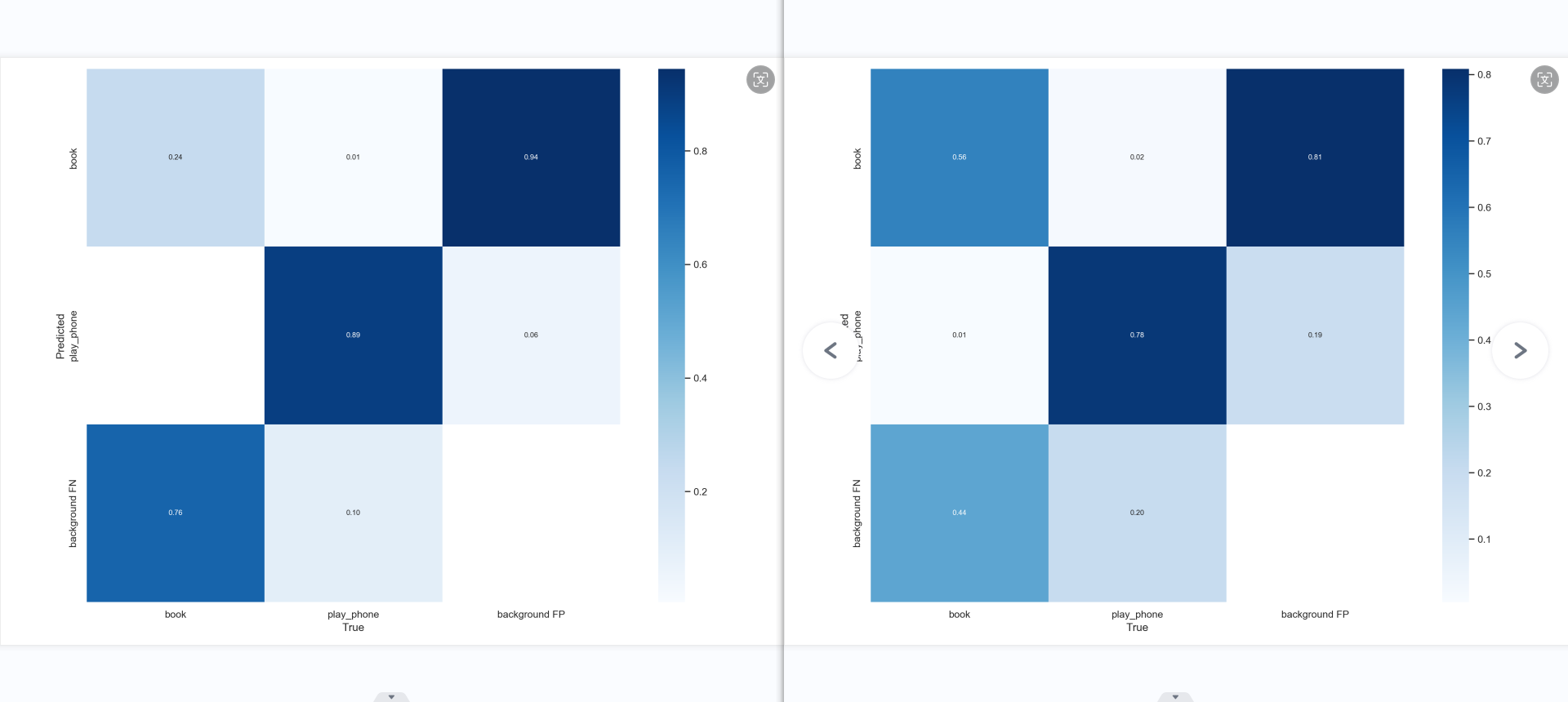
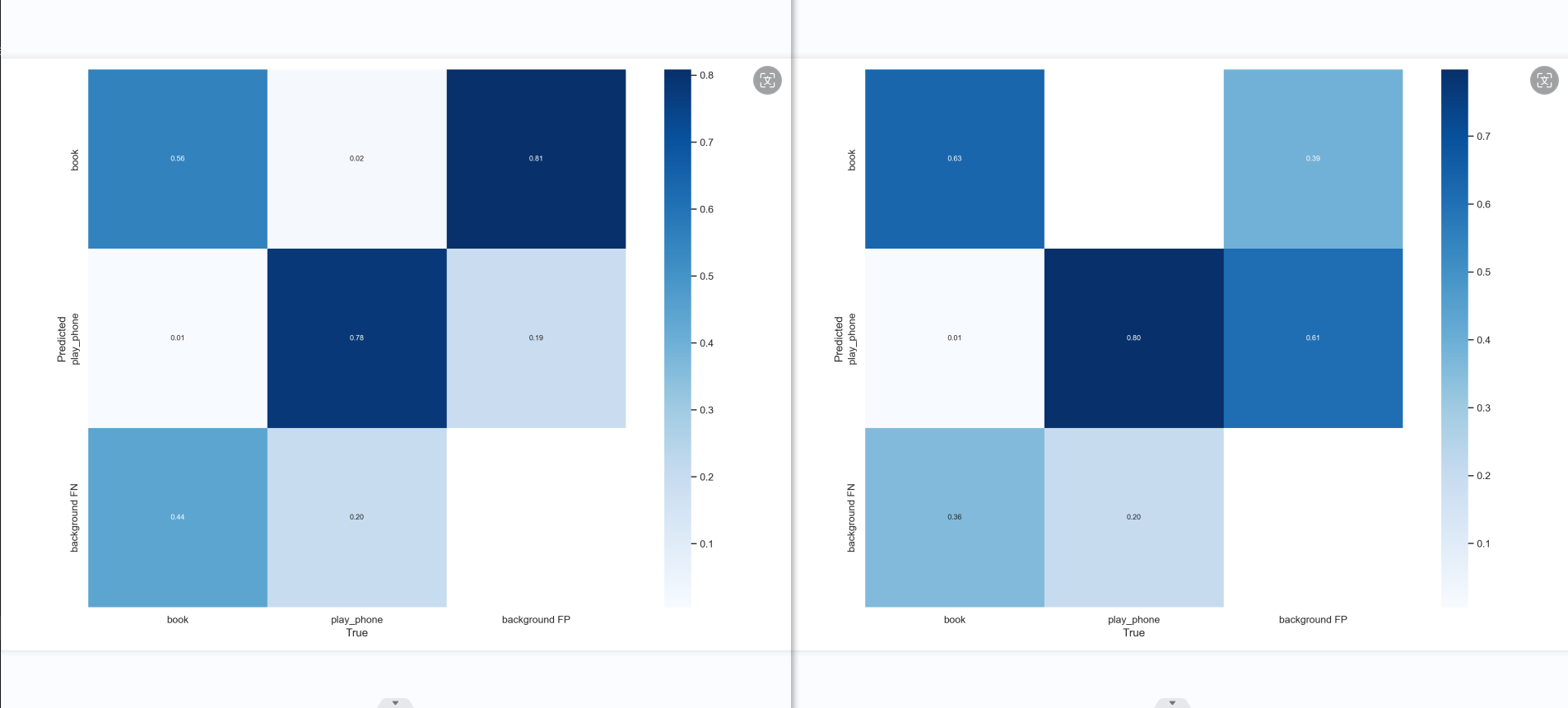
ps:confusion_matrix
混淆矩阵的每一列代表了预测类别,每一行是预测类别。每一列是真实类别。
矩阵中Aij的含义是:第j个类别被预测为第i个类别的概率。
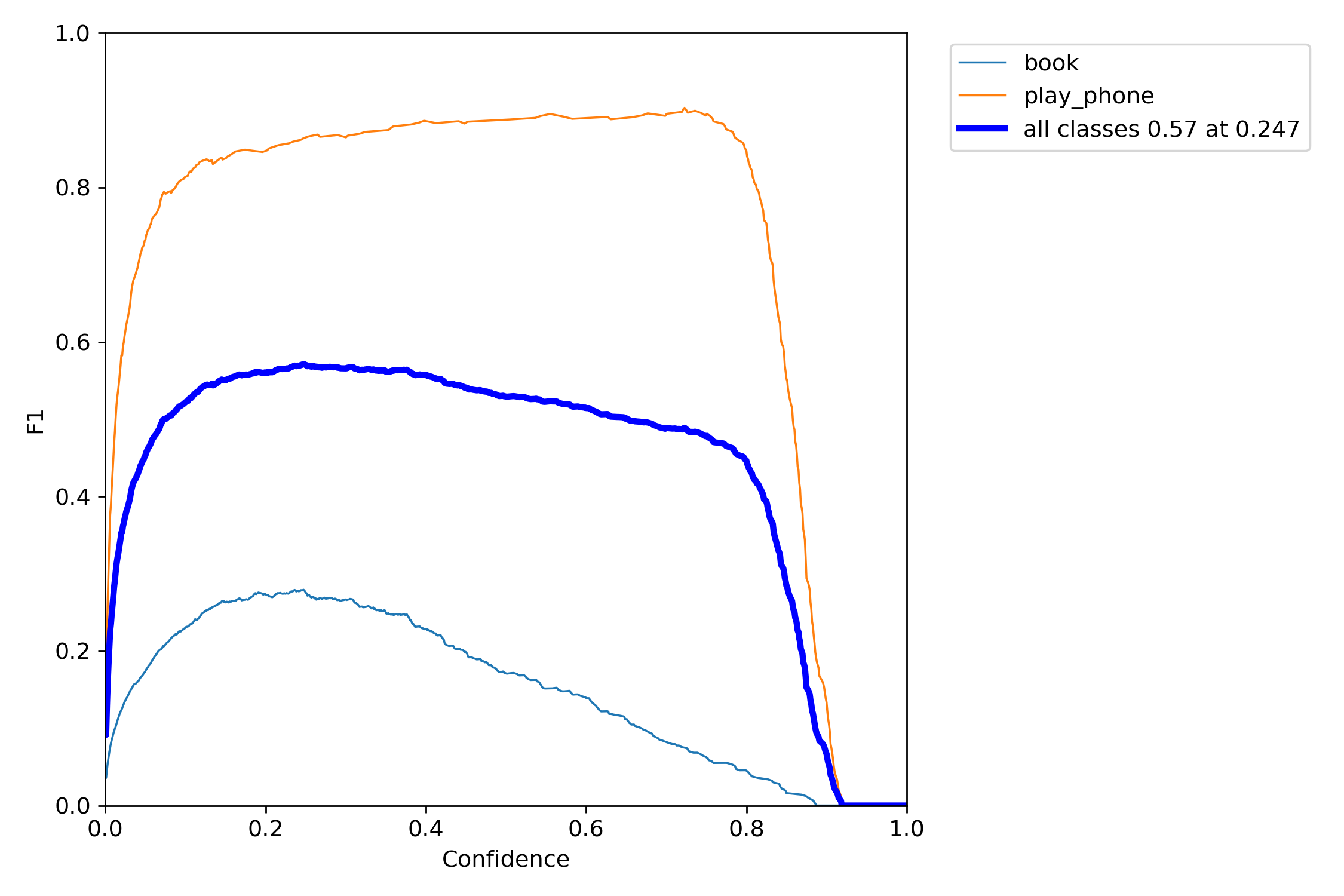
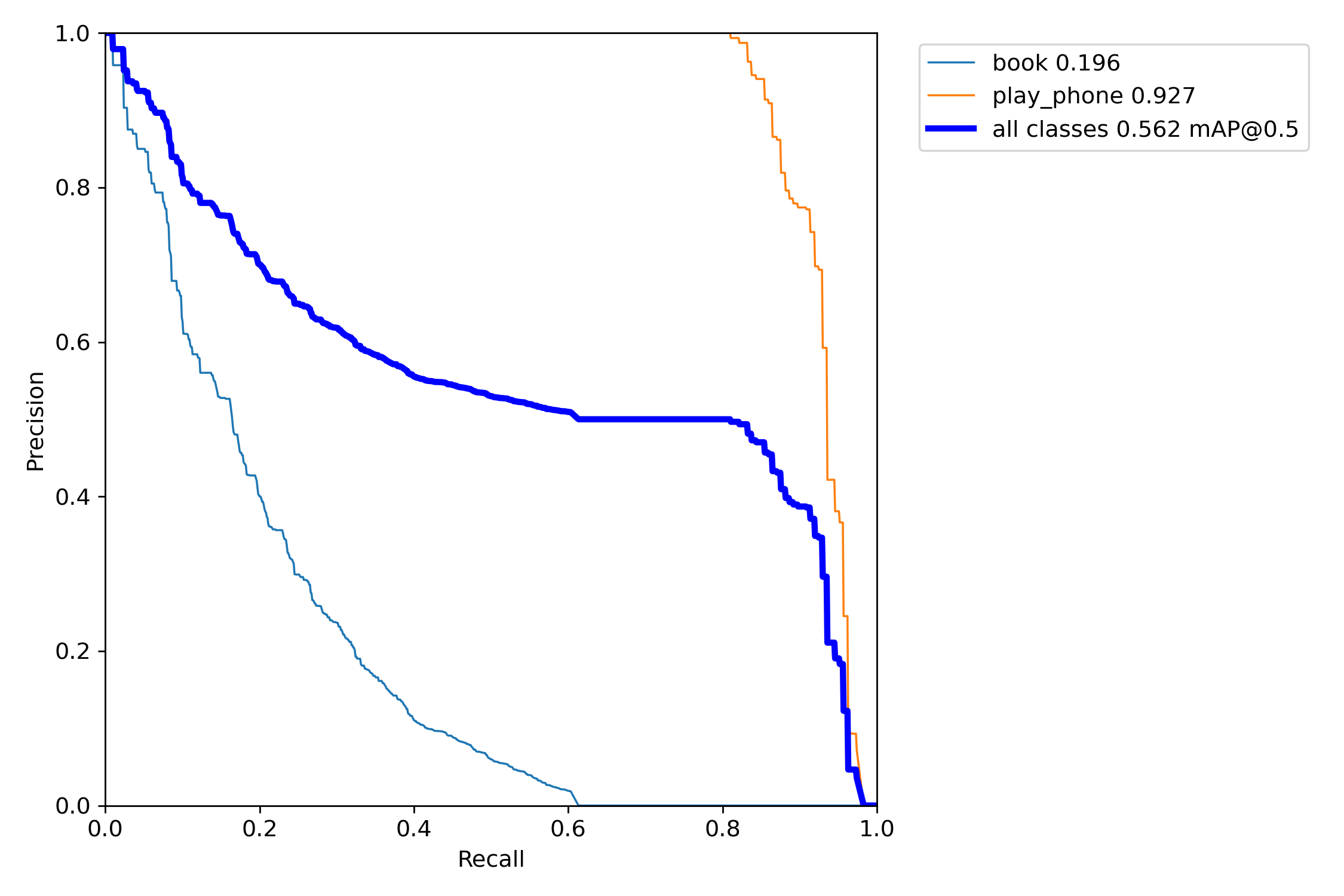
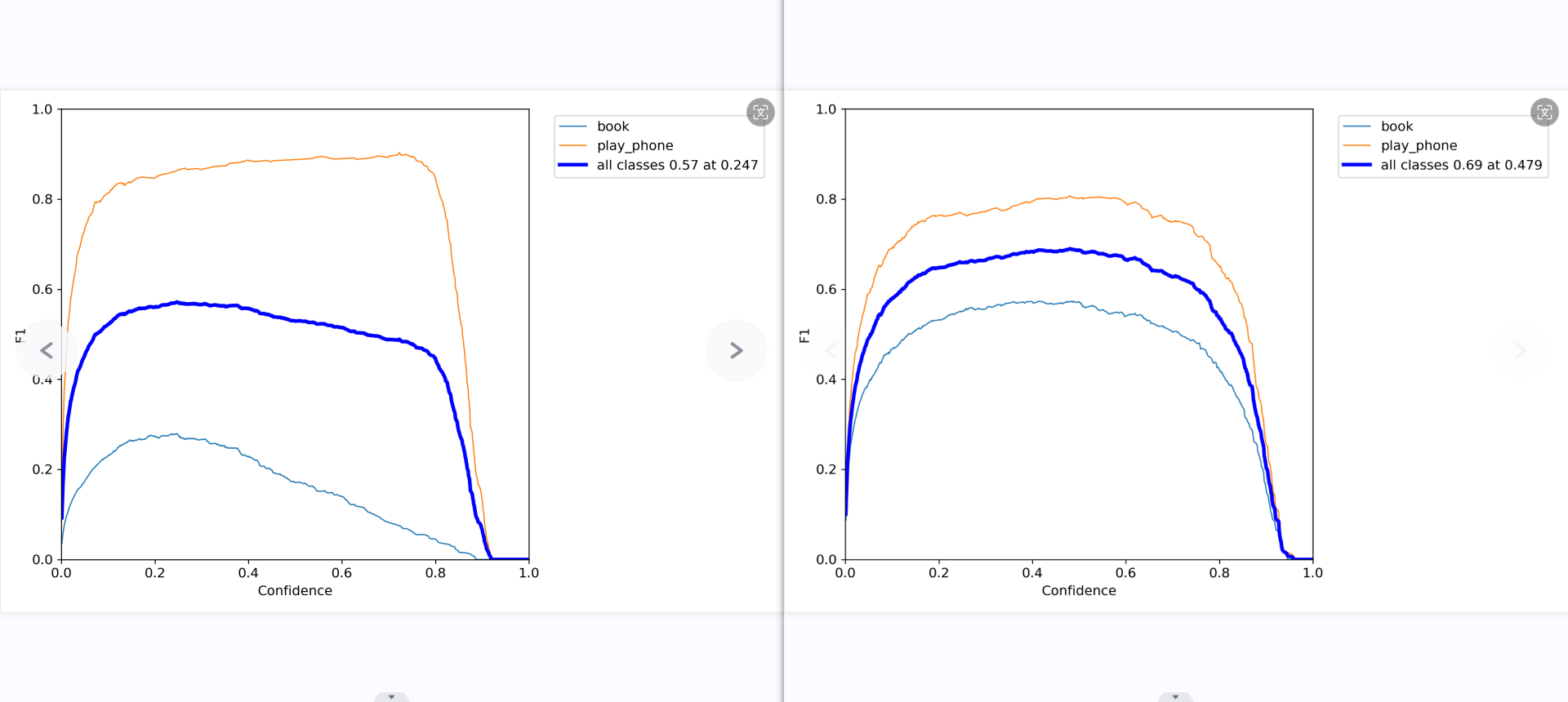
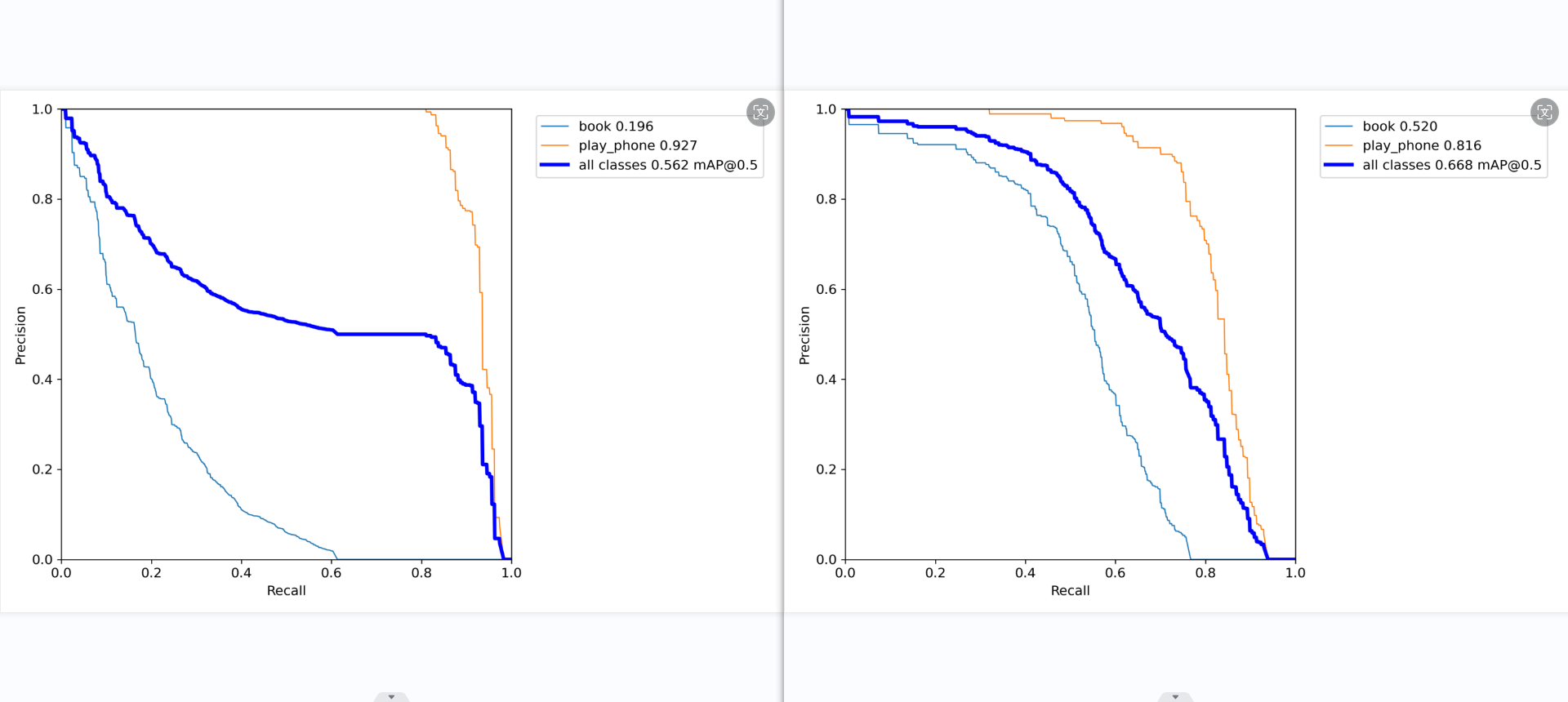
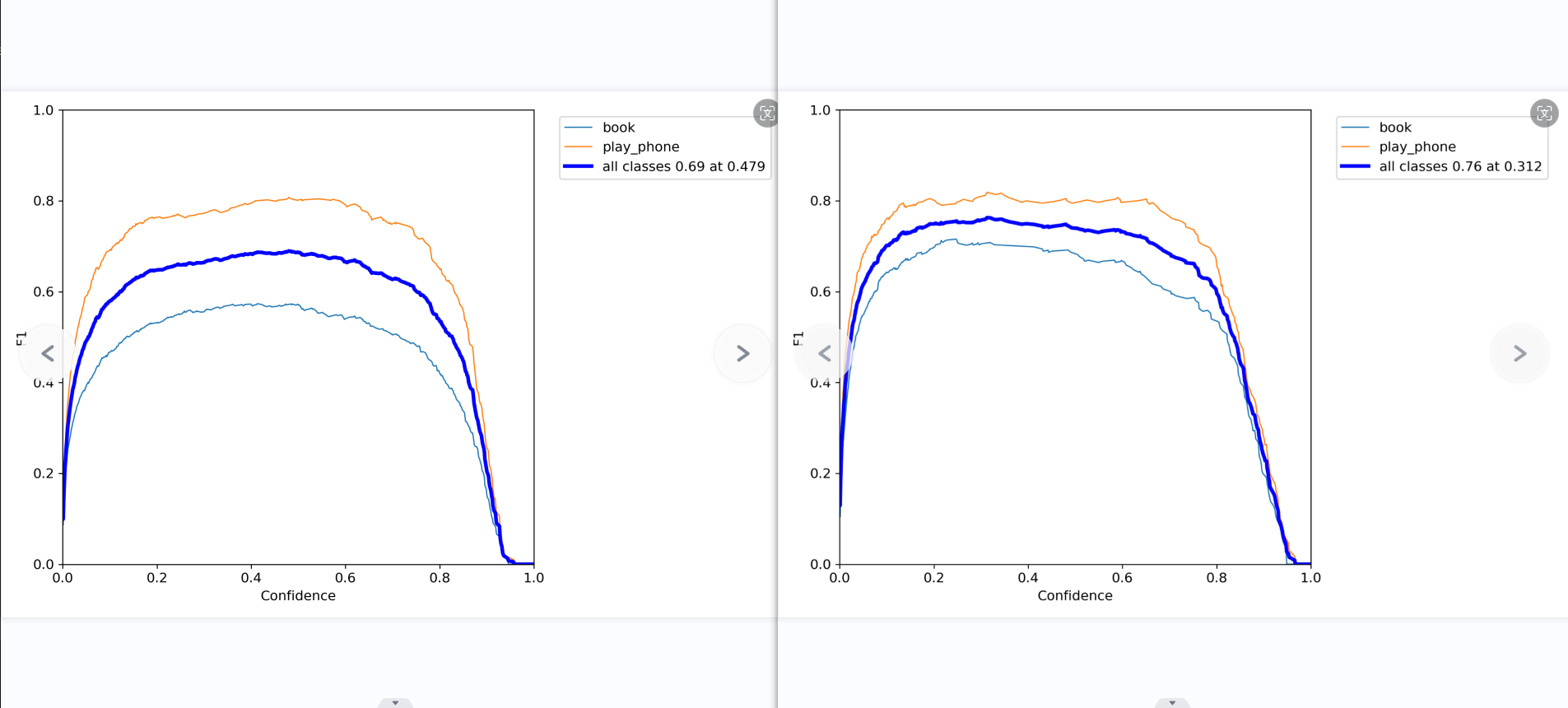
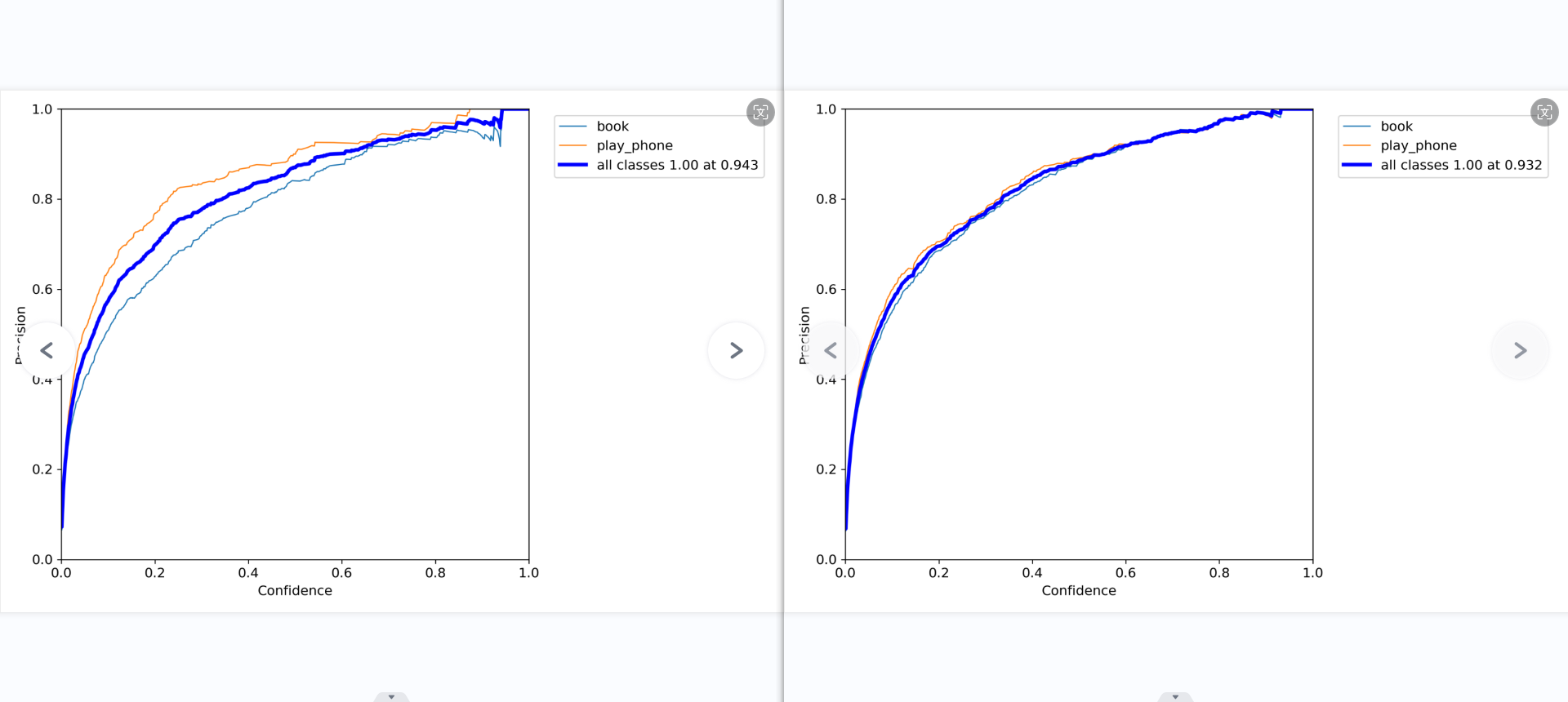
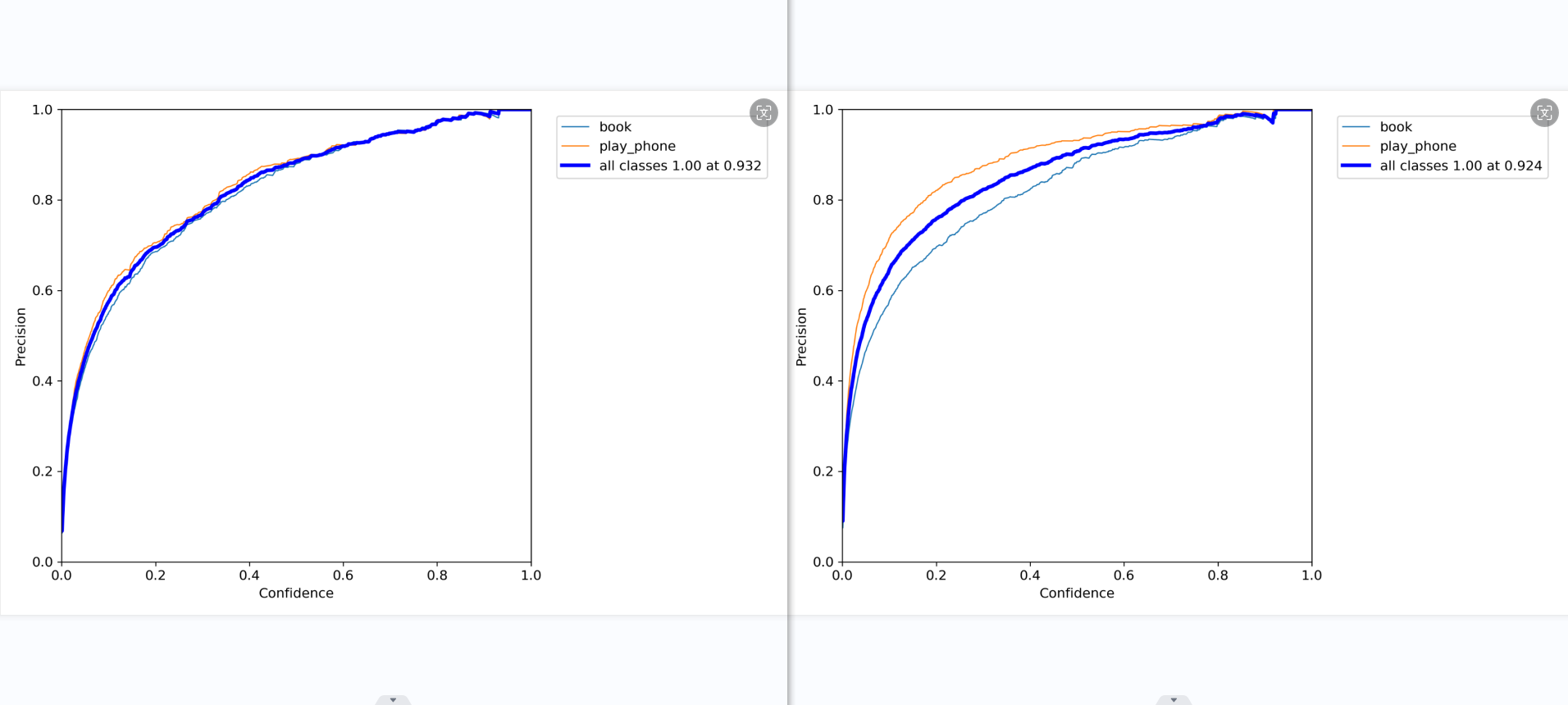
第二张图是精确率-召回率曲线。对于较高的置信度阈值(右侧),”书本”类别的精确率较高,而”使用手机”类别的召回率较高。随着阈值降低,两个类别的精确率和召回率都有所提高,但”使用手机”类别的提升更大。在0.479处取得两类别的最佳平衡F1值0.69。
1
2
3
ps:F1_curve
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
对于某个分类,综合了Precision和Recall的一个判断指标,F1-Score的值是从0到1的,1是最好,0是最差。
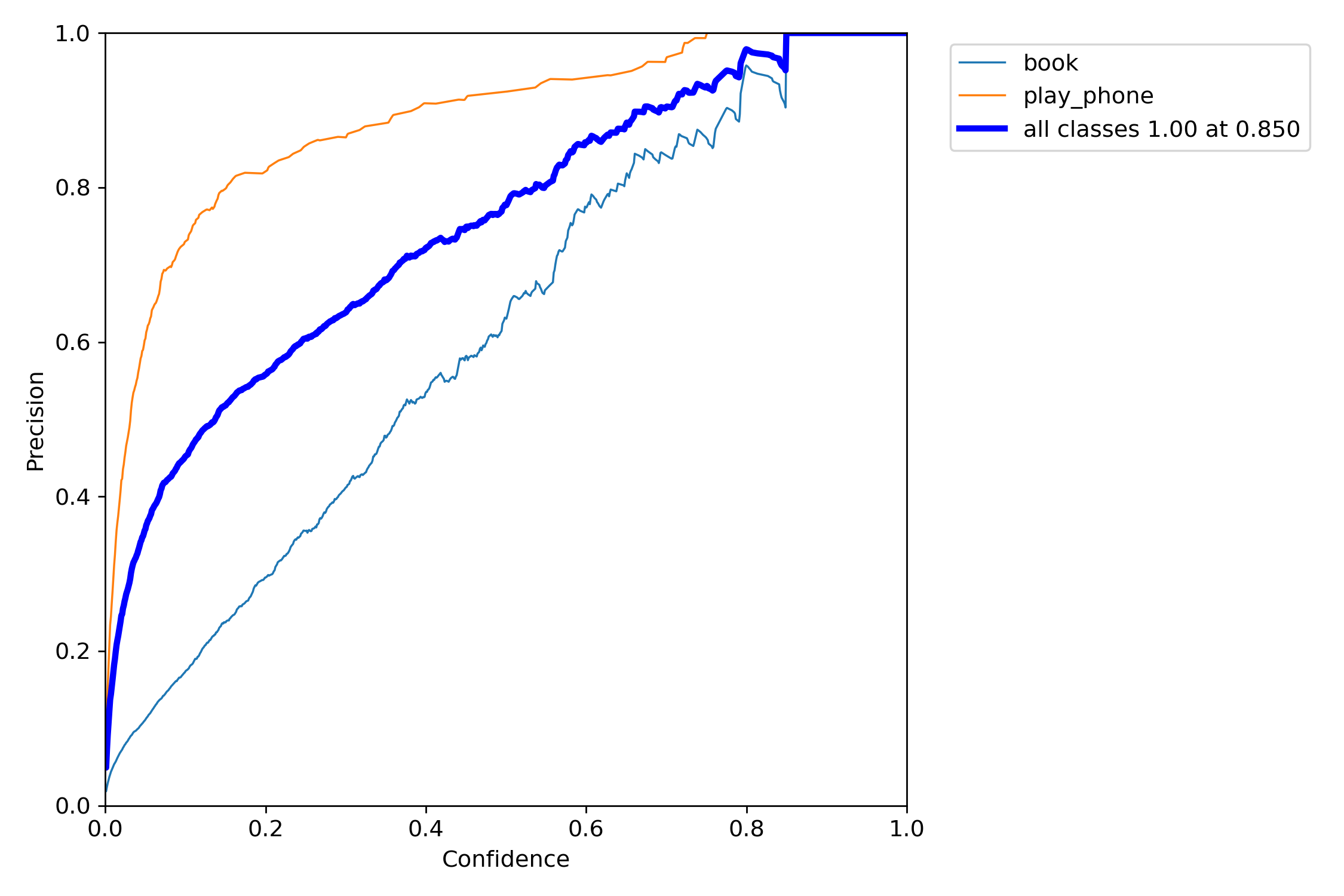
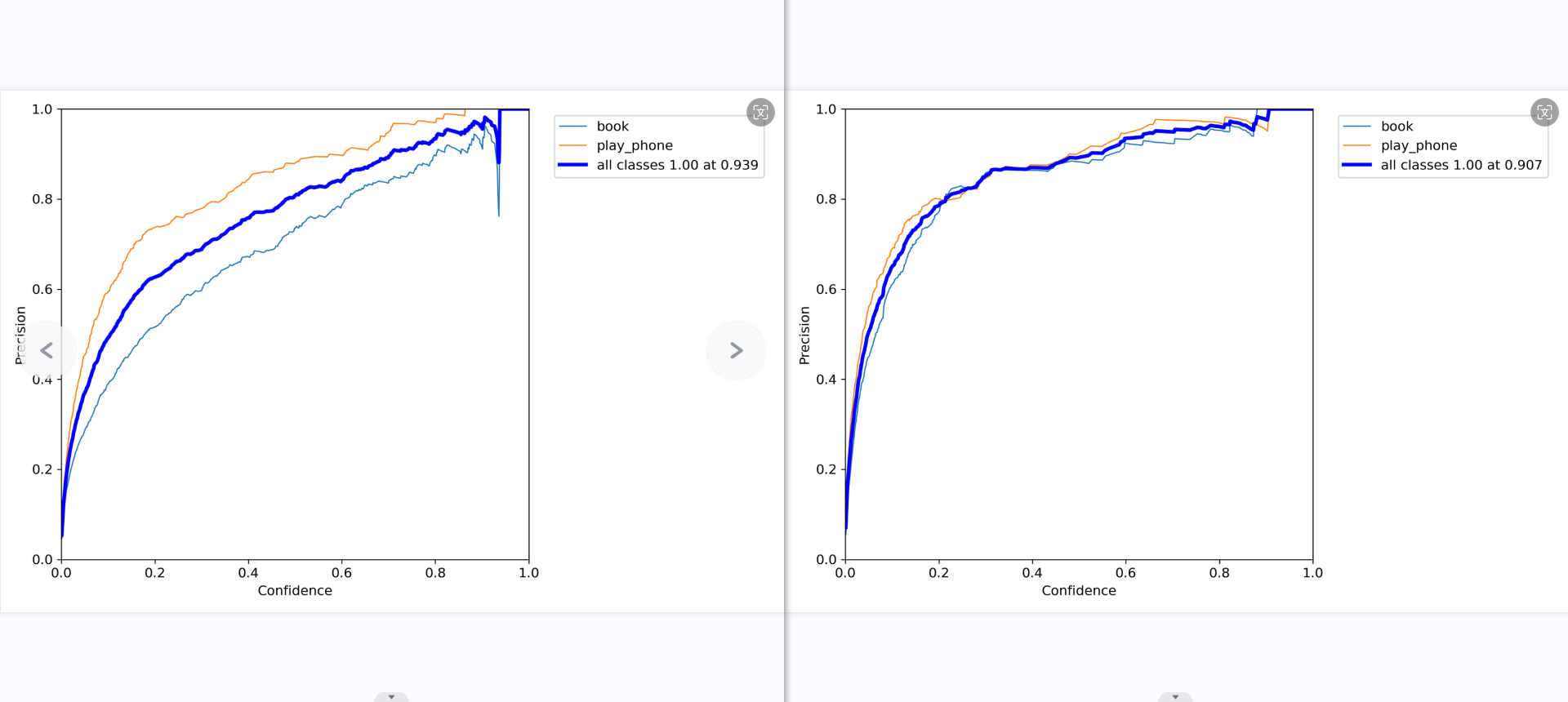
第三张图是精确率-召回率曲线的另一视角。可以看到对于较高的召回率区间,”使用手机”类的精确率明显高于”书本”类。
1
2
3
ps:P_curve
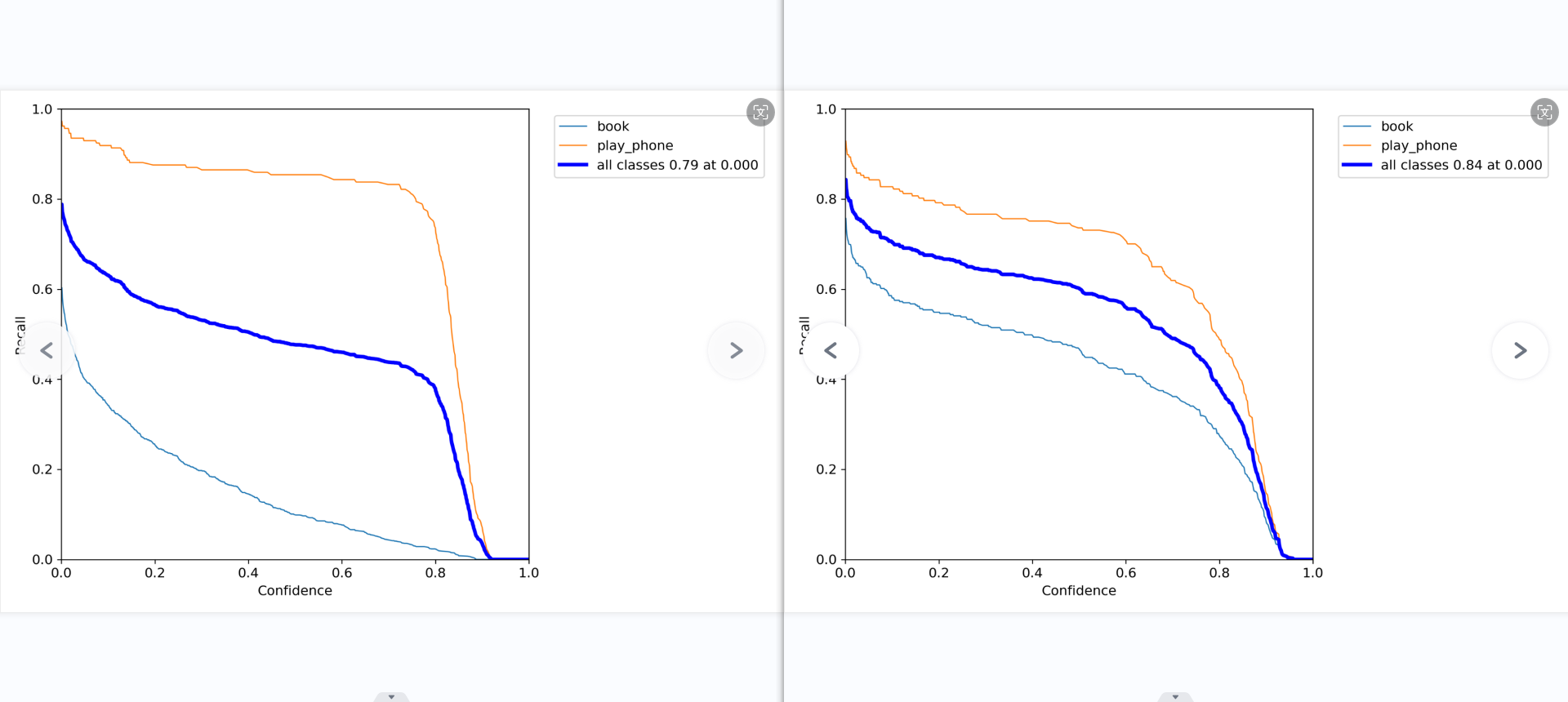
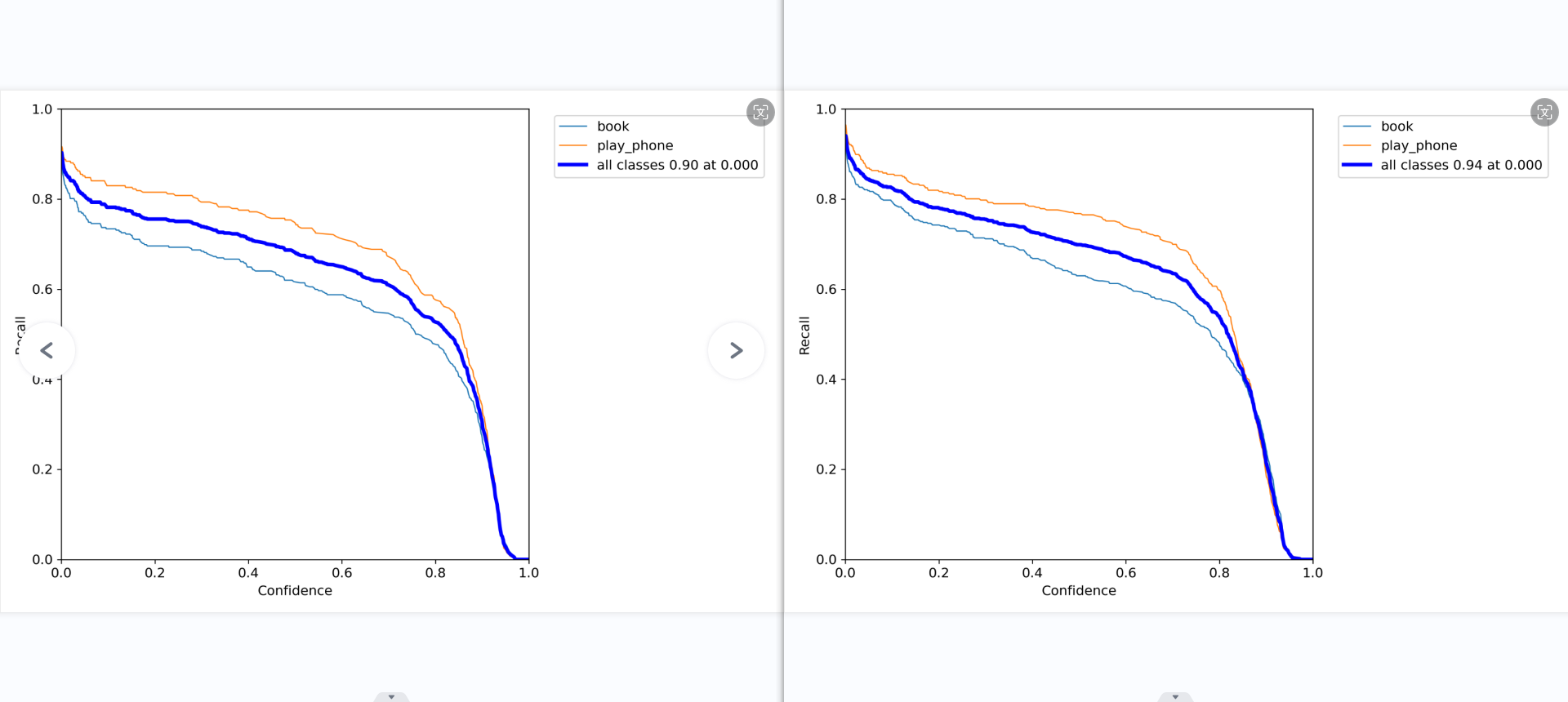
准确率和置信度的关系图。
意思就是,当我设置置信度为某一数值的时候,各个类别识别的准确率。可以看到,当置信度越大的时候,类别检测的越准确。这也很好理解,只有confidence很大,才被判断是某一类别。但置信度阈值过高,可能会导致掉那些忽略信度低,但确实有该物品的图像。
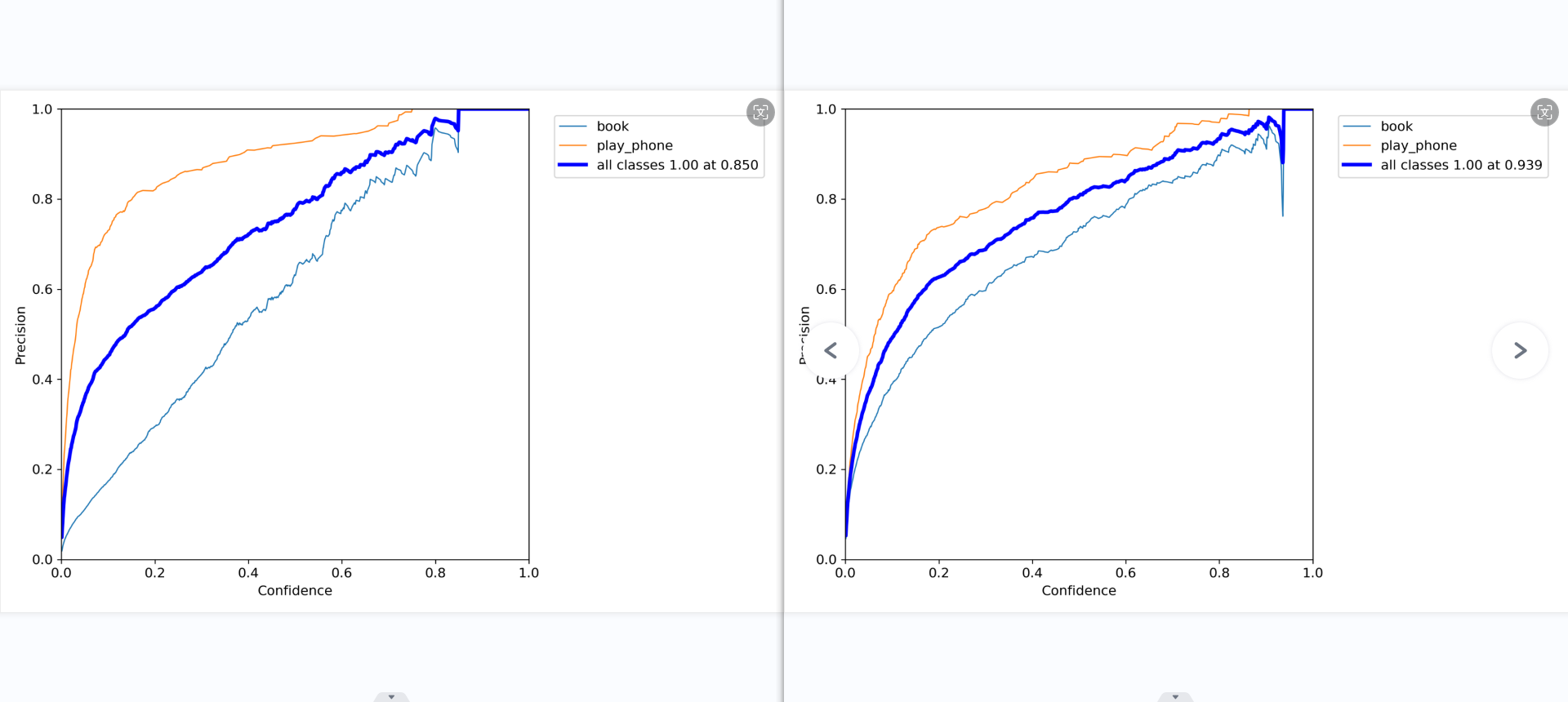
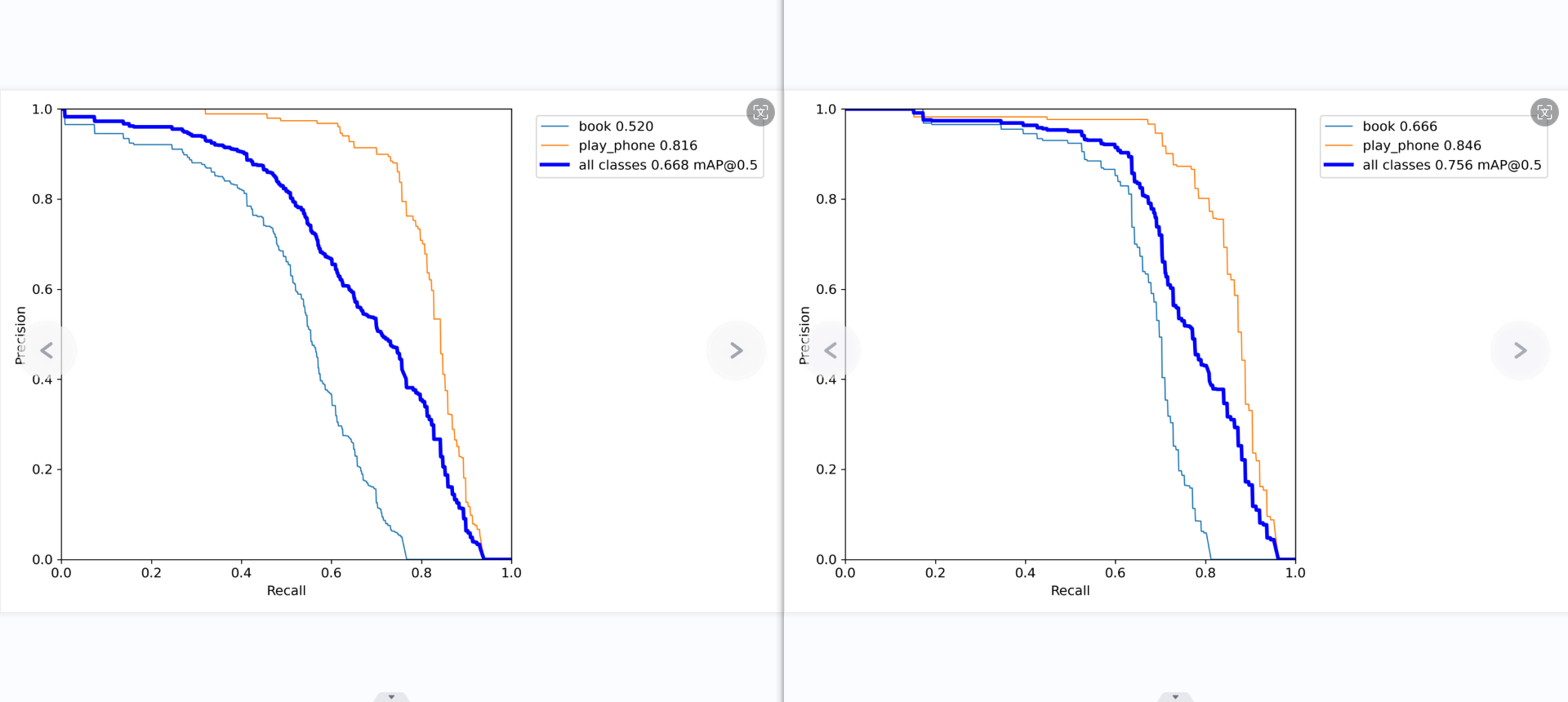
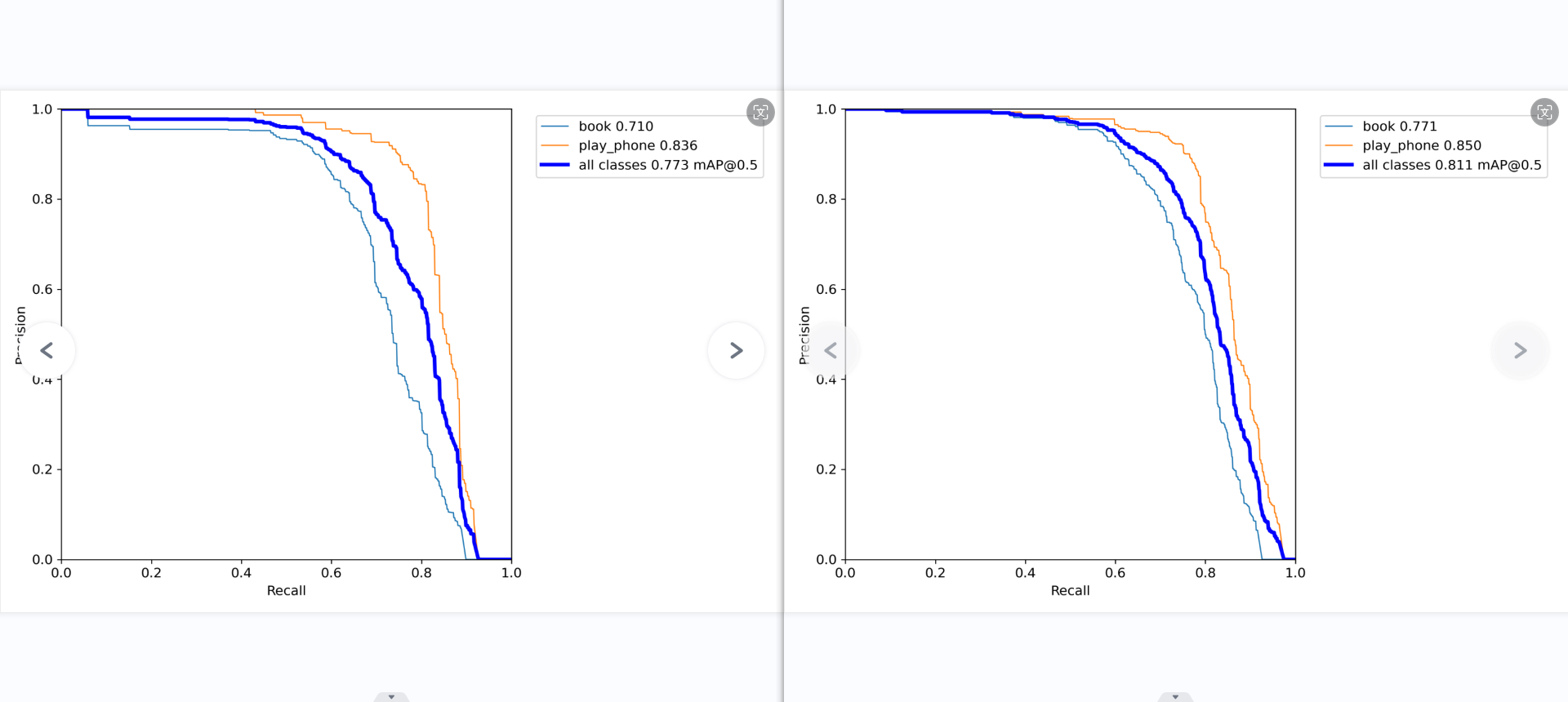
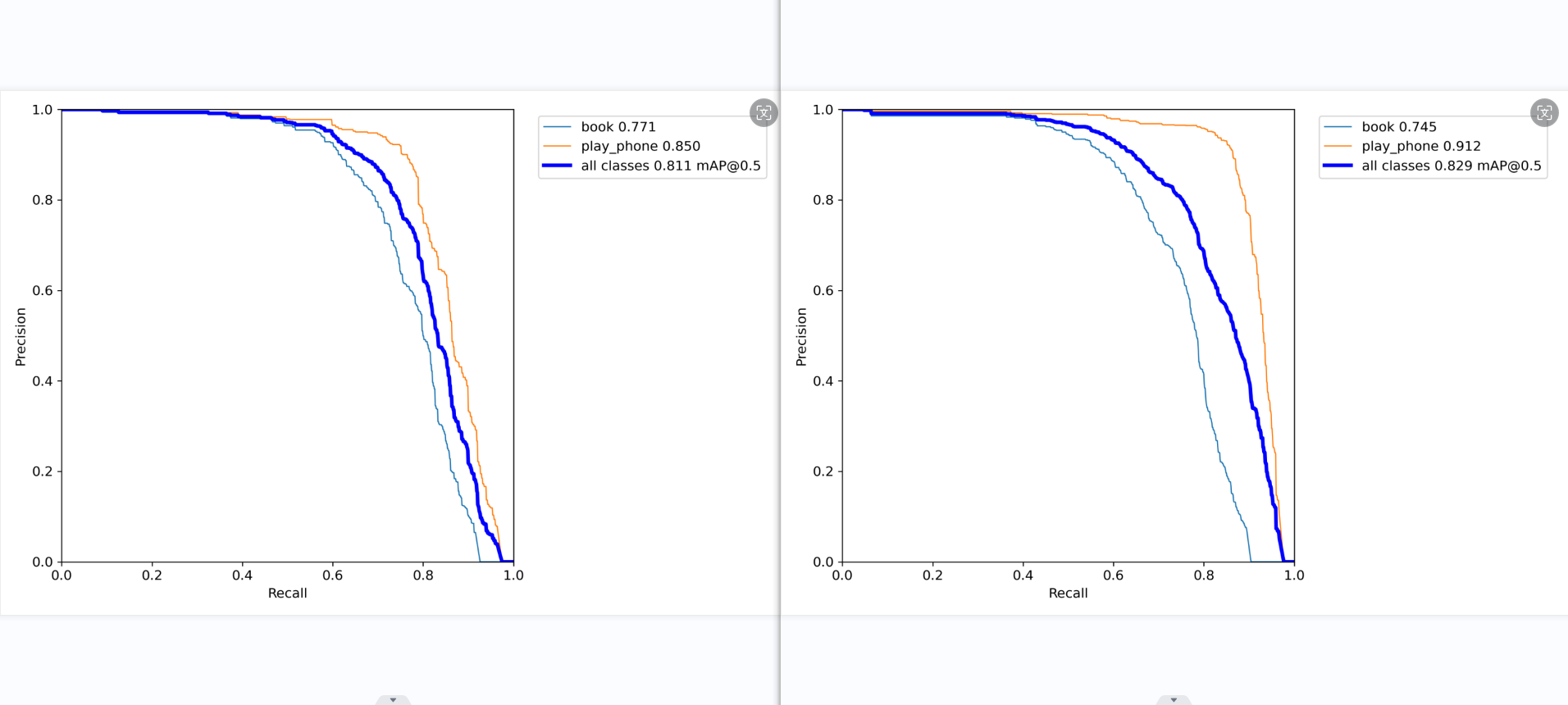
第四张图展示了模型在不同置信度阈值下平均精确率(mAP)与召回率的关系。在较高召回率区间内,”使用手机”类的表现优于”书本”类。平衡点(mAP@0.5=0.668)处,”使用手机”的召回率明显高于”书本”类。
1
2
3
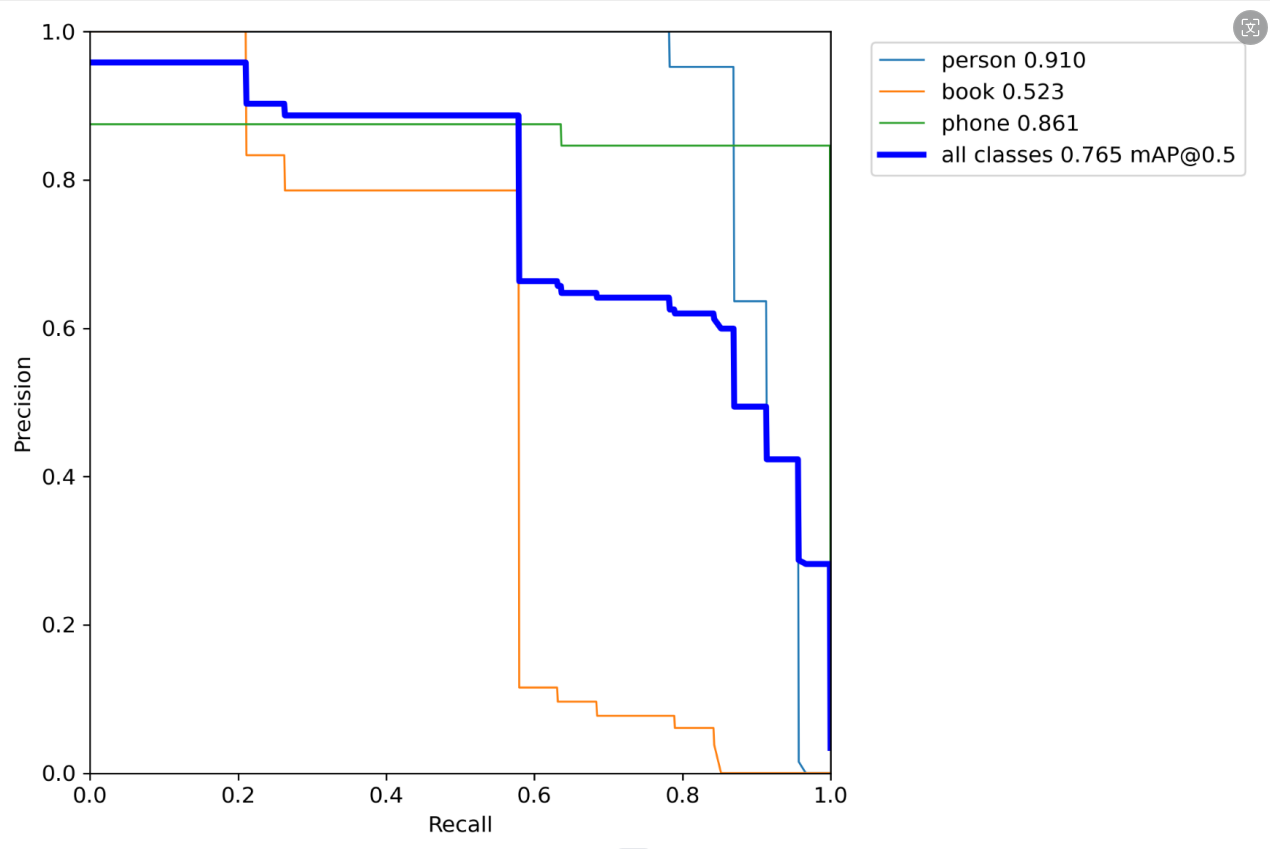
ps:PR_curve
mAP 是 Mean Average Precision 的缩写,即 均值平均精度。可以看到:精度越高,召回率越低。
但我们希望我们的网络,在准确率很高的前提下,尽可能的检测到全部的类别。所以希望我们的曲线接近(1,1)点,即希望mAP曲线的面积尽可能接近1。
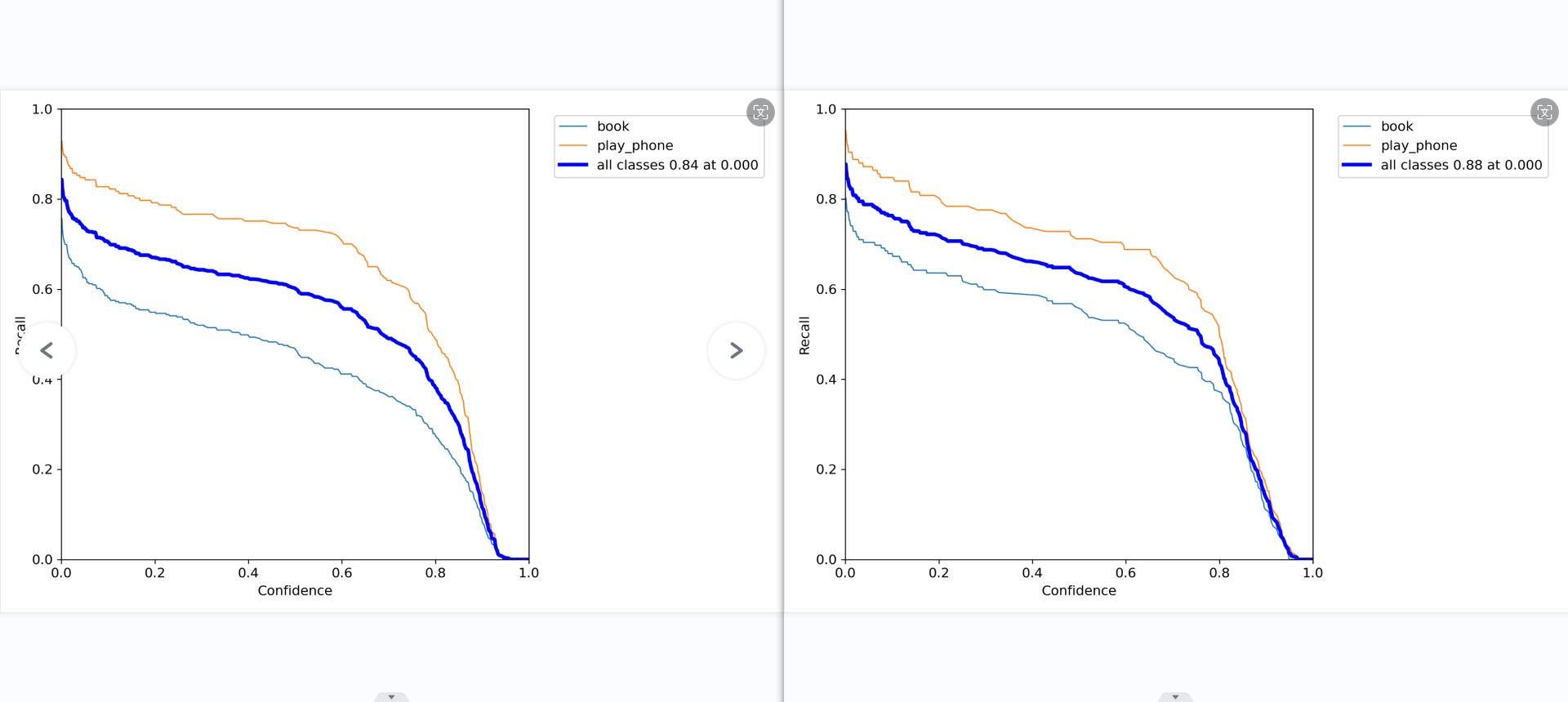
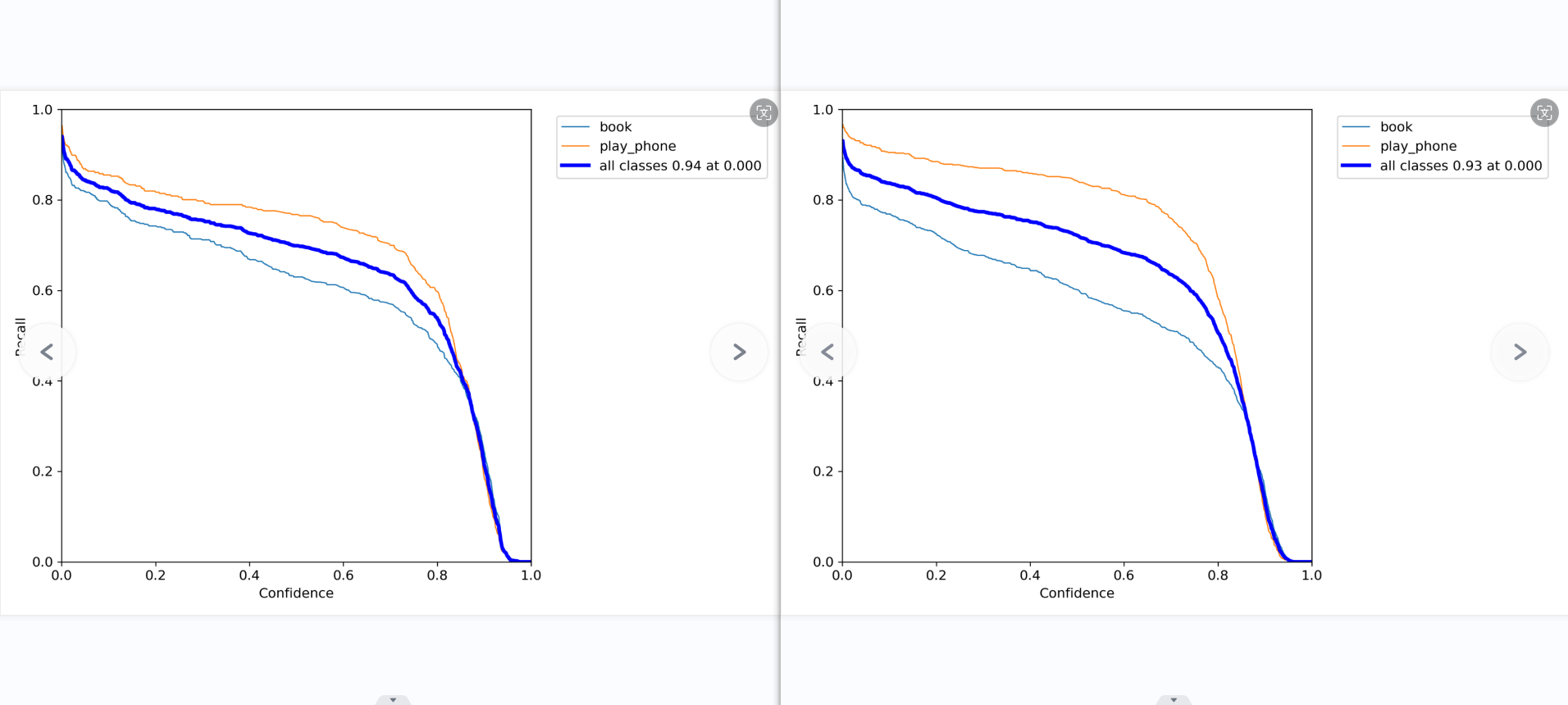
最后一张图是模型在不同置信度下的召回率曲线。可以看到对于大多数置信度区间,”使用手机”类的召回率均明显高于”书本”类。
1
2
3
R_curve
召回率(查全率)和置信度的关系图。
意思就是,当我设置置信度为某一数值的时候,各个类别查全的概率。可以看到,当置信度越小的时候,类别检测的越全面。
总的来说,该模型在检测”使用手机”类别时表现较为优异,精确率和召回率都明显高于检测”书本”类别。但在某些高置信度区间,”书本”类别的精确率也较高。根据具体应用场景的需求,可以通过调整置信度阈值来权衡精确率和召回率。
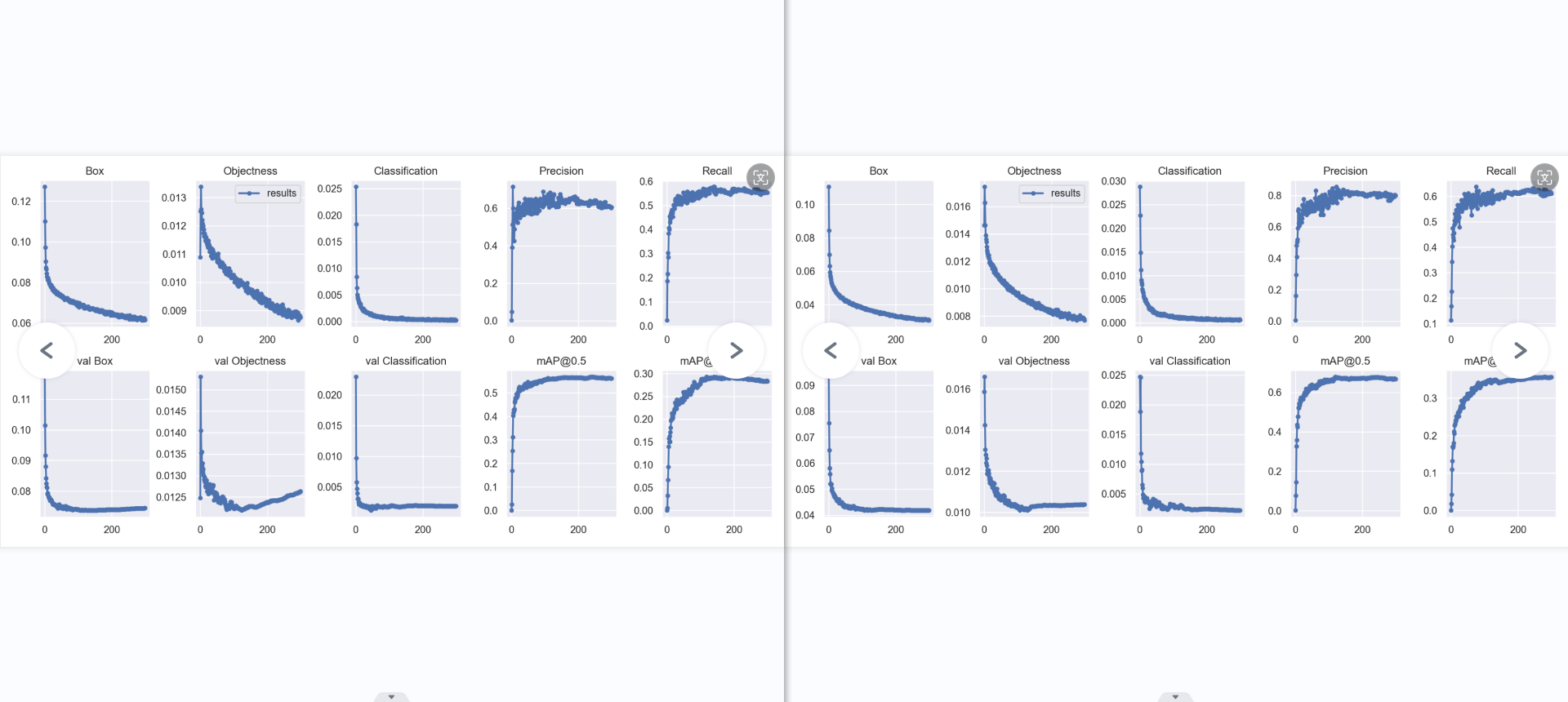
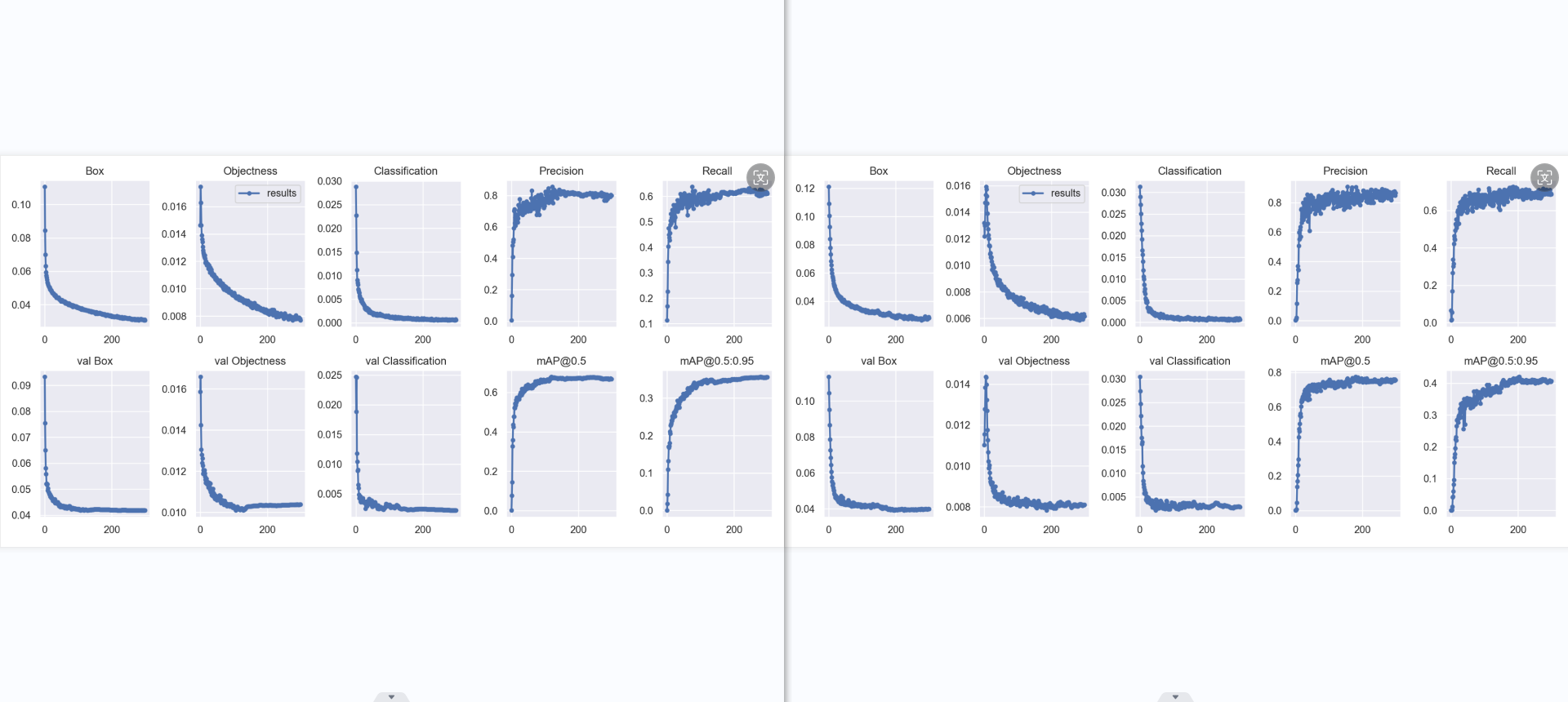
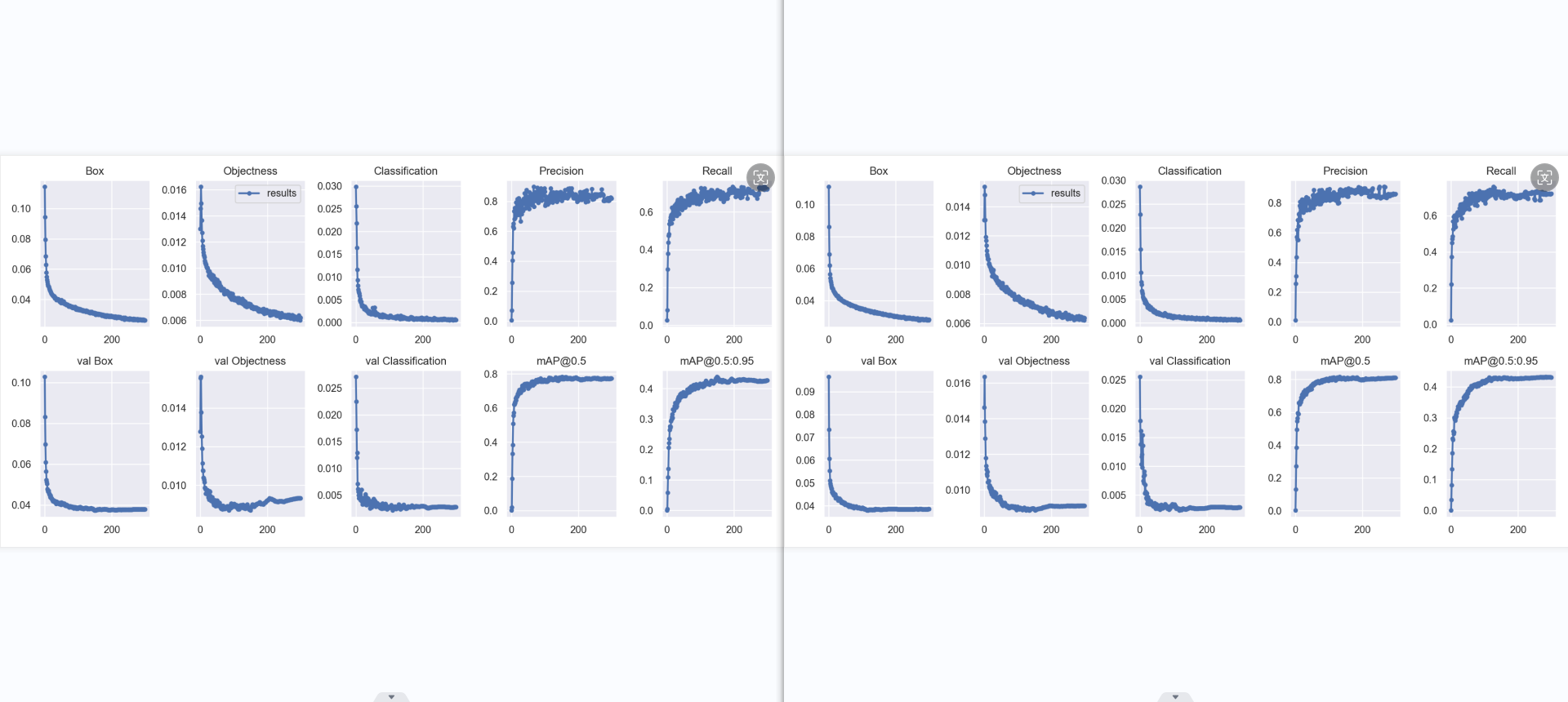
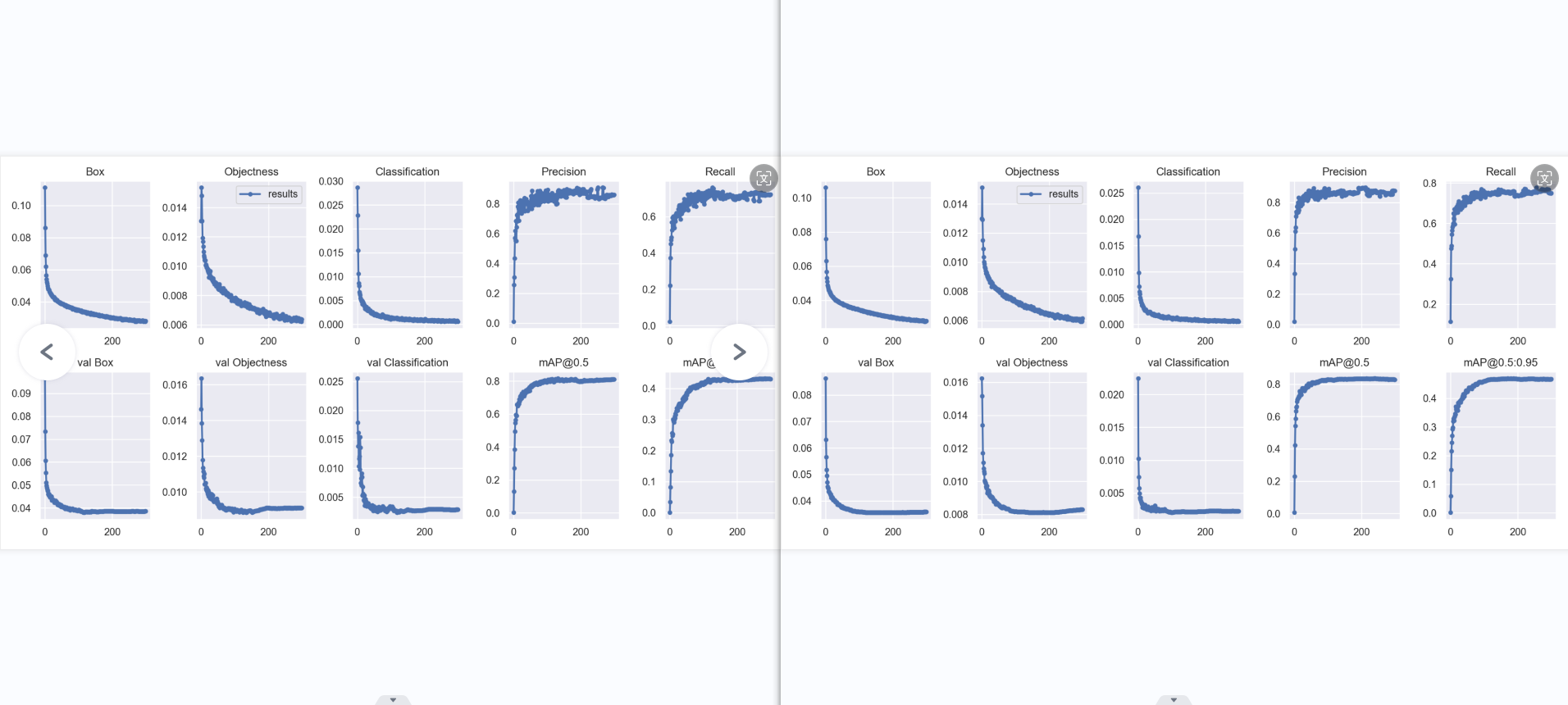
result: 横坐标为轮数(epoch),纵坐标为各类损失,越小,效果越好些。个人认为box为预测标框与标注标框偏差,obj是图片有无识别出对象偏差,cls为对象分类偏差。
引用第二个衡量指标:“宏观上一般训练结果主要观察精度和召回率波动情况,波动不是很大则训练效果较好;如果训练比较好的话图上呈现的是稳步上升。”
Box:YOLOV5使用 GIOU loss作为bounding box的损失,Box推测为GIoU损失函数均值越小,方框越准 Objectness:推测为目标检测loss均值,越小目标检测越准 Classification:推测为分类loss均值,越小分类越准
val BOX: 验证集bounding box损失 val Objectness:验证集目标检测loss均值 val classification:验证集分类loss均值
Precision:精度(找对的正类/所有找到的正类) Recall:真实为positive的准确率,即正样本有多少被找出来了(召回了多少)
mAP@0.5:0.95(mAP@[0.5:0.95]) 表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
mAP@0.5:表示阈值大于0.5的平均mAP
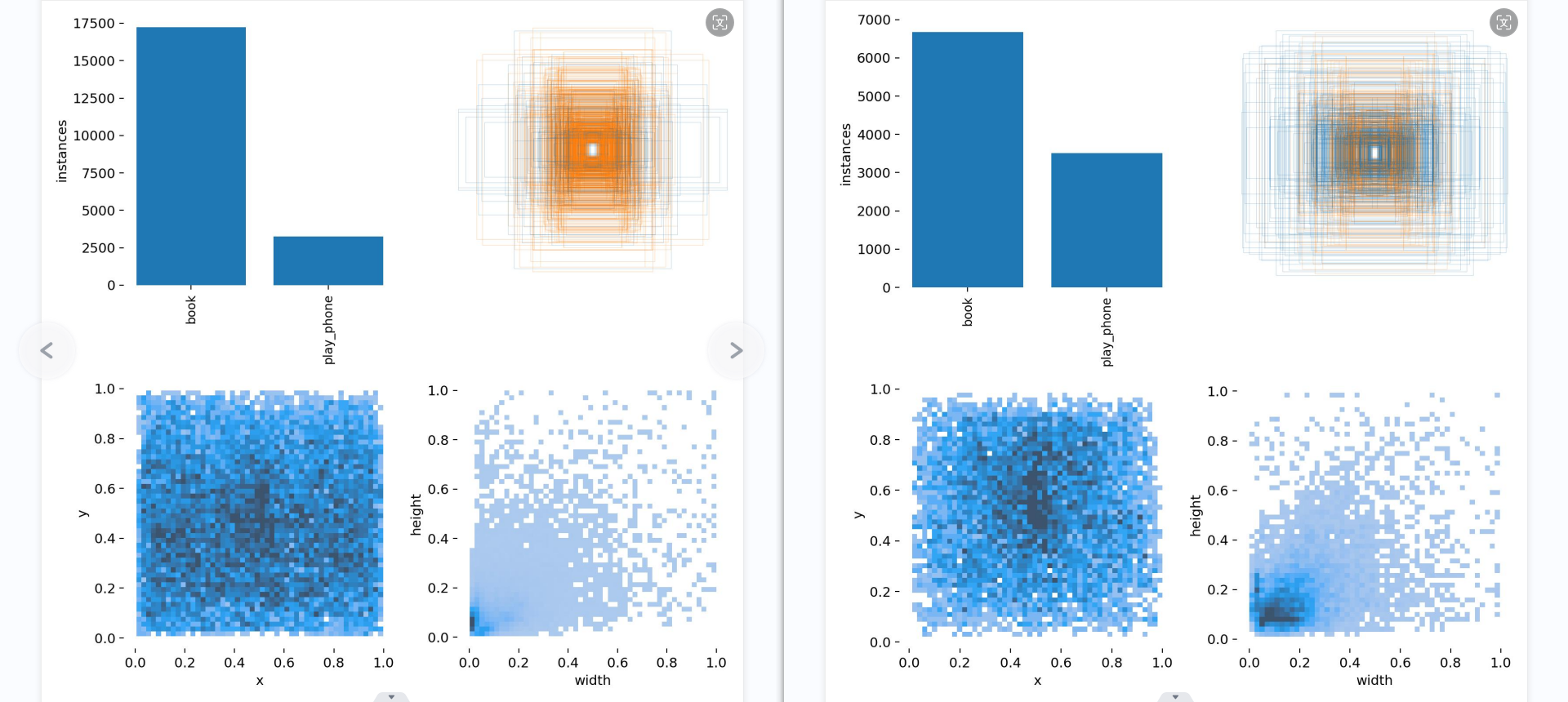
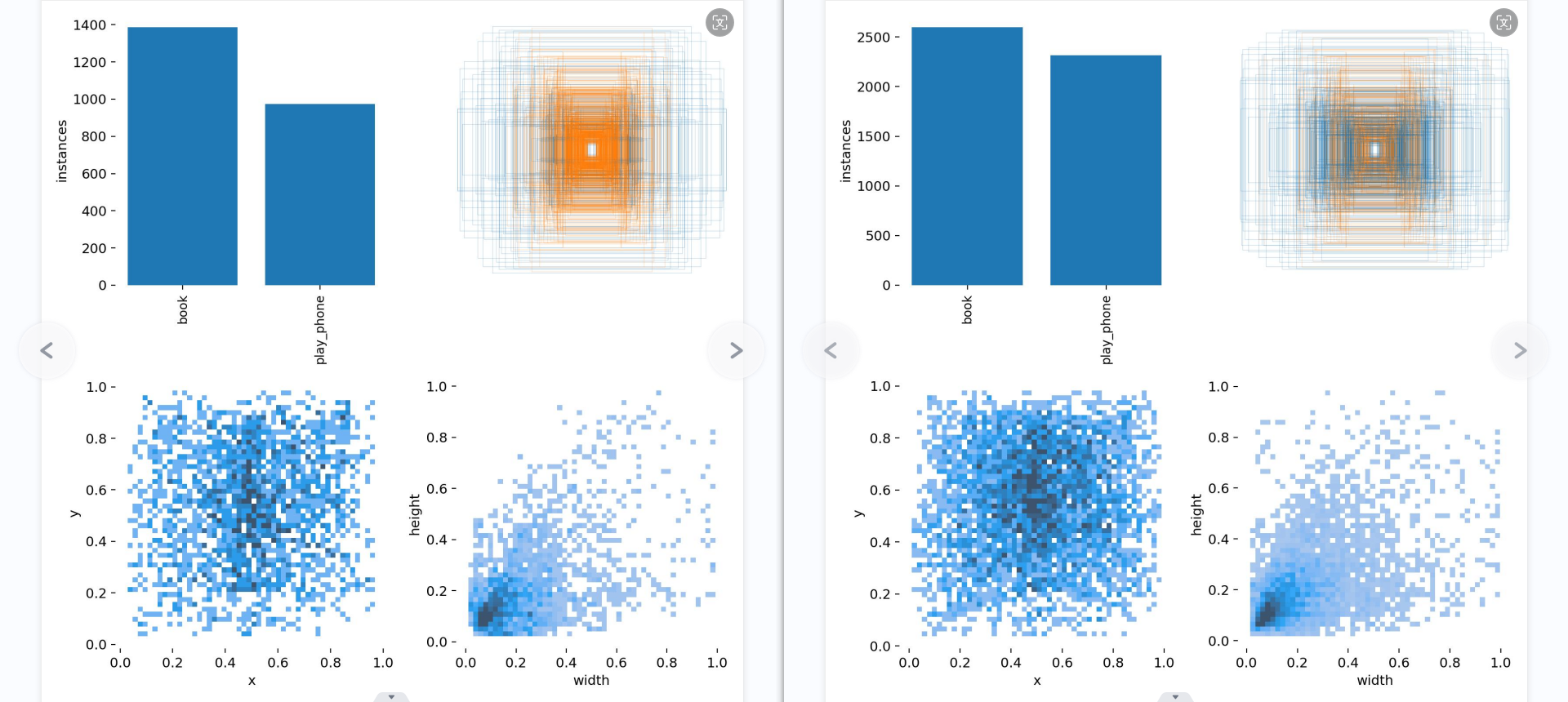
第一个图是训练集得数据量,每个类别有多少个 第二个是框的尺寸和数量 第三个是center点的位置。可以看到口罩数据集中口罩的位置大多分布在图像的中心。 第四个是labeld的高宽。口罩一般相比于整个图片比较小,所以看到样本大多分布在(0-0.2,0-0.2)。




分析: 1.数据集有问题,特别是对于书本的,由于书本在书架上的书有很多,所以标注的时候总是会遗漏,故意省略一些,这导致的影响,将“本身有书的背景”错误的识别成了书本,所以混淆矩阵书本的数据不太行。 2.不清楚是不是数据集多寡的影响,手机的识别下降了。 3.书籍的特征多会不会导致性能的下降,若是数据集书的特征就只有“打开的书”这个特征,会不会更容易得到“好”的数据。若是数据集书的特征多,包括合上的书,打开的书,书架上的书,斜放着的书,且数据集充足,会不会得到精准且实际能用,数据又好看的模型。
是不是数据集越多越好 在满足基本质量要求的前提下,适当增加数据集规模,观察模型性能的变化趋势。 密切关注训练效率、硬件资源消耗等指标,根据实际情况合理调整数据集大小。 定期评估新增数据的价值,及时剔除冗余或噪声样本,保持数据集的高质量。 尝试采用数据采样、数据增强等方法,在不增加数据量的情况下提高模型泛化能力。
总结:数据集并不是越大越好,而是以模型性能裱花趋势为基础,要求数据集质量价值足够的高,才能提高模型的泛化能力。但提高泛化能力不一定采用增加数据集这种费时间的方式,还可以使用数据采样、数据增强等方法。
总的来说,应该优先考虑提高数据集的质量,再考虑数据采样,数据增强,再接着考虑增加数据集,最后考虑调整参数。
改进: 1.在减少书本数据集(1000),减少手机数据集(1000),提高质量之后,再训练一次,比例8:1:1.(1天) 2.然后在此基础上,再各增加1000张数据集,查看情况,观察数据集对质量性能的影响。理想的话再逐步增加数据集。(1天) 3.当数据集达到各3000后(1天),开始考虑了解数据采用,数据增强。(1天)
论文改进分为7大块,每天弄一部分,此外成品也分为七大快,每天解决一个问题,7天后交论文初稿2.
1
2
问题:
我再训练一个yolov5模型,识别书本,我不确定打开的书本应该怎么标注比较好,我觉得应该将这本书都框起来,同时也应该分别用两个框吧书本书脊两侧的半部分框起来,这样会不会提取更多的有效特征
你的想法是合理的,将整本书框起来可以提供整体的视觉信息,而将书脊两侧的部分单独标注可以帮助模型学习到更多的局部特征。这种细致的标注可以帮助模型更好地理解书本的结构和外观特征,从而提高检测的准确性。在标注时,确保标注的区域尽量精确,尽量避免将其他无关的物体也框进去。此外,建议采用一致的标注规范,以便训练数据的一致性和可靠性。
这个确实,根据之前的模型,被遮挡部分一般是识别不出来的,最好遮挡了一半,也不要标注,识别一般只识别没有遮挡并且可以敲好框起来没有其他太多的东西。
1
2
问题:
有时候书本是合上斜着放的,这样标注的时候会框上很多的无关的部分,这回有什么影响吗,
标注时如果将大量无关部分框入标注框内,会导致模型学习到大量无效信息,这可能会影响其性能。因此,尽量避免将无关部分框入标注框内,保持标注的准确性和有效性对训练模型是非常重要的。
如果书本是合上斜着放的,你可以尝试调整标注的方法,以确保标注框尽可能准确地覆盖到书本区域而减少无关部分的干扰。可以尝试标注框适当地缩小,或者在斜放的情况下尽量将标注框对准书本的主体部分。同时,也可以通过调整数据增强方法,如旋转、裁剪等,来增加模型对不同角度和姿态的适应能力。
确实,图片的数据集可以只选用那些竖直摆放的书本,而不选用斜着摆放的书本,可以通过选择竖直摆放的书本来模拟斜放着的书本。
模型3(2000张)
分析: 模型3的数据明显比模型2好很多
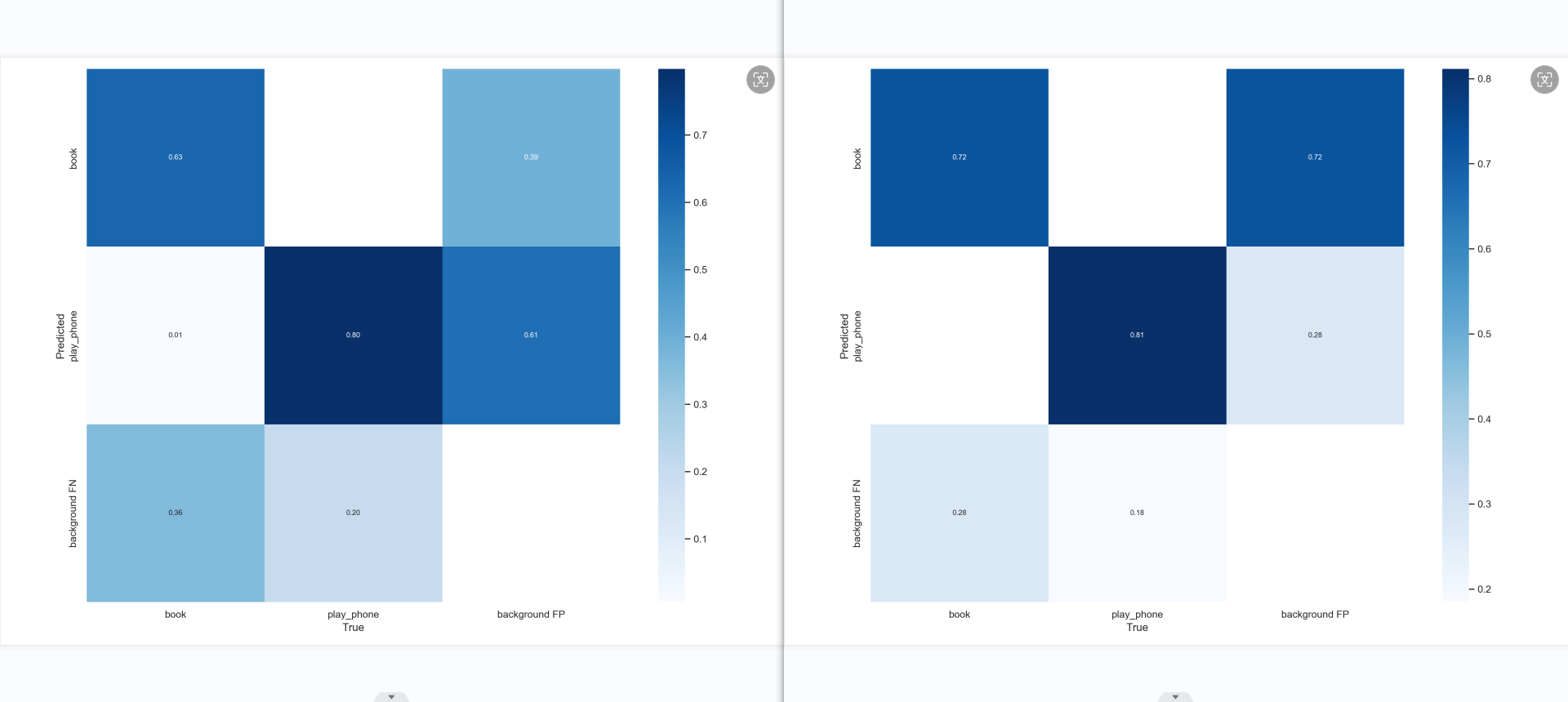
第一张混淆矩阵,书本的准确率上升了,应该是书本数据集优化的结果,但也只是堪堪过了0.6,或许是因为书本的特征比较多,有打开有合上,有翻到一半,有竖着,有倾斜,有遮挡等这些特征的影响。所以数据集得好好花时间才能做好。而手机的特征相对就没有那么多,就是手握着长方形的手机(正面、侧面)。但模型3的背景有很多被预测到了手机和书本,原因可能有二:数据集里没有放入背景图来训练模型认识什么是背景,其二是数据集不够多。
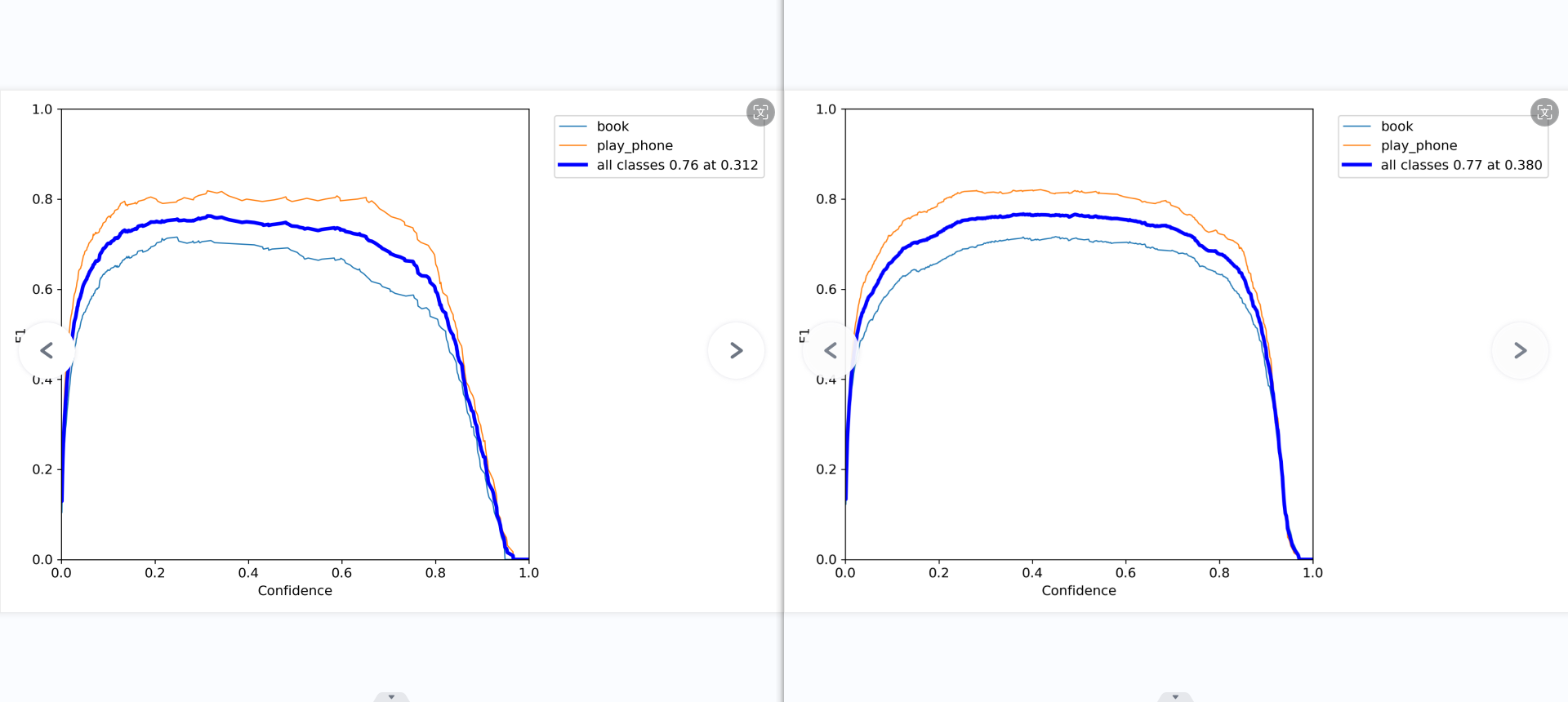
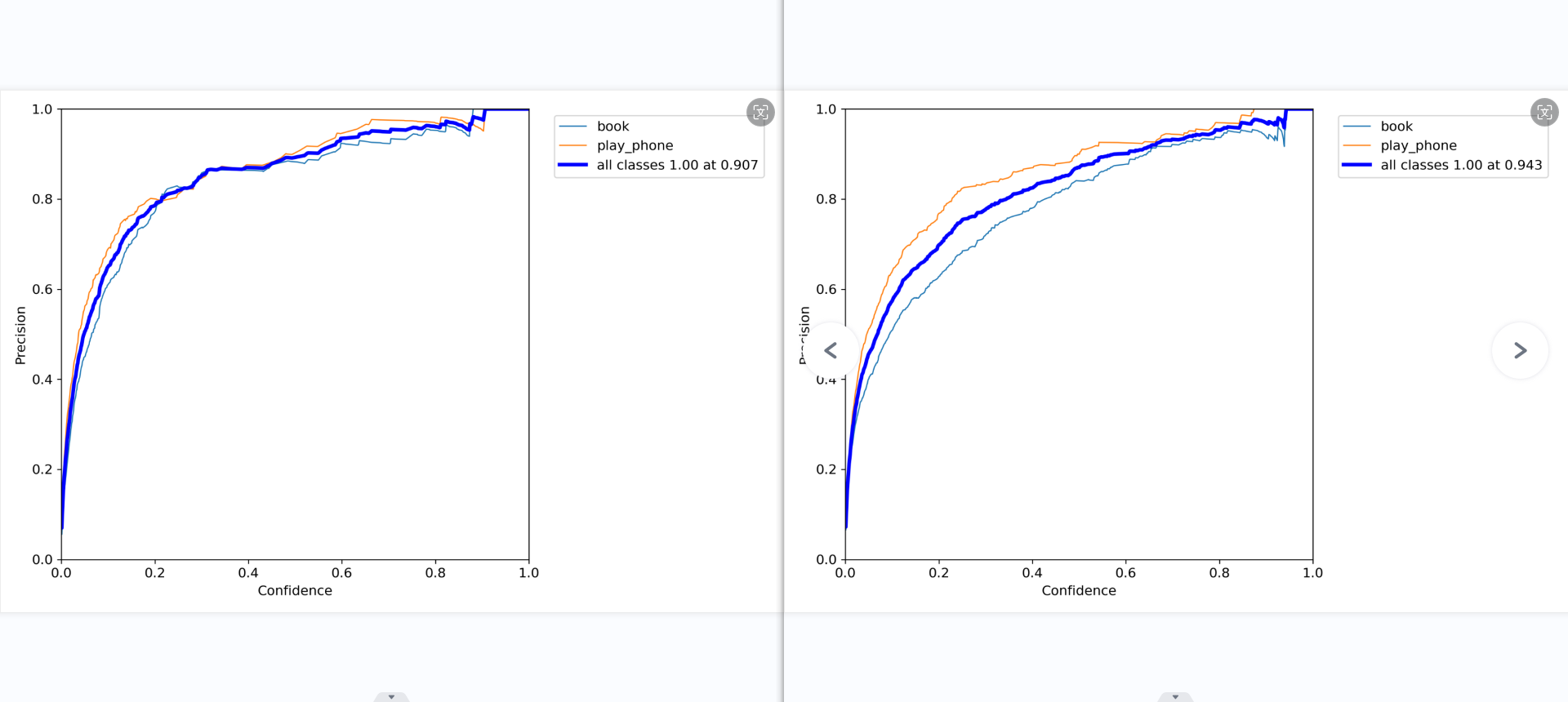
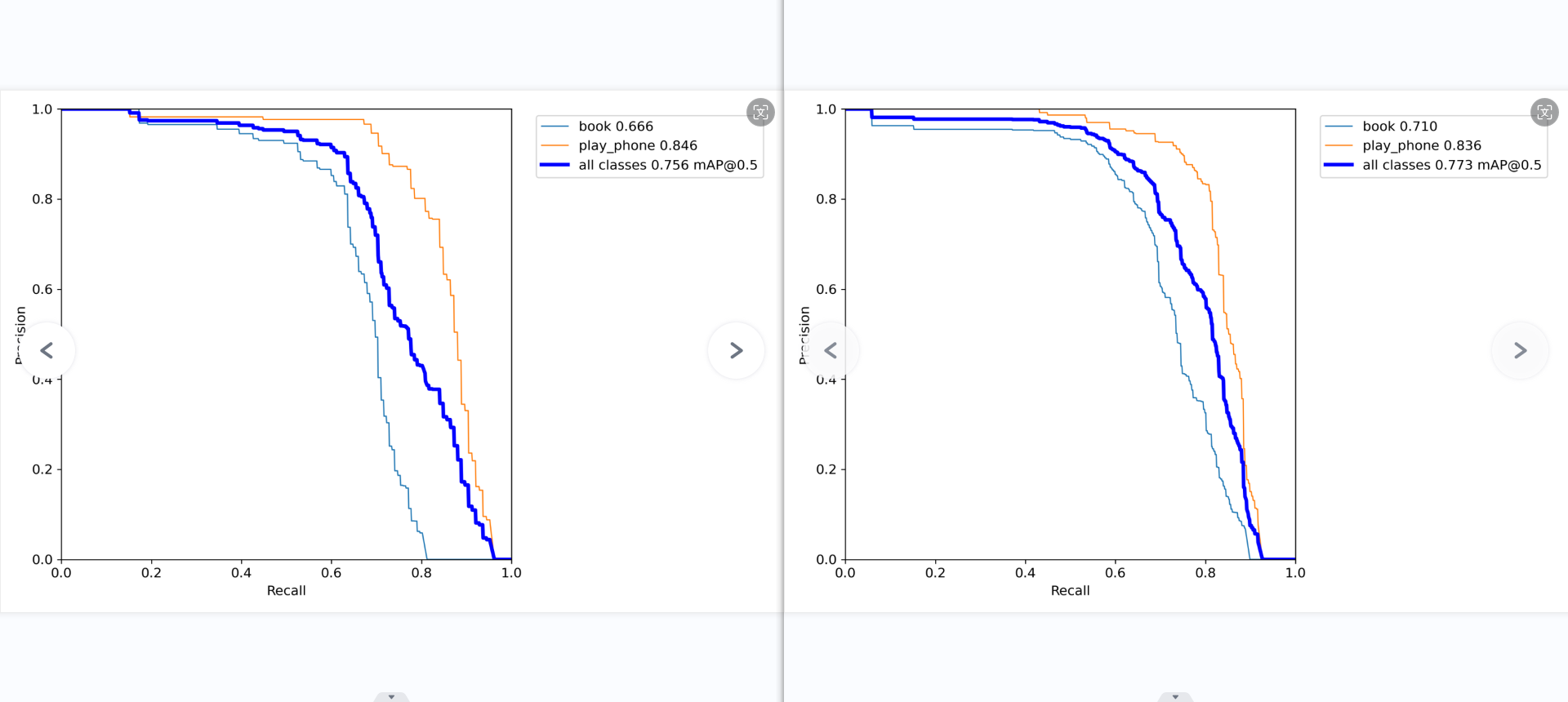
第二张图和第五张图表现了模型的综合性能有了很大的提高,从0.668提升到了0.756.
召回率和准确率的对比图中,准确率有了明显的改善,而召回率同样也是,但仍然很低,即便模型的置信度低到0,仍然有百分之20的书本数据集识别不出来,这说明这百分之20的书本的数据集的特征完全没有提取到,或许是数据集比较少的缘故。
总结: 1.剔除那些很影响训练的图片以及过于乱的书架书堆以后,模型会变好。 2.要明确书本别识别的特征应该有哪些,并相应的增加那些特征的图片。有合上,有翻开的,有翻到一半,有竖着,有倾斜,有遮挡。并且每类特征应该有充足的数量,这样图片的召回率才会升高,同时质量比较差的图片就应该舍弃,原因:难以提取到有用的特征,并且也同样难以识别,这会降低训练效果,降低召回率
改进: 1.改进数据集,删去质量低下,影响训练的数据集 2.增加“背景”数据集 2.增加1000张数据集,观察数量提升对性能,准确率,召回率的影响。
保留的书本特征:合上、翻开、翻开一半、竖着、倾斜、遮挡(质量好) 去除的书本特征:遮挡过于厉害的,背景杂乱的,难以识别的(过小过糊)、难以识别的
模型4
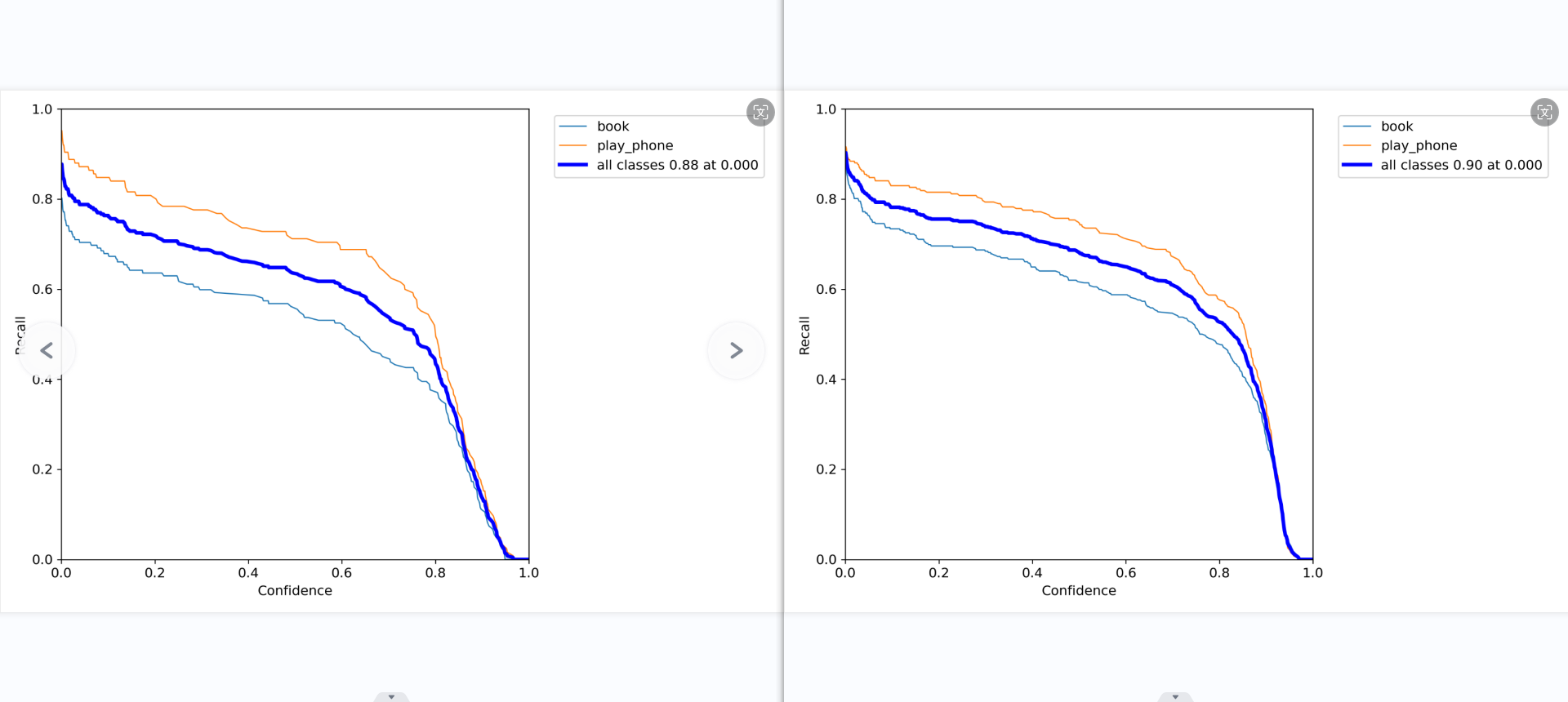
分析:模型4结果有所进展,整体的效果有了一点的提升,再准确率方面数据略有下降,可能是因为新的书本的数据集额外增加了一些斜的,竖着的特征的缘故,或许再调整以下数据集可以改善这个问题,让数据性能好一些。
手机的精确率和召回率略微降低了一点,这可能是因为背景的错误引入的缘故。背景数据集的引入并没有让模型知道哪些应该是背景,反而降低了性能,这里需要改进。
书本的召回率提升了,这应该是因为去除质量低的数据集的缘故。
改进: 1.提升4000张数据集(书、手机)的质量。(6h) 2.增加2000张数据集。(4h) 3.增加背景(2h)
模型5
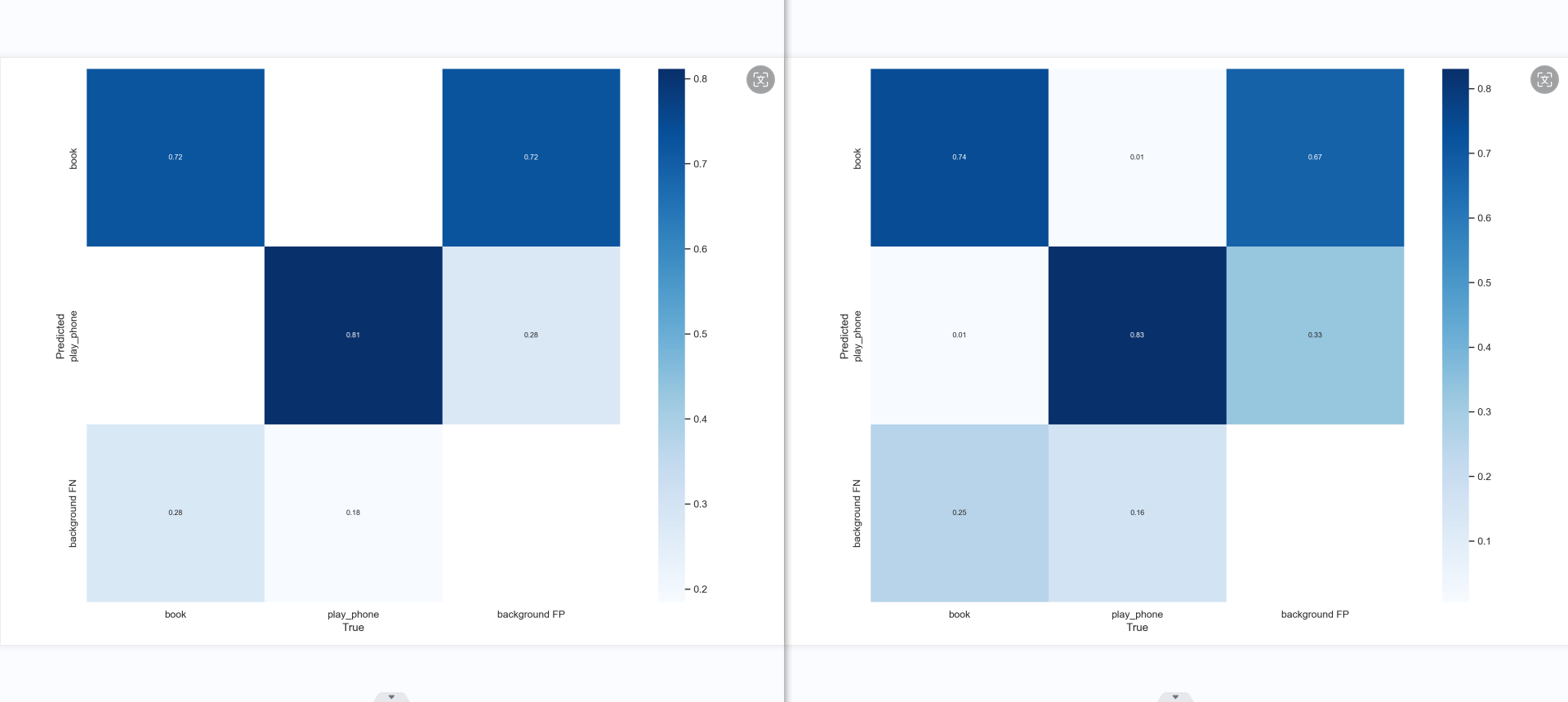
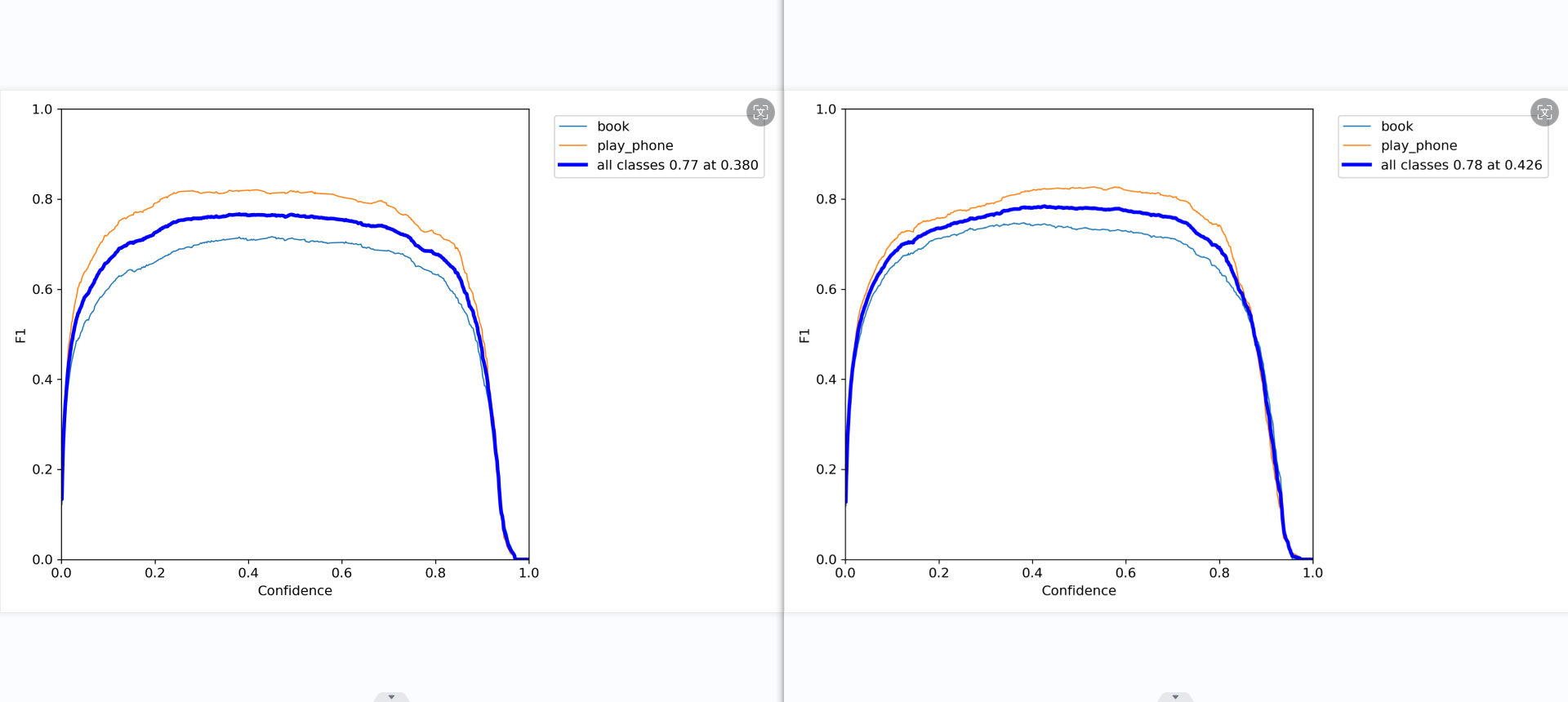
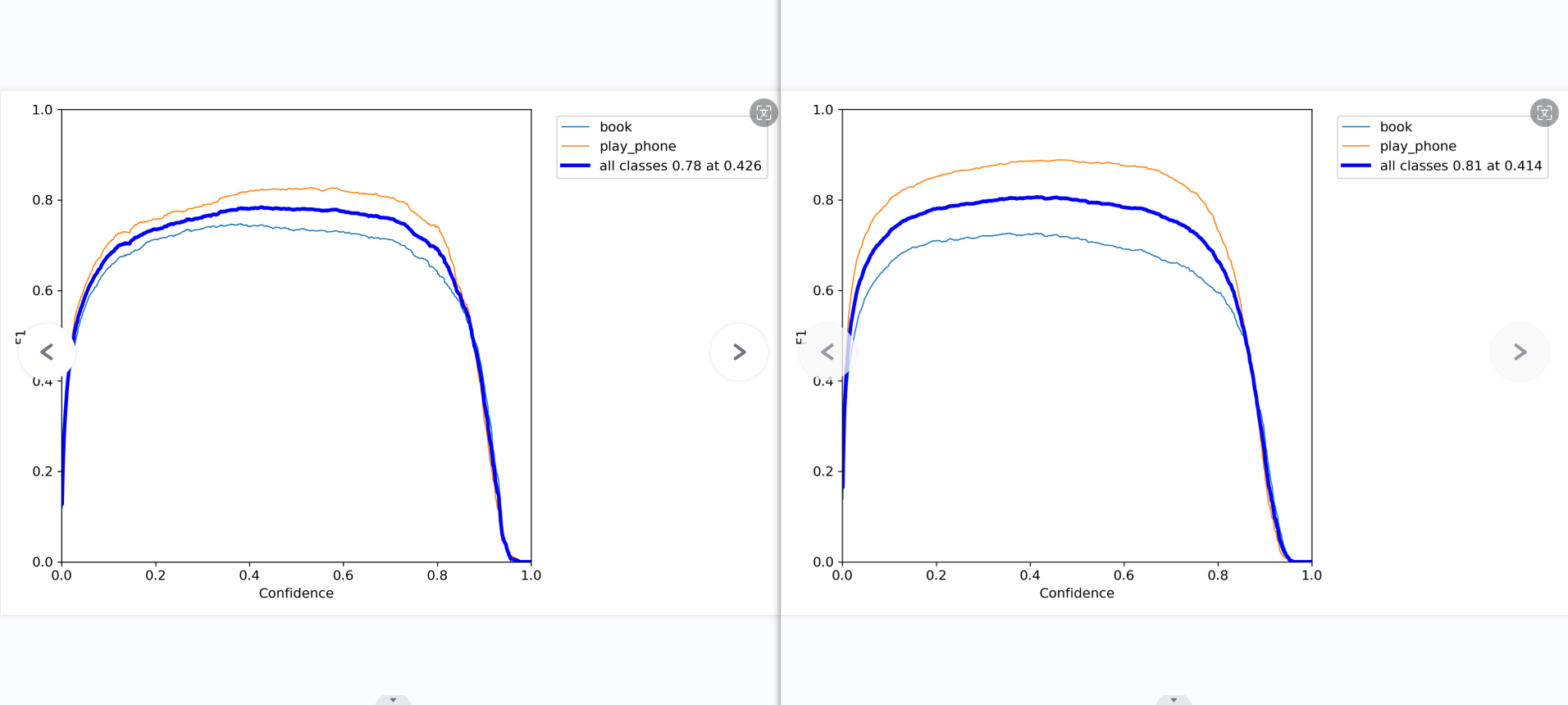
分析: 混淆矩阵、F1曲线图对比上一个模型有了一点点的进步,精确度的曲线图,书本的性能很好,稳步提升,而手机的模型略有下降,或许是数据集没有完全改好的缘故。在召回率这边,书本几乎没什么变化,但手机的曲线略微有所提升,
整体来说,书本和手机的pr曲线都只有一点的改善,但手机和书本的精确率曲线变得更稳定,更贴近了。召回率还是不太好看,可能是部分的特征没有训练好,导致那个特征的数据集没有完全被召回。混淆矩阵中的背景还是没有识别到背景哪里,可能是因为方法错了,又或许是本来就如此。查看训练的结果,发现模型对于那些小的,遮挡很高的,模糊的、容易混淆的图片抵抗力不高,极易出问题,最好是删了。总的来说,模型似乎变得更稳定了,只要提高数据质量,增加数据集数量,就可以再有效且明显的提升模型性能。这说明尚未到需要改模型,改参数,该数据增强方法的瓶颈。
结果: 1.压缩质量,提高数据集价值,删除过小,遮挡高,模糊,背景复杂,容易混淆的图片。(7h) 2.增加2000张数据集。(3h) 3.了解背景数据集。(2h) 4.整理过往的笔记文件(1h)
模型6
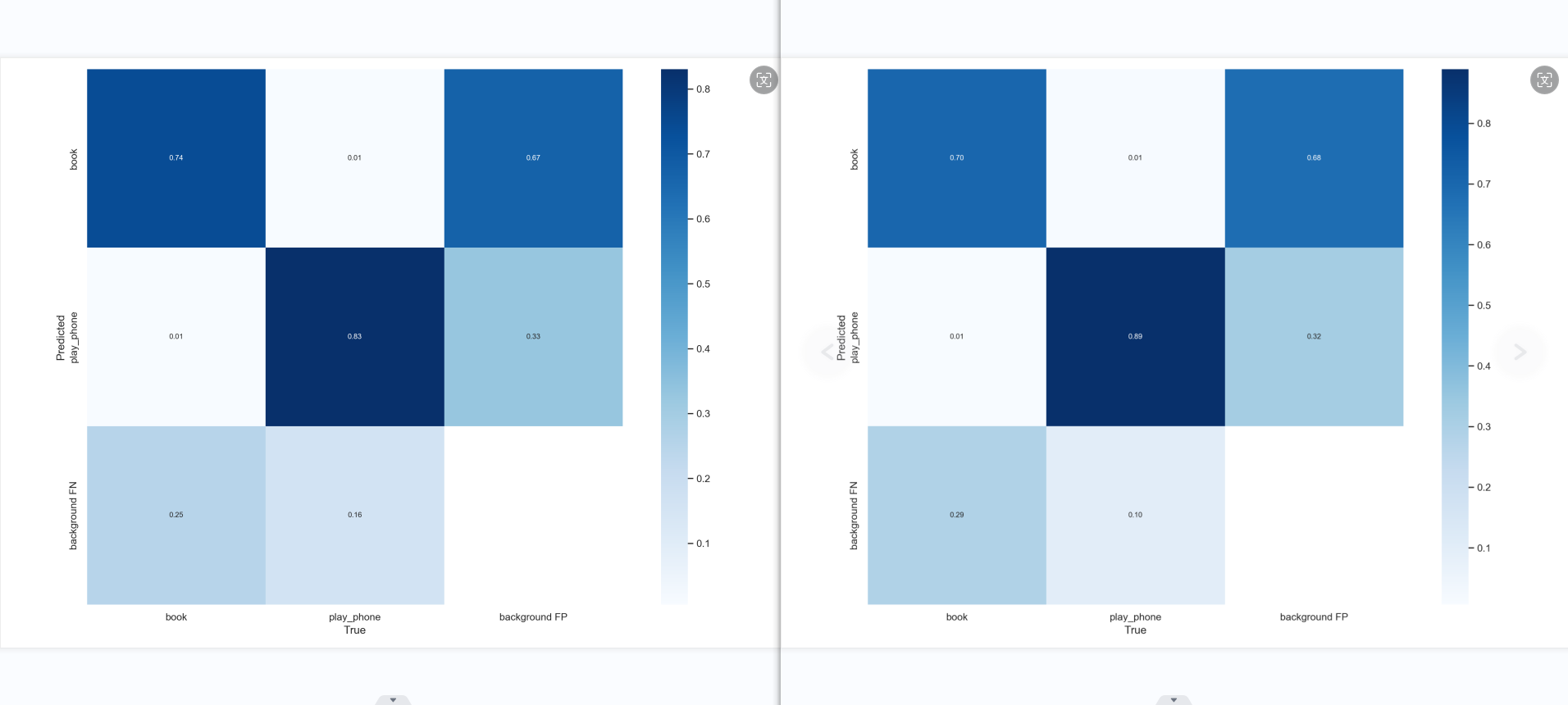
混淆矩阵对比图
模型5 书本:精确率0.521、召回率0.747、平均精度率0.771mAP、F1分数0.615 手机:精确率0.716、召回率83.8、平均精确率0.850mAP、F1分数0.772
模型6…
搞错了,不能直接通过混淆矩阵计算出精确率,因为该混淆矩阵是归一化后的,不清楚确切的数值。 修改项目下utils的metrics.py中的plot
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def plot(self, save_dir='', names=()):
try:
import seaborn as sn
# 使用混淆矩阵的原始值而不进行归一化
array = self.matrix.copy()
array[array < 0.005] = np.nan # 不显示太小的值(会显示为0.00)
fig = plt.figure(figsize=(12, 9), tight_layout=True)
sn.set(font_scale=1.0 if self.nc < 50 else 0.8) # 根据类别数量调整标签大小
labels = (0 < len(names) < 99) and len(names) == self.nc # 如果提供了名称,则应用于刻度标签
sn.heatmap(array, annot=self.nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True,
xticklabels=names + ['background FP'] if labels else "auto",
yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
fig.axes[0].set_xlabel('True')
fig.axes[0].set_ylabel('Predicted')
fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
except Exception as e:
pass
接着即可输出没有归一化的混淆矩阵,所以得到
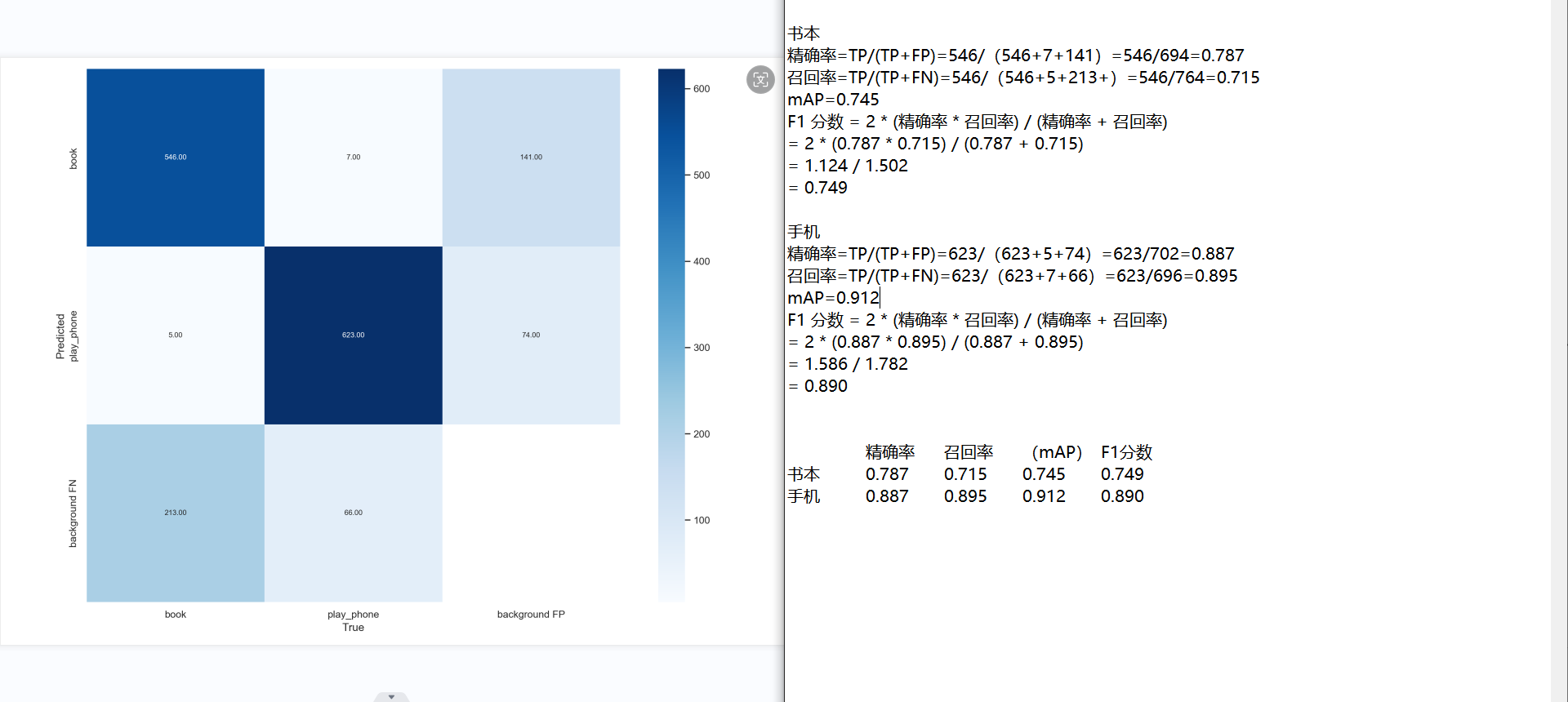






总体的模糊感受,手机性能有了极大的提升,与预想的一样,应该是数据集数量提升的结果。但书本的性能下降,应该是书柜,杂乱,模糊,密集的书本数据集的混入导致的性能下降结果,需要去除掉。